Checkpoint and Rollback Recovery
Issue #137: System Design Interview Roadmap • Section 5: Reliability & Resilience

When Your Database Crashes at 3 AM
Imagine you're running a financial trading system processing millions of transactions when a power surge hits your data center. Without checkpoint and rollback recovery, those in-flight transactions vanish into digital oblivion, potentially costing millions. This scenario played out at Knight Capital in 2012, where a failed deployment without proper rollback mechanisms led to $440 million in losses in just 45 minutes.
Today, we'll master checkpoint and rollback recovery—the safety net that lets systems bounce back from failures as if they never happened.
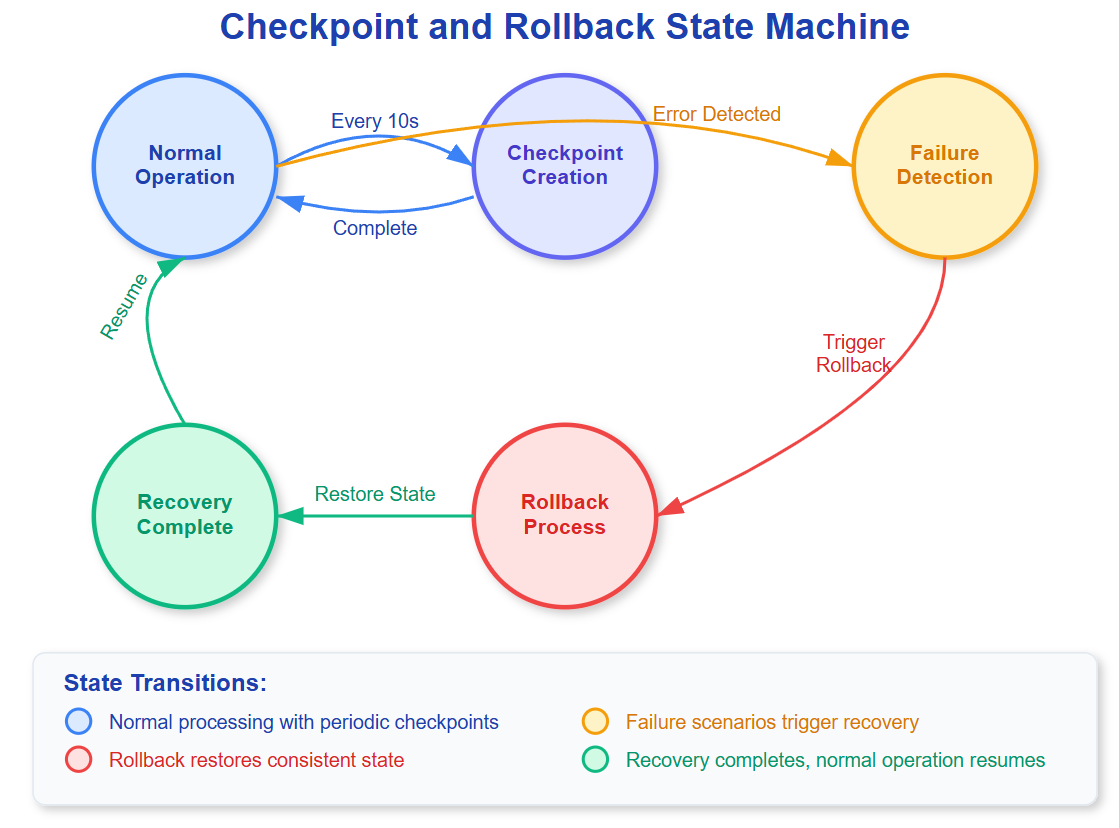
What We'll Master Today
Checkpoint mechanisms that capture consistent system states
Rollback strategies for different failure scenarios
Recovery protocols that minimize data loss and downtime
Implementation patterns used by Netflix, Google, and financial institutions
The Hidden Art of State Preservation
Checkpoint and rollback recovery isn't just about saving data—it's about capturing a consistent snapshot of your entire system state at a specific moment, then rewinding time when things go wrong.
Think of it as creating save points in a video game, but for distributed systems handling real money and critical data.
The Consistency Challenge
The hardest part isn't saving state—it's ensuring all components reach the checkpoint simultaneously. In distributed systems, this requires coordinating across networks with unpredictable delays.