
Consistency Models in Distributed Systems: Balancing Truth in a Divided World
System Design Interview Roadmap: Newsletter #16
Welcome back, fellow system architects! Last week we explored load balancing strategies for high-throughput APIs. Today, we're diving into what might be the most intellectually challenging aspect of distributed systems: consistency models.
As our systems scale to handle millions of requests per second, we inevitably face a fundamental dilemma: how do we ensure all nodes in our distributed system share the same view of reality?
Let's explore consistency models through practical examples and visualizations that make these abstract concepts concrete.
Understanding Consistency in Distributed Systems
Consistency in distributed systems refers to how and when updates made to data become visible to different parts of the system. It's about answering a seemingly simple question: "If I write data here, when and how will it be readable elsewhere?"
Consistency Model Spectrum
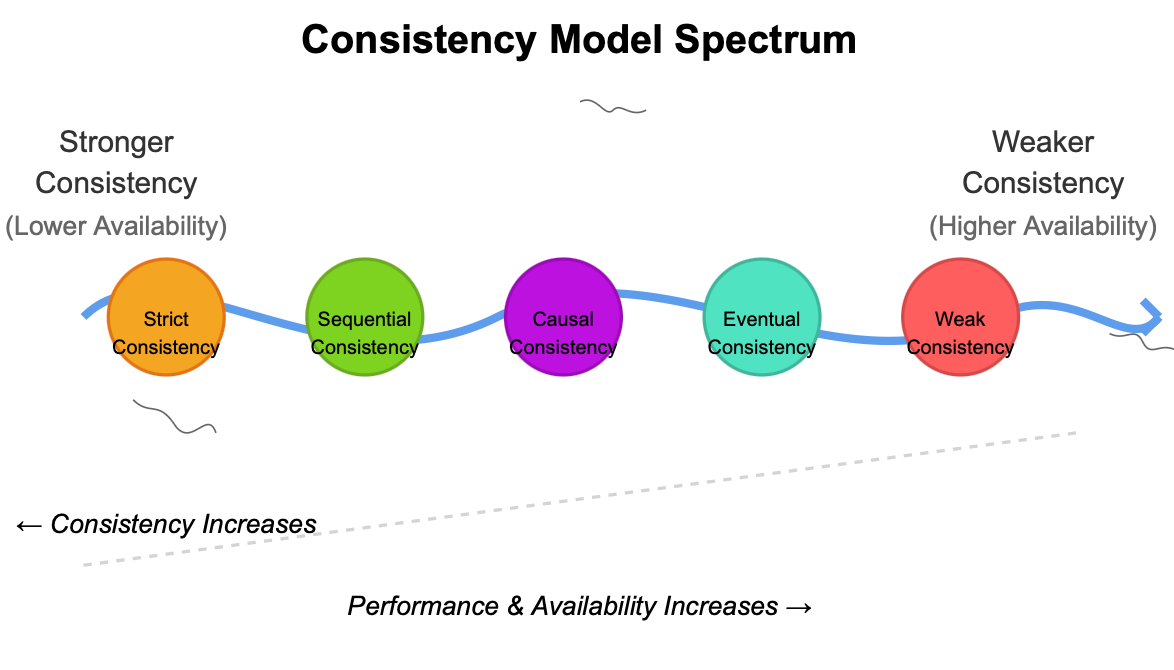
The spectrum above illustrates the trade-offs we make between consistency and availability. As we move from left to right, we gain performance and availability but sacrifice consistency. Let's explore each model:
Strong Consistency Models
Strict Consistency (Linearizability)
This is the gold standard, where any read operation returns the most recent write, regardless of which node performs the operation. It's as if all operations happen atomically on a single node.
Strict Consistency
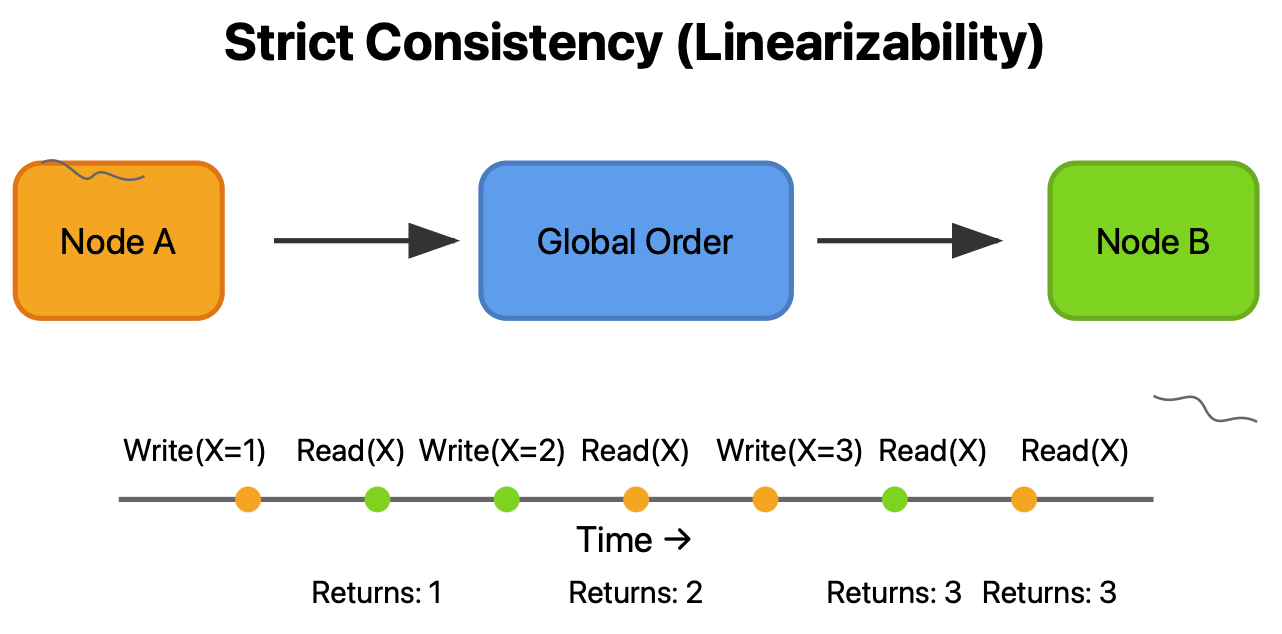
Real-world use case: Financial transactions where every penny must be accounted for. Google's Spanner database uses TrueTime API to achieve this.
Trade-offs: Achieving strict consistency typically requires:
Performance penalties due to synchronization
Limited availability during network partitions (CAP theorem in action)
Sequential Consistency
Sequential consistency guarantees that all operations appear to execute in some sequential order, and operations from each node appear in the order they were issued. However, unlike strict consistency, there's no real-time constraint between operations from different nodes.
Causal Consistency
Weaker Consistency Models
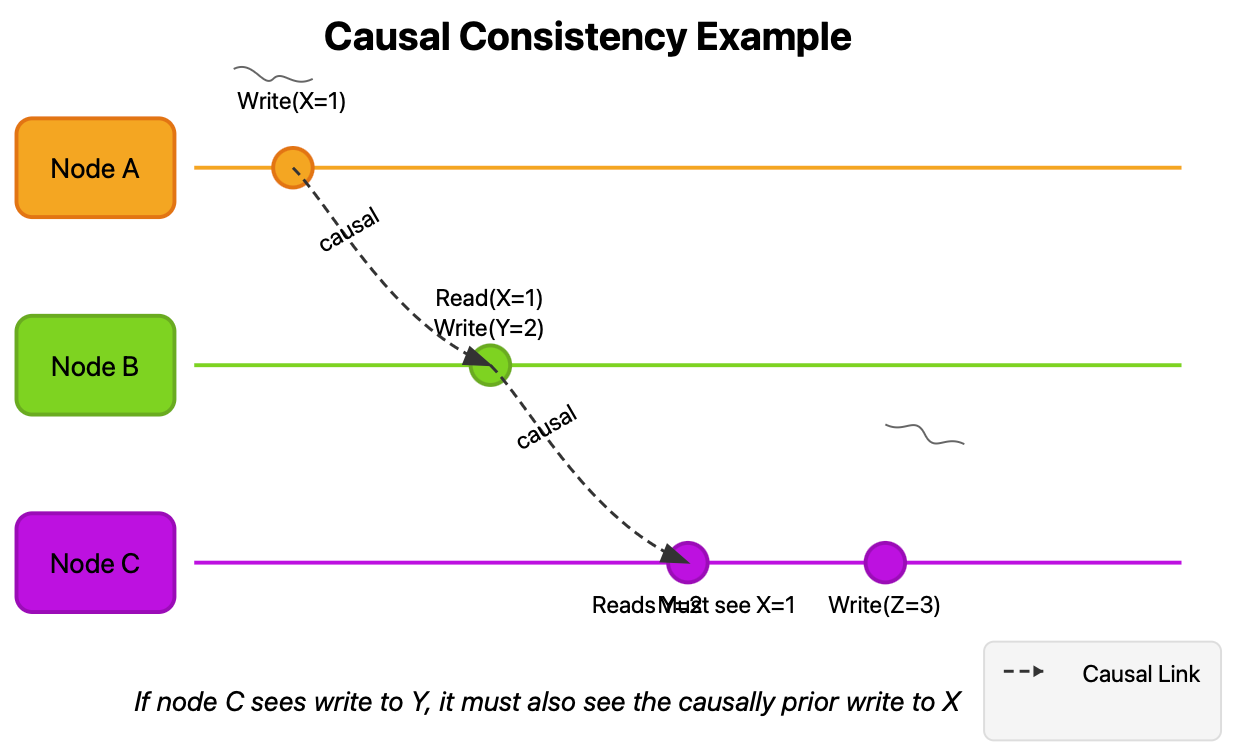
Causal Consistency
Causal consistency ensures that operations that are causally related are seen by all nodes in the same order. Operations with no causal relationship (concurrent operations) may be seen in different orders on different nodes.
The diagram above illustrates a scenario where:
Node A writes X=1
Node B reads X=1 and then writes Y=2 (causally dependent on reading X)
Node C reads Y=2, which means it must also see X=1 to maintain causal consistency
Real-world use case: Social media platforms where comment threads need to appear in causal order (replies appearing after the original post).
Eventual Consistency
Eventual Consistency
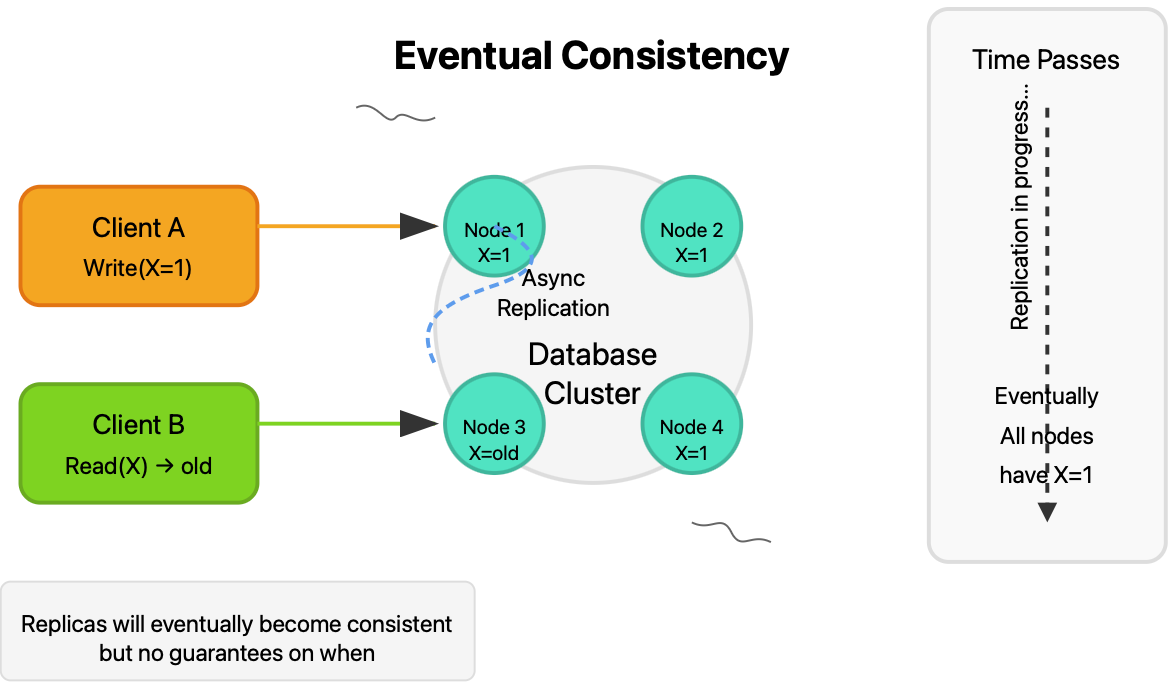
Eventual consistency guarantees that if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. There are no guarantees about when this will happen, just that it eventually will.
Real-world use case: Amazon DynamoDB, Cassandra, and most NoSQL databases favor this model. It's perfect for:
Product catalogs where slight inconsistencies are acceptable
Social media non-critical data like follower counts
Content delivery networks (CDNs)
Real-World Implementations
Real-World Implementations
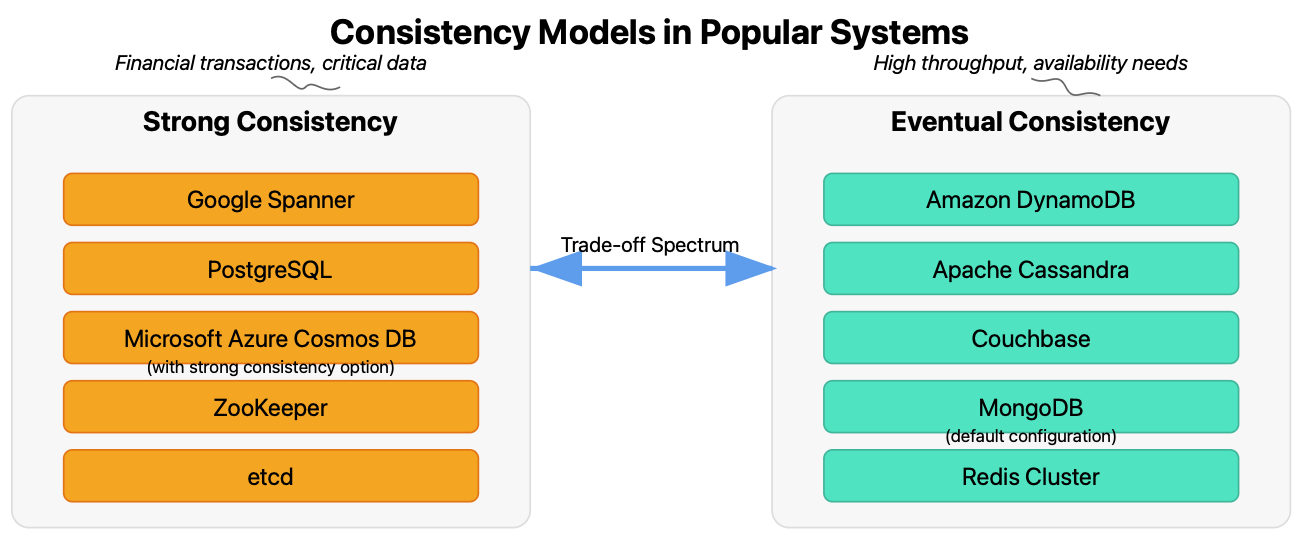
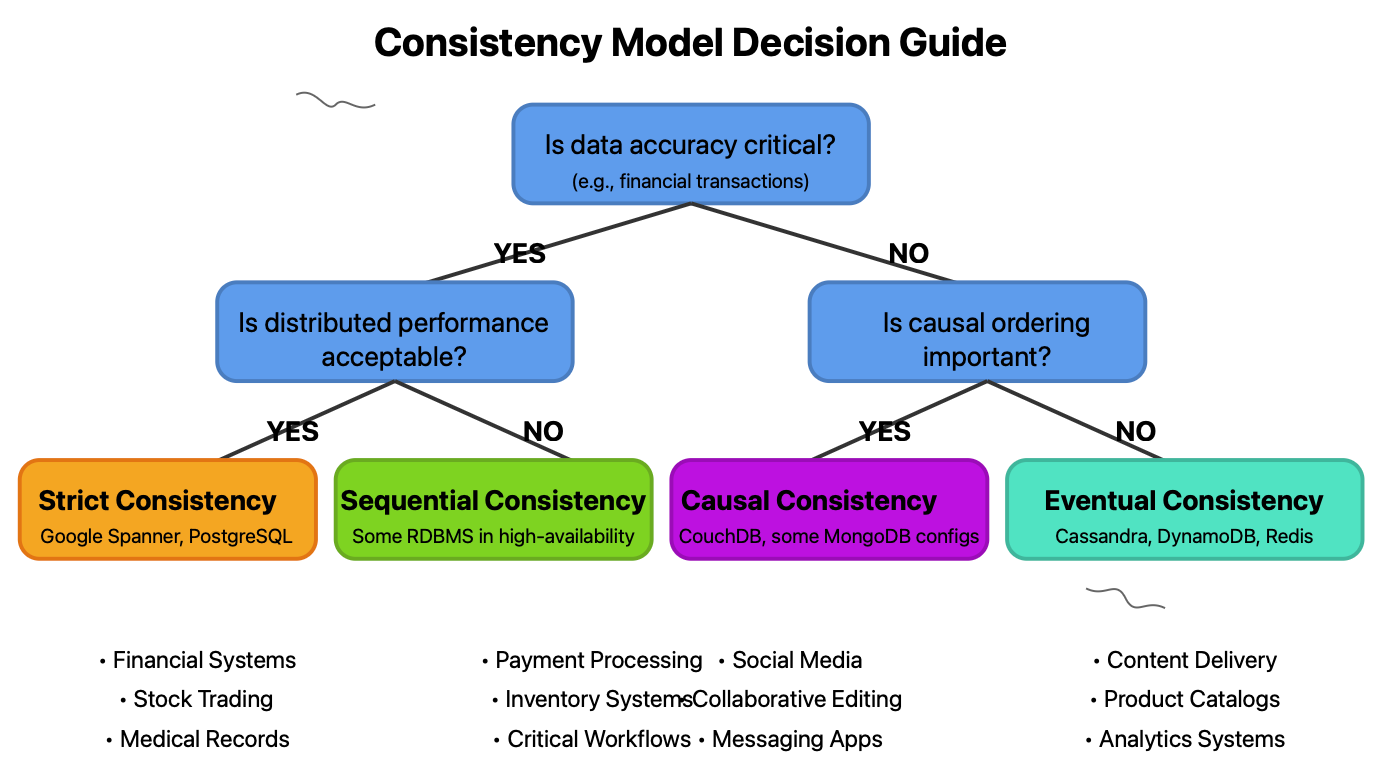
Selecting the Right Consistency Model
The right consistency model depends on your specific application requirements. Let's explore some common scenarios:
Consistency Model Decision Tree
Implementation Strategies
Implementing different consistency models often requires specific approaches:
For Strong Consistency
Use consensus algorithms like Paxos or Raft
Implement two-phase commit (2PC) for distributed transactions
Consider the performance impact of synchronous operations
For Eventual Consistency
Use vector clocks or logical timestamps to track updates
Implement conflict resolution strategies (Last-Writer-Wins, CRDTs)
Design your application to handle temporary inconsistencies gracefully
Common Challenges and Solutions
Network Partitions: Network partitions are inevitable in distributed systems. The CAP theorem tells us we must choose between consistency and availability when partitions occur.
Solution: Choose consistency models appropriate for your use case, and consider using different models for different data types.
Data Conflicts: In eventual consistency models, conflicts are inevitable.
Solution: Implement Conflict-free Replicated Data Types (CRDTs) or custom conflict resolution mechanisms.
Stale Reads: Clients may read stale data in weaker consistency models.
Solution: Implement read-your-writes consistency by directing reads to nodes that processed the writes.
Conclusion
Choosing the right consistency model is a critical architectural decision that affects your system's scalability, availability, and correctness. The best approach is often to use different consistency models for different parts of your system based on their specific requirements.
Remember:
Strong consistency is necessary for financial and critical data
Causal consistency works well for social and collaborative applications
Eventual consistency provides high availability and performance for less critical data
In the next newsletter, we'll explore how to implement these consistency models in microservice architectures and how to design systems that maintain consistency across service boundaries.
Until then, happy designing!
P.S. Did you struggle with implementing any particular consistency model in your systems? Share your experiences in our community forum, and I'll address common challenges in a future deep-dive article.