Chaos Engineering Implementation Strategies
Introduction
Your payment service just went down at 2 AM. The root cause? A dependency you didn’t know was critical started returning errors, and your entire system collapsed. What if you could have discovered this vulnerability during business hours, in a controlled environment, before customers were affected?
What Is Chaos Engineering?
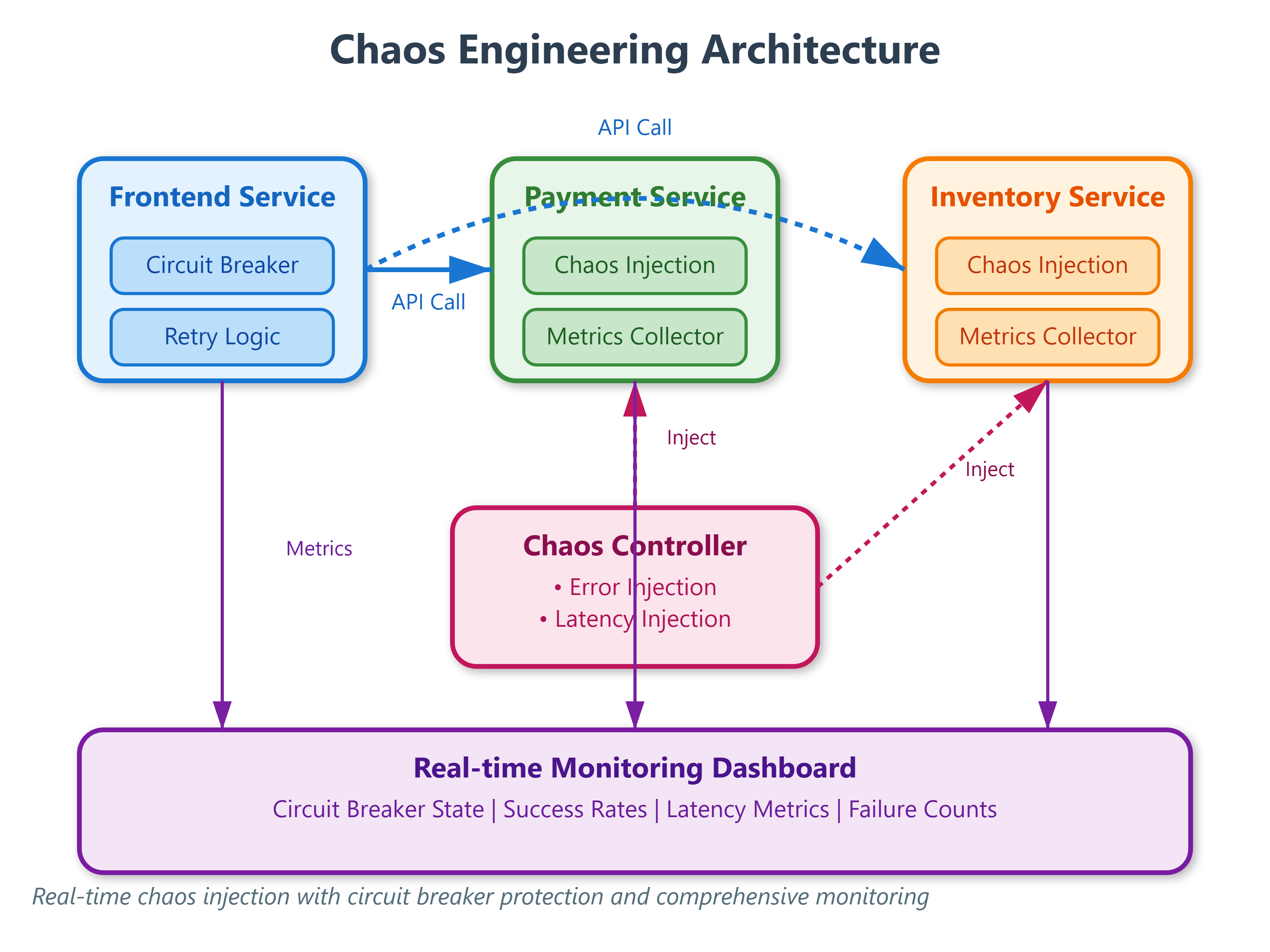
Chaos engineering is the discipline of experimenting on distributed systems to build confidence in their ability to withstand turbulent conditions. Unlike traditional testing that validates what you think should work, chaos engineering discovers what actually breaks your system under realistic failure conditions.
The practice originated at Netflix in 2011 with Chaos Monkey, a tool that randomly terminates production instances. The counterintuitive insight: by deliberately breaking things in controlled ways, you force systems to evolve resilience mechanisms. Your system becomes antifragile—it actually improves from stress rather than merely tolerating it.
The fundamental approach involves four steps: First, define “steady state” as measurable output indicating normal behavior (request success rate, latency percentiles, business metrics). Second, hypothesize that steady state will continue in both control and experimental groups. Third, introduce real-world failure variables like server crashes, network partitions, or resource exhaustion. Fourth, disprove your hypothesis by finding differences between control and experiment groups.
The key distinction from traditional testing: chaos engineering treats the entire system as a black box. You don’t examine internal state or validate individual components. Instead, you observe system-wide behavior under failure conditions, discovering emergent properties that unit tests can’t reveal. When your database connection pool exhausts at 3,000 QPS but works perfectly at 2,000 QPS, that’s an emergent property only chaos can expose.