Data Pipeline Architecture Patterns
What You’ll Master Today
Four core data pipeline patterns and when to choose each
Hidden scalability bottlenecks that crash production systems
Event-driven architecture secrets from Netflix and Uber
Production-ready pipeline implementation with real-time monitoring
The $2M Pipeline Failure Nobody Talks About
When Spotify’s recommendation engine started serving stale playlists to 50 million users, the root cause wasn’t complex machine learning—it was a poorly designed data pipeline that couldn’t handle weekend traffic spikes. The batch processing window stretched from 2 hours to 14 hours, creating a cascading failure that took three days to resolve.
This scenario reveals why understanding data pipeline patterns isn’t academic knowledge—it’s survival skill for modern systems. Every user interaction, transaction, and click generates data that must flow through your architecture reliably, quickly, and at scale.
Core Pipeline Patterns: Beyond Basic ETL
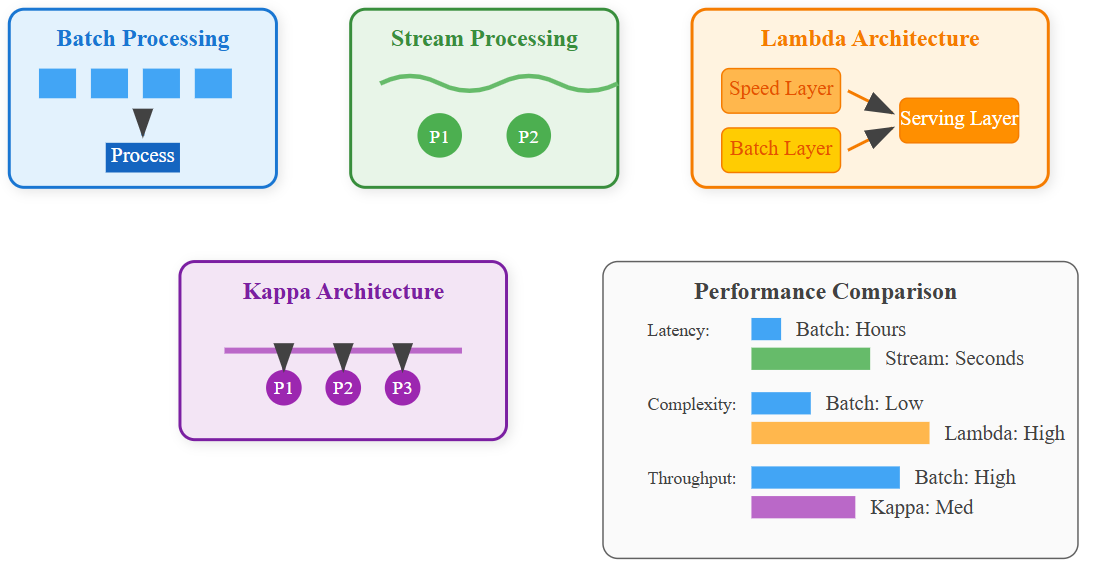
1. Batch Processing Pattern
The granddaddy of data processing, batch patterns collect data over time windows and process it in chunks. Think of it as cooking a massive meal once a day rather than constantly snacking.
When It Shines: Analytics, reporting, machine learning model training where freshness can wait for completeness.
Hidden Trap: The “batch size death spiral.” As data volume grows, processing time increases non-linearly. A pipeline that handles 1GB in 10 minutes might take 6 hours for 100GB, not the expected 16 hours.
2. Stream Processing Pattern
Real-time data processing where events flow continuously through the system like water through pipes. Each event gets processed immediately upon arrival.
When It Shines: Fraud detection, real-time recommendations, monitoring dashboards.
Critical Insight: Stream processing isn’t just “fast batch processing.” It requires fundamentally different thinking about state management, event ordering, and failure recovery.
3. Lambda Architecture Pattern
Combines batch and stream processing by maintaining both paths simultaneously. Fresh data flows through the speed layer while comprehensive processing happens in the batch layer.
When It Shines: Systems requiring both real-time responses and eventual consistency with complete historical data.
Production Reality: Twitter’s original recommendation system used Lambda architecture but eventually abandoned it due to operational complexity. Maintaining two codebases processing the same data proved unsustainable.
4. Kappa Architecture Pattern
Stream-only processing where all data, including historical data, flows through the same streaming infrastructure. It’s Lambda architecture without the batch layer complexity.
When It Shines: Event-driven systems where all data naturally arrives as events.
Netflix’s Discovery: Their transition from Lambda to Kappa reduced their data pipeline maintenance overhead by 60% while improving data freshness from hours to seconds.