
Data Warehousing: Snowflake Architecture Breakdown
Article #38 of System Design Roadmap series, Part II: Data Storage
When AWS introduced its first cloud data warehouse solution, the industry barely noticed. Today, Snowflake's market cap exceeds $60 billion. Why? Because they solved the seemingly impossible triangle of data warehousing: performance, scalability, and simplicity. But how exactly?
As a principal architect who has led migrations from traditional data warehouses to Snowflake across multiple organizations, I've discovered that what makes Snowflake truly revolutionary isn't just its SQL interface or cloud-native approach—it's the innovative architecture that separates storage, compute, and services in ways most engineers never fully appreciate.
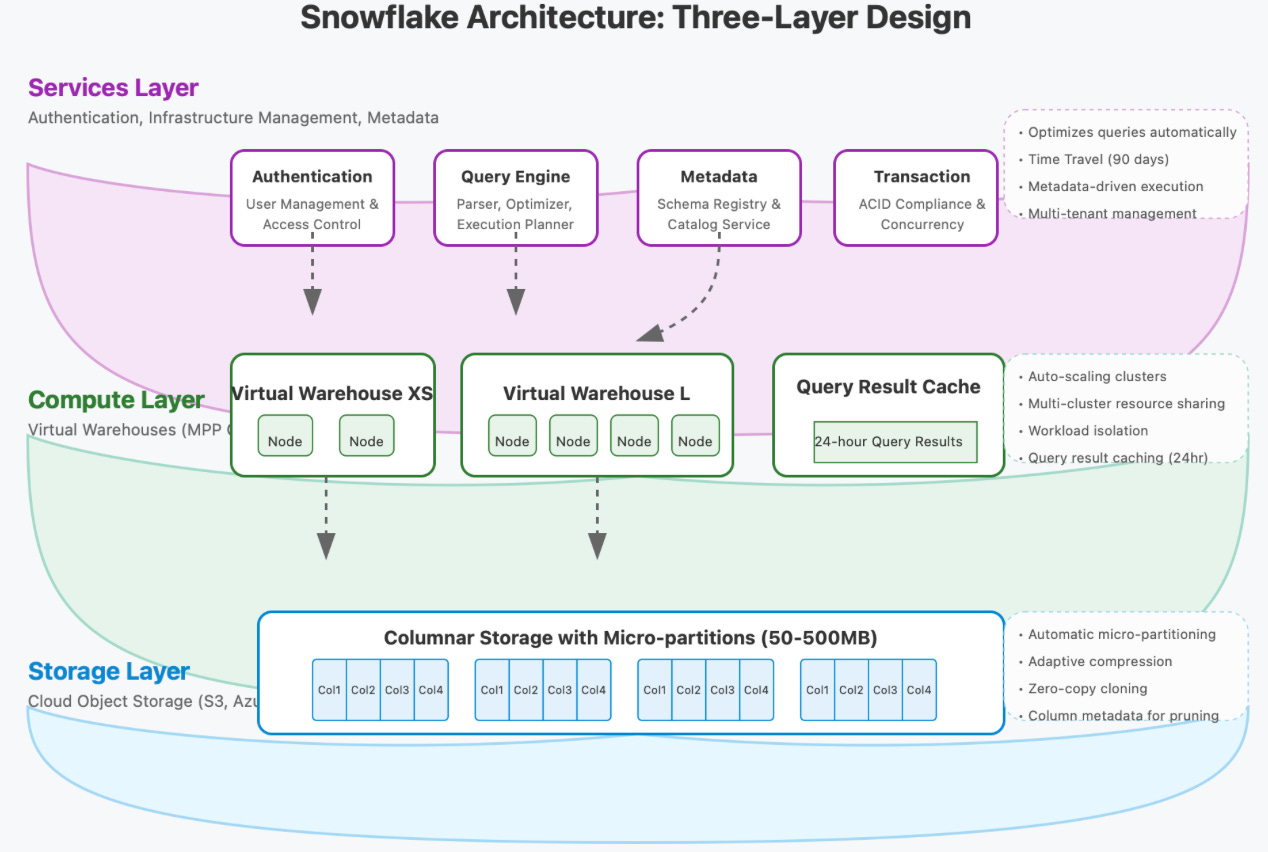
The Three-Layer Architecture: Beyond the Basics
Everyone knows Snowflake uses a three-layer architecture, but understanding the non-obvious interplay between these layers reveals why the system can handle petabyte-scale analytics at millisecond response times.
Storage Layer: Not Just Another S3 Bucket
Snowflake's storage layer uses cloud object storage (S3, Azure Blob, GCP Storage), but with crucial optimizations that few discuss:
Micro-partitioning: Unlike traditional partitioning schemes where you must choose partition keys upfront, Snowflake automatically creates 50-500MB micro-partitions, completely transparent to users. These micro-partitions contain column-level metadata that enables pruning without explicit partition columns.
Data Compression and Columnar Format: Snowflake doesn't just compress data; it applies different compression algorithms based on column data characteristics. Text fields might use dictionary encoding while numeric fields use run-length encoding—all automatically selected.
Zero-Copy Cloning: When you clone a table or database, Snowflake creates metadata pointers rather than copying data. This seemingly simple feature enables advanced development patterns like database branching that are impossible in traditional warehouses.
Compute Layer: The Secret of Elastic Scaling
The compute layer consists of "virtual warehouses"—independent MPP (Massively Parallel Processing) compute clusters:
Resource Isolation: Virtual warehouses operate independently, meaning analytical workloads don't impact data loading jobs—a crucial capability missed by teams migrating from traditional warehouses.
Automatic Query Routing: When you submit a query, the Query Parser doesn't just parse SQL; it identifies the minimum required micro-partitions, drastically reducing data scanning before execution begins.
Result Caching: Snowflake maintains three levels of caching: result cache (24 hours), local disk cache, and SSD metadata cache. The non-obvious insight: even when data changes, cached results can still be used for queries that don't touch modified micro-partitions.
Services Layer: The Orchestration Intelligence
The services layer is often overlooked but contains Snowflake's most sophisticated components:
Global Query Optimization: Unlike traditional query optimizers that make decisions based on table statistics, Snowflake's optimizer uses dynamic statistics from micro-partition metadata, enabling more precise execution plans.
Time Travel and Fail-Safe: Snowflake doesn't just store current data; it maintains table states for up to 90 days (time travel) and an additional 7 days (fail-safe). This architecture enables consistent point-in-time query capabilities without performance overhead.
Architectural Diagram
Here's how these components work together:
Real-World Performance Patterns
Netflix migrated its 500+ TB data warehouse to Snowflake and discovered two non-obvious optimization patterns:
Query Virtualization: Instead of materializing intermediate query results, they leverage Snowflake's zero-copy cloning to create ephemeral tables that only persist metadata until needed.
Workload Isolation: By creating purpose-specific warehouses (ETL warehouse, BI warehouse, data science warehouse), they improved performance by 3x without increasing costs.
Uber discovered that while Snowflake's per-query cost might be higher than their previous Hadoop/Presto solution, the total cost of ownership decreased by 45% when accounting for operational overhead and faster development cycles.
Practical Implementation
Want to implement Snowflake-like capabilities in your system? Here's a small-scale approach:
Separate storage and compute in your architecture
Implement transparent micro-partitioning by:
Dividing large files into ~100MB chunks
Storing column-level min/max values as metadata
Using this metadata for query planning to skip reading irrelevant chunks
Key Takeaway
Snowflake's true innovation isn't being cloud-native or SQL-based—it's the seamless separation of storage and compute with intelligent metadata management. When designing your own data systems, prioritize this separation pattern and invest heavily in metadata optimization. It's not just about where you store the data, but how you describe, access, and process it.
In our next article, we'll explore how Snowflake's architecture influenced modern data lakehouse systems like Delta Lake and Apache Iceberg.