
CRDTs vs. Operational Transformation: How Google Docs Handles Collaborative Editing
The Millisecond Race You Never See
You’re editing a sentence. Your colleague in Tokyo deletes the same word. Another teammate in London adds a paragraph. All within 50 milliseconds. When you press save, what text should survive? This isn’t a hypothetical—it happens millions of times daily in Google Docs, Figma, and Notion. The magic isn’t preventing conflicts; it’s making them invisible.
Two competing philosophies dominate this space: Operational Transformation (OT) and Conflict-free Replicated Data Types (CRDTs). Google Docs uses OT. Figma switched from OT to CRDTs. Both solve the same problem differently, and understanding why reveals fundamental trade-offs in distributed systems that apply far beyond text editors.
Two Philosophies for One Problem
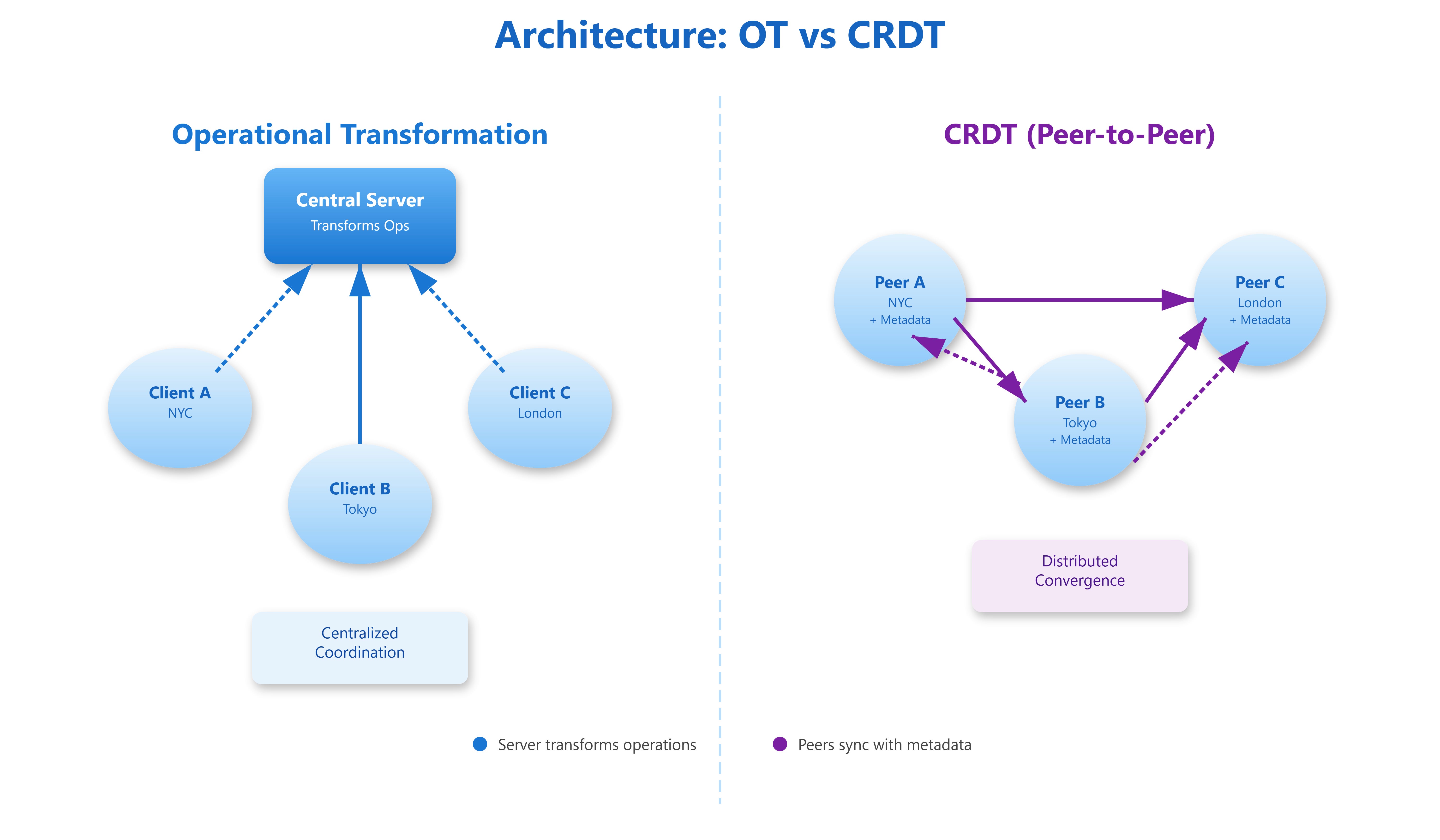
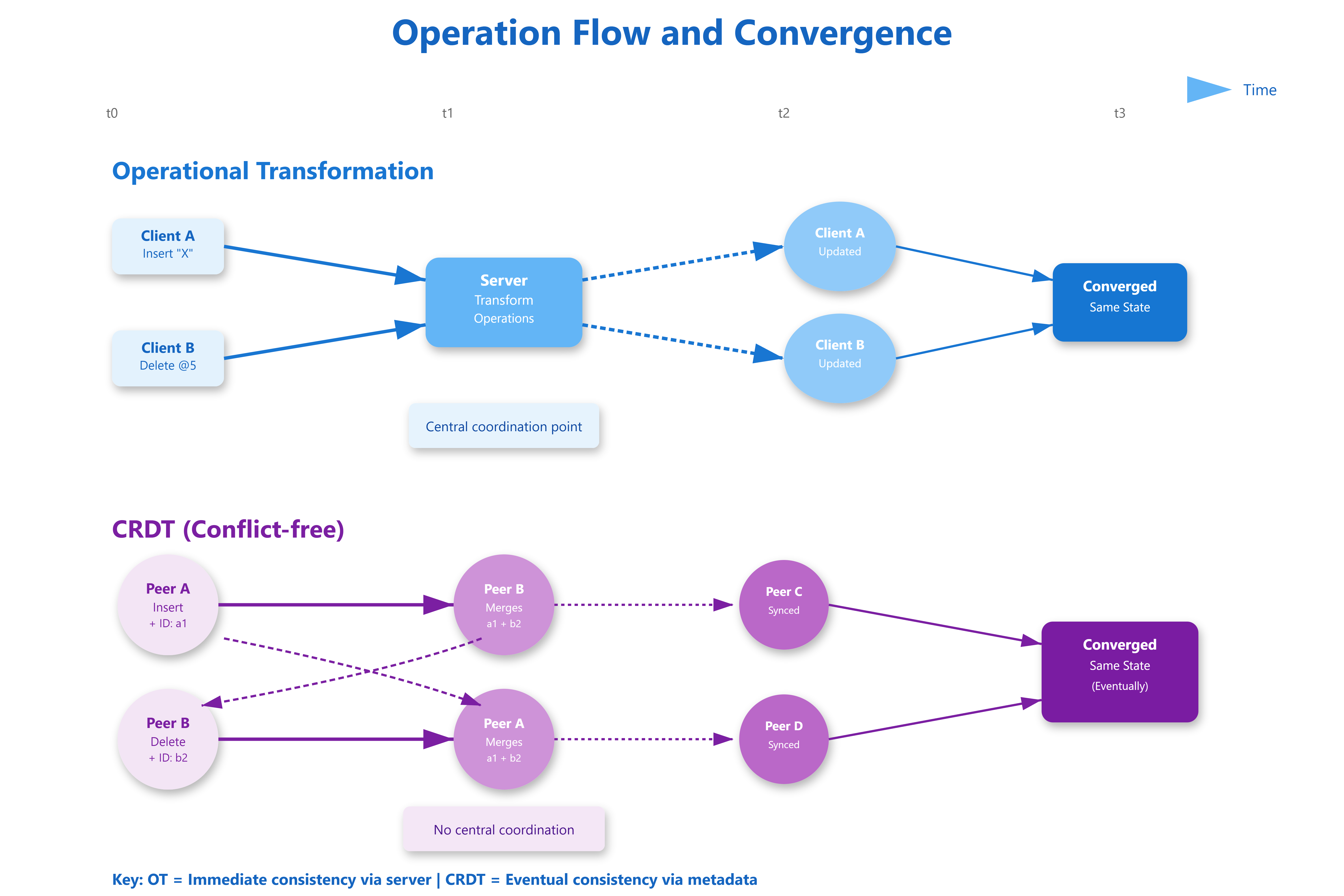
Operational Transformation treats editing as a sequence of operations that must be transformed based on context. When you type “hello” at position 5, but someone else deleted characters 2-4, your operation needs adjustment. OT transforms your operation: “insert at position 5” becomes “insert at position 3” because two characters vanished.
The algorithm maintains causality through version vectors. Each operation carries a revision number. When operations arrive out of order, the server transforms them against all concurrent operations to find the correct final position. This requires a central authority—typically a server—to establish canonical operation order.
CRDTs take a radically different approach: make the data structure itself handle conflicts. Instead of transforming operations, CRDTs embed enough metadata in the data to make all replicas converge automatically. A CRDT text editor doesn’t store “character at position 5”—it stores “character with unique ID ‘a1b2c3’ between IDs ‘x9y8z7’ and ‘m4n5o6’.” Positions become relationships.
When two users insert at the same location simultaneously, CRDTs use the embedded metadata (timestamps, user IDs, logical clocks) to deterministically decide ordering. No central authority needed. Every replica applies operations independently and mathematically guarantees convergence to the same state.
The core distinction: OT centralizes coordination logic in transformation functions. CRDTs distribute it into the data structure itself.
Critical Insights
Common Knowledge: Why Google Stuck With OT
Google Docs handles 2+ billion documents with real-time collaboration. They chose OT because the server must see every operation anyway for access control, rendering, and storage. Having a central server transform operations adds minimal latency overhead (< 5ms) but dramatically simplifies the data model. Documents stay compact—no heavy metadata per character.
OT’s transformation functions are complex (hundreds of edge cases), but they’re tested once and deployed centrally. Google’s implementation uses three-way transformation: client operations transform against server operations, which transform against other client operations. This creates a deterministic operation ordering that resolves conflicts predictably.
Rare Knowledge: The CRDT Metadata Explosion
CRDTs sound perfect until you measure. A basic string CRDT (like RGA or YATA) adds 16-32 bytes of metadata per character. A 10,000-character document balloons from 10KB to 320KB. For mobile apps or embedded systems, this kills performance. Figma mitigated this with aggressive garbage collection, removing tombstones (deleted character markers) older than 24 hours. They accept the trade-off: late-joining clients might see temporary inconsistencies until they resync.
The metadata also fragments memory. Modern CRDT implementations use sparse data structures (skip lists, B-trees) to avoid O(n) traversal costs, but this adds CPU overhead. Automerge, a popular CRDT library, uses columnar encoding to compress metadata, achieving 4-6 bytes per character—still 40-60% overhead versus raw text.
Advanced Insight: The Interleaving Problem
Both approaches hit the same wall: character interleaving during simultaneous edits. If Alice types “cat” and Bob types “dog” at the same position, you might get “cdaotg” or “cdaogt” depending on network timing. OT solves this with intention preservation—the system tries to honor what each user “meant” based on their local view. CRDTs use tie-breaking (user ID ordering, timestamps) but can’t truly preserve intent.
Google’s solution: they don’t. They accept some interleaving but add client-side heuristics. If operations arrive within 50ms and from the same cursor position, the client optimistically groups them as a “typing burst” and applies them atomically. This works 95% of the time. The 5% edge cases get the standard transformation.
Strategic Impact: Why Figma Switched from OT to CRDTs
Figma started with OT but switched to CRDTs in 2019. Their reasoning: multiplayer design involves more than text. Shapes, layers, and properties need non-linear conflict resolution. CRDTs let them model complex state machines (a shape can be deleted, moved, and resized concurrently) without writing transformation functions for every property.
The switch cost them 6 months of engineering but reduced server load by 30%. CRDTs push computation to clients, which matters when you’re rendering vector graphics. They also gained offline-first capabilities—CRDTs merge changes when clients reconnect, no central server required.
Implementation Nuance:
GitHub Link
https://github.com/sysdr/sdir/tree/main/CRDTs_vs_Operational_Transformation/crdt-ot-demoThe Undo Problem
Undo is nightmarish in collaborative systems. In OT, undoing your operation might invalidate transformations applied to others’ operations. Google Docs handles this by making undo create a new operation that reverses the old one, rather than removing the original. This preserves causal history but creates visual oddness: your undo might not restore the exact state you saw.
CRDTs have it worse. Undoing an insert means marking that character deleted, but the metadata persists forever (tombstone). Undo/redo chains create metadata bloat. Automerge limits undo history to 100 operations to prevent unbounded growth. Notion uses hybrid approach: CRDT for structure, OT for text within blocks, giving them fine-grained undo control where it matters.
Real-World Battle Scars
Google Docs’ Quirk: The “Ghost Character” Bug
In 2016, Google Docs had a bug where deleted characters reappeared during high-concurrency editing. The root cause: transformation functions didn’t handle three-way conflicts correctly when operations arrived out of causal order. Two users deleting overlapping ranges while a third inserted text created a transformation cycle. Google fixed it by adding explicit cycle detection—if an operation transforms against itself, reject it and force client resync.
Figma’s Metadata Apocalypse
Shortly after switching to CRDTs, Figma discovered documents with 10+ million tombstones from deleted shapes. Each tombstone was 32 bytes. Files became gigabytes. They implemented aggressive compaction: when a document exceeds 1 million tombstones, the server creates a new CRDT snapshot and discards history older than 7 days. Clients must resync, but file sizes drop 90%.
Linear’s Hybrid Approach
Linear uses OT for issue descriptions but CRDTs for issue metadata (status, assignee, labels). This lets them maintain compact text while getting offline-first updates for properties that change frequently. Their architecture proves you don’t need one solution—the right approach depends on data characteristics and update patterns.
Architectural Considerations
Both approaches require careful observability. Google Docs logs every transformation, tracking which operations cause conflicts and how often clients diverge from server state. They monitor “convergence time”—how long until all clients see the same view. Spikes in convergence time indicate network issues or transformation bugs.
CRDT systems need different metrics: metadata overhead, garbage collection frequency, and merge latency. Automerge exposes these via their sync protocol, letting you see exactly how much bandwidth metadata consumes. In production, metadata often exceeds actual data by 2-3x.
Cost implications differ dramatically. OT requires powerful servers (Google Docs runs on custom-built infrastructure with sub-millisecond latency SLOs). CRDTs push costs to clients—you need beefier devices. For web apps, this means larger bundle sizes (CRDT libraries are 100-200KB minified). Mobile apps must cache more state.
Use OT when you have reliable servers, need compact representations, and can tolerate centralized coordination. Use CRDTs when clients must work offline, you need peer-to-peer sync, or your data model is complex enough that transformation functions become unmanageable.
Make It Real
The demo shows both approaches side-by-side. You’ll see two collaborative text editors: one using OT with a central server, another using CRDTs (Yjs library) with peer-to-peer sync. Three simulated users edit simultaneously, creating conflicts intentionally.
Run bash setup.sh to launch the system. Open
http://localhost:3000to see the live comparison. Try deleting and inserting at the same position from different “users”—watch how OT transforms operations through the server while CRDTs converge without coordination. Check the DevTools console to see metadata overhead and operation logs.
The architecture uses Docker for the OT server, WebSocket connections for real-time sync, and IndexedDB for CRDT persistence. Extend it by adding undo/redo, experimenting with different CRDT algorithms (RGA vs YATA vs Automerge), or implementing Google’s typing burst heuristic.
Understanding these systems changes how you think about distributed state. You’ll recognize the trade-offs in every collaborative tool you use. More importantly, you’ll know when to centralize coordination (OT) and when to embed intelligence in data (CRDTs). Both are correct—for different problems.
Good read
Great post