
Data Compression Techniques for Scaling
Issue #107: System Design Interview Roadmap • Section 4: Scalability
What We'll Master Today
Understanding compression isn't just about making files smaller. Today we'll explore the strategic thinking behind compression algorithm selection, discover how Netflix saves millions through multi-layered strategies, learn when to prioritize speed over compression ratio, and master the production optimization patterns that separate amateur implementations from enterprise-grade systems.
The Hidden Economics of Data at Scale
When Spotify's engineering team audited their infrastructure costs in 2023, they uncovered a surprising truth. Despite having one of the most sophisticated music recommendation engines in the world, nearly 40% of their bandwidth costs came from uncompressed metadata synchronization between their mobile apps and backend services. Think about that for a moment. The data that users never directly see was consuming almost half their data transfer budget.
This discovery led to a fascinating optimization journey. By implementing intelligent compression strategies across different data types, Spotify reduced their annual bandwidth costs by $18 million while simultaneously improving user experience through faster synchronization. The key insight here is that compression operates as both a performance optimization and a cost reduction strategy, and at hyperscale, these benefits compound dramatically.
This real-world example illustrates a fundamental principle that many engineers miss: compression decisions should be driven by understanding your data characteristics, infrastructure constraints, and business priorities rather than defaulting to whatever algorithm you learned first.
Beyond the Default Choice: The Compression Algorithm Spectrum
Most engineers reach for gzip when they think compression, but production systems demand much more nuanced thinking. Let me help you understand how to think about algorithm selection by examining the performance characteristics that matter in real systems.
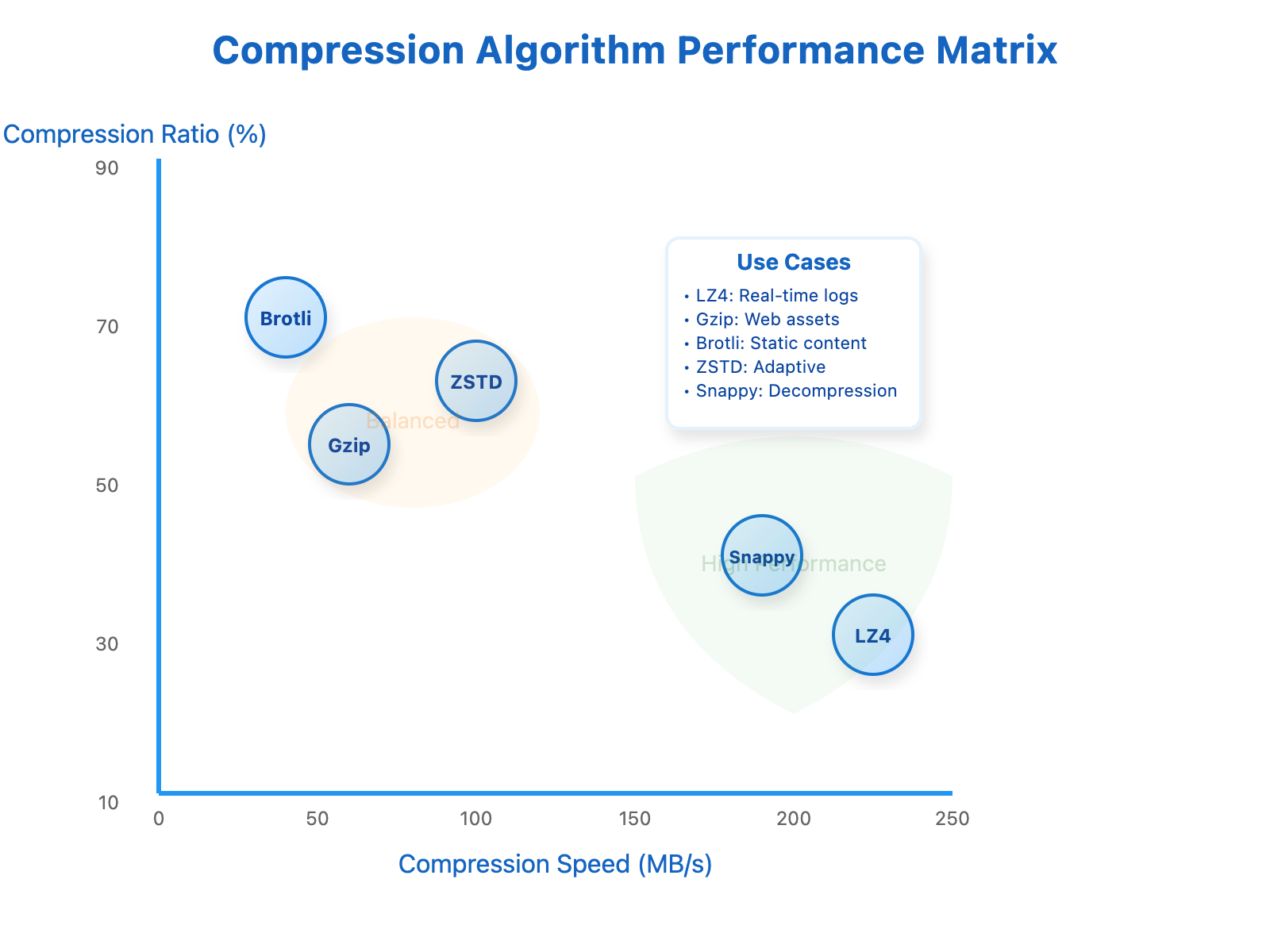
[Compression Algorithm Performance Matrix showing speed vs compression ratio trade-offs]
LZ4 represents the speed champion in our toolkit. This algorithm can process data at over 300 megabytes per second while still achieving meaningful compression ratios of 50-60%. Google's internal logging infrastructure processes over 100 terabytes daily using LZ4 because when you're handling that volume, the CPU cost of compression becomes a significant factor in your infrastructure budget. The insight here is understanding when computational efficiency trumps storage efficiency.
At the opposite end of the spectrum, we find algorithms like Brotli and high-level ZSTD that prioritize compression ratio over speed. Brotli, developed by Google specifically for web content, can achieve compression ratios 20-25% better than gzip on typical web assets. CloudFlare's implementation demonstrates this dramatically, reducing JavaScript bundle sizes from 1.2 megabytes down to just 180 kilobytes. That's an 85% reduction that translates directly into faster page load times and reduced bandwidth costs.
ZSTD, created by Facebook's engineering team, offers something particularly valuable: tunability. Unlike most algorithms that give you limited control, ZSTD provides compression levels from 1 to 22, allowing you to dial in exactly the trade-off you need. Facebook's photo storage system uses this flexibility brilliantly, applying ZSTD level 1 for frequently accessed photos where speed matters, and ZSTD level 19 for archived content where maximum space savings justify the computational cost.
The truly advanced insight that many engineers overlook involves dictionary-based compression. When you're compressing similar data repeatedly, pre-trained dictionaries can achieve compression ratios that seem almost magical. LinkedIn's messaging infrastructure uses this technique on JSON payloads, reducing typical 5-kilobyte messages down to just 500 bytes by leveraging the predictable structure of their message format.
Enterprise Multi-Layer Compression Strategies
The most sophisticated systems don't just choose one compression algorithm and apply it everywhere. Instead, they implement layered compression strategies that optimize for different parts of the data pipeline.
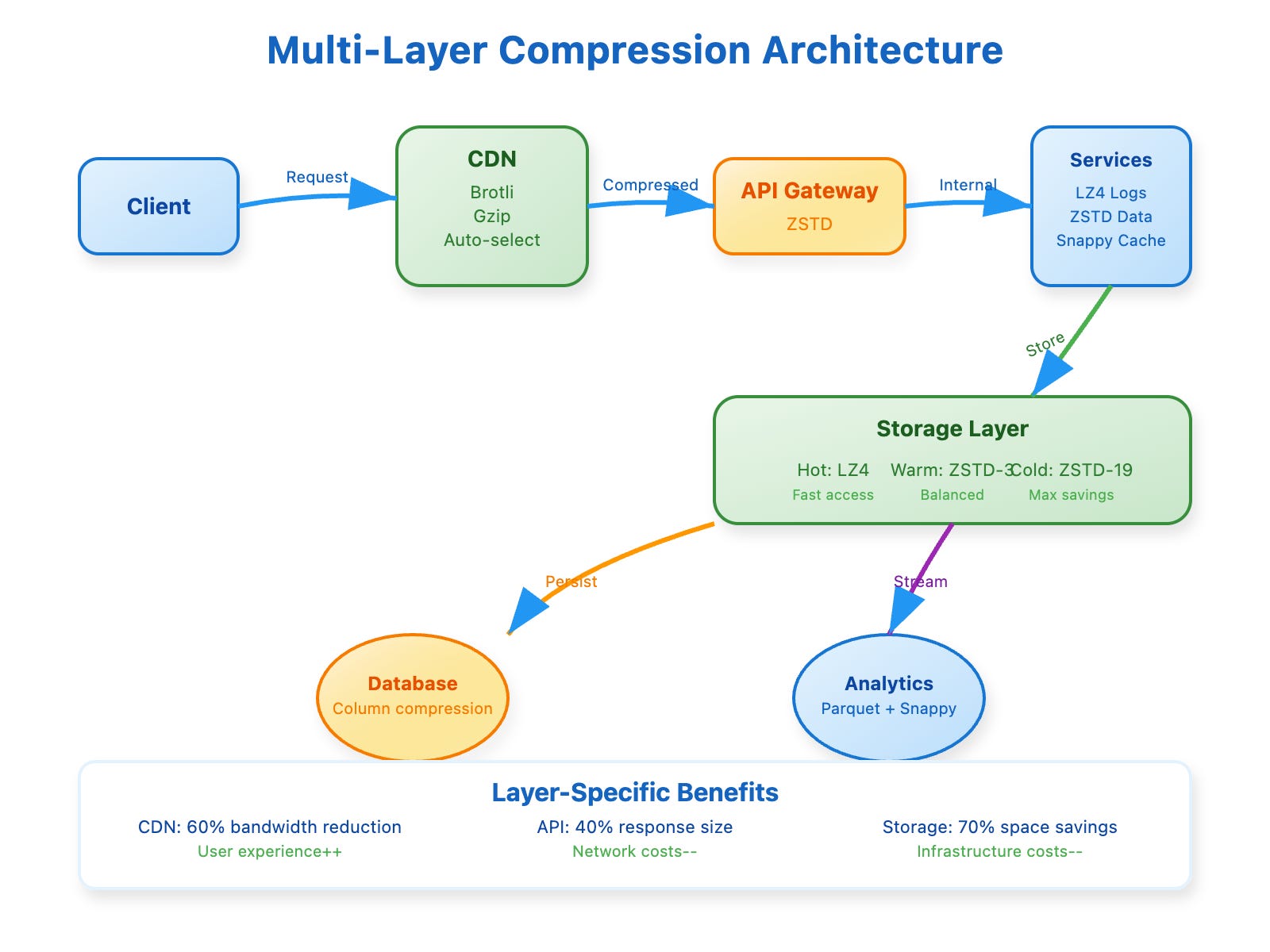
[ Multi-Layer Compression Architecture showing CDN, API Gateway, Storage, and Database layers]
Netflix provides an excellent case study in this approach. Their video delivery pipeline demonstrates how different compression strategies work together harmoniously. At the source level, they use advanced video codecs like H.264 and H.265 for the video streams themselves. For metadata like episode information and subtitles, they apply Brotli compression because this content benefits from maximum compression ratios. Their recommendation API responses use ZSTD because they need balanced performance for real-time interactions. Finally, at the CDN level, they implement adaptive compression that selects algorithms based on the requesting device's capabilities.
This multi-layer approach reveals a critical architectural principle: compression decisions should be made at the layer where you have the most context about the data's usage patterns and performance requirements. Mobile devices might receive aggressively compressed content to save bandwidth, while desktop users might receive speed-optimized compression that prioritizes rapid decompression.
Google's search infrastructure takes this concept even further. Their system processes 8.5 billion queries daily while maintaining sub-100-millisecond response times. They achieve this through layer-specific optimization: custom algorithms achieving 8:1 compression ratios on search indexes, hardware-accelerated gzip for search results transmitted over the network, and LZ4 compression for in-memory caches to maximize data density without sacrificing access speed.
Amazon's S3 service demonstrates how compression can be automated and intelligent. Their Intelligent Tiering automatically migrates data through different compression levels based on access patterns. Frequently accessed data remains uncompressed for maximum speed, infrequently accessed data receives standard compression for balanced performance, and archived data gets maximum compression for cost optimization. This automated approach has reduced customer storage costs by an average of 43% while maintaining access performance expectations.
Production Implementation Insights
Understanding compression in production requires grappling with the fundamental trade-off equation: compression time plus transmission time must be less than the original transmission time. This seems simple, but real systems complicate this calculation significantly.
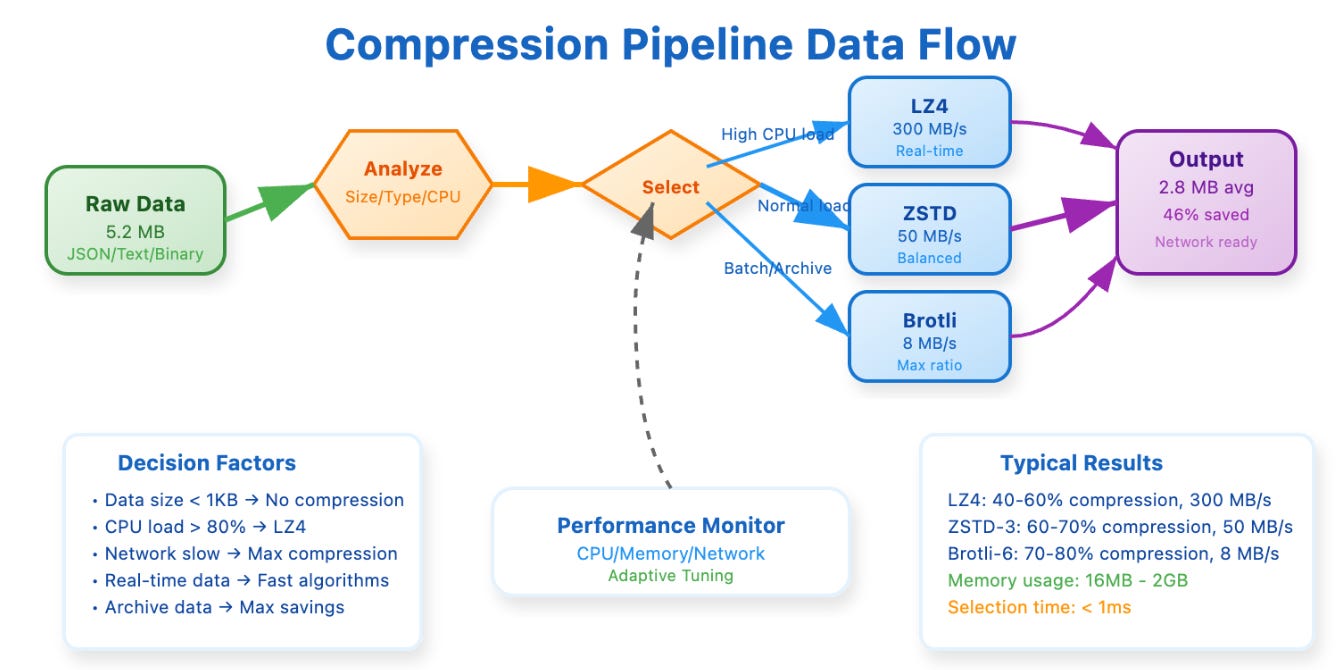
[Compression Pipeline Data Flow showing decision tree and adaptive selection logic]
Modern systems solve this through adaptive compression strategies that consider multiple factors simultaneously. CPU load becomes a critical input because compression is computationally intensive. Network characteristics matter because slow connections justify more aggressive compression even if it takes longer to compute. Data characteristics play a role because some data types compress much better than others, making the effort worthwhile.
The memory implications of compression often surprise engineers. ZSTD level 19 can use up to 2 gigabytes of RAM for optimal performance, while level 3 achieves 80% of the compression quality using only 64 megabytes. Production systems monitor memory pressure and dynamically adjust compression levels to prevent resource exhaustion.
Another crucial consideration involves streaming versus block compression. Apache Kafka demonstrates this beautifully by using streaming compression to compress message batches as they're produced, reducing both memory usage and latency compared to buffering entire blocks before compression.
The choice between these approaches depends heavily on your data patterns and performance requirements. Real-time systems typically favor streaming compression to minimize latency, while batch processing systems can take advantage of block compression's superior compression ratios.
Building Your Compression Strategy
Start by auditing your current data flows to understand where compression can provide the biggest impact. Most applications can reduce bandwidth costs by 40-70% with thoughtful compression strategies while simultaneously improving user experience through faster data transfer.
The key is beginning with conservative settings and measuring actual performance impact rather than optimizing based on theoretical characteristics. Implement ZSTD level 3 as a starting point because it provides excellent balance between compression ratio and speed, then tune based on your specific traffic patterns and infrastructure constraints.
Consider building a compression performance analyzer for your specific data types and infrastructure. This allows you to make data-driven decisions about algorithm selection rather than relying on general benchmarks that might not reflect your reality.
Remember that compression strategy should evolve with your system. What works at 1,000 requests per second might not be optimal at 100,000 requests per second. Build monitoring into your compression pipeline so you can observe how algorithm performance changes as your scale increases.
The most successful compression implementations treat algorithm selection as an ongoing optimization problem rather than a one-time architectural decision. By understanding the trade-offs, measuring real performance, and adapting to changing requirements, you can build compression strategies that provide substantial business value while maintaining excellent user experience.
Quick Demo
git clone https://github.com/sysdr/sdir.git
git checkout compression
cd compression
./demo.shNext week in Issue #108, we'll explore Instagram's sharding strategies and discover how compression affects data distribution patterns across sharded databases, building on these compression insights to understand data partitioning at scale.