
Cascading Failures: Detection and Prevention
Issue #120: System Design Interview Roadmap • Section 5: Reliability & Resilience

When One Domino Takes Down the Empire
Amazon's 2017 S3 outage wasn't just about storage—it triggered a cascade that brought down half the internet. Status pages couldn't load (they used S3), monitoring systems went dark (metrics stored in S3), and even smart doorbells stopped working. One typo in a maintenance command created a billion-dollar domino effect.
Today's learning agenda:
Understanding cascade propagation mechanics
Real-time failure detection patterns
Circuit breaker implementation strategies
Bulkhead isolation techniques
Production-grade prevention systems
The Anatomy of Cascading Failures
Cascading failures occur when the failure of one component triggers failures in dependent components, creating a chain reaction. Unlike simple component failures, cascades amplify exponentially—each failed service puts additional load on surviving services, often pushing them beyond their capacity limits.
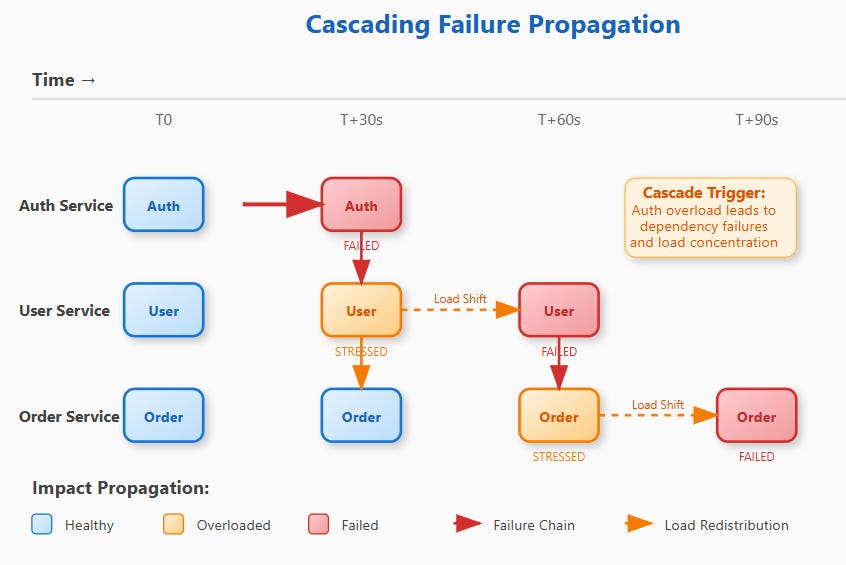
The cascade mechanism follows predictable patterns:
Overload Propagation: Service A fails, its traffic redirects to Service B, overwhelming B's capacity and causing it to fail, redirecting traffic to Service C.
Resource Exhaustion: Database connection pools fill up when services can't complete transactions, causing healthy services to fail when they can't get connections.
Dependency Amplification: Authentication service fails, causing all dependent services to reject requests, appearing as widespread service failures.