
Database Caching Layers: From Memory to Disk

New Section Addition:
We have added a section to demonstrate the concept in Action, Read till end and let us know what do you think about it.
You're running a popular social media platform, and suddenly your database starts gasping for air. Users are refreshing their feeds frantically, but your system is crawling at a snail's pace. The culprit? Your database is drowning in repetitive queries, fetching the same profile pictures and user data thousands of times per second. This is where caching layers become your system's life jacket—they create multiple levels of fast access to frequently used data, dramatically reducing the load on your primary database.
Database caching layers represent one of the most critical yet misunderstood aspects of high-scale system design. Unlike simple key-value stores, these layers form a sophisticated hierarchy that mirrors how our own memory works—from lightning-fast but limited capacity at the top, to slower but vast storage at the bottom.
The Hidden Architecture of Speed
Think of caching layers as a series of increasingly larger but slower storage rings around your database. Each ring catches different types of data access patterns, and understanding their interplay is what separates systems that gracefully handle millions of requests from those that crumble under pressure.
Most engineers know about Redis or Memcached, but the real magic happens in understanding how these layers work together. The secret lies in recognizing that different data has different access patterns, temperature, and lifecycle requirements.
The Four Pillars of Database Caching
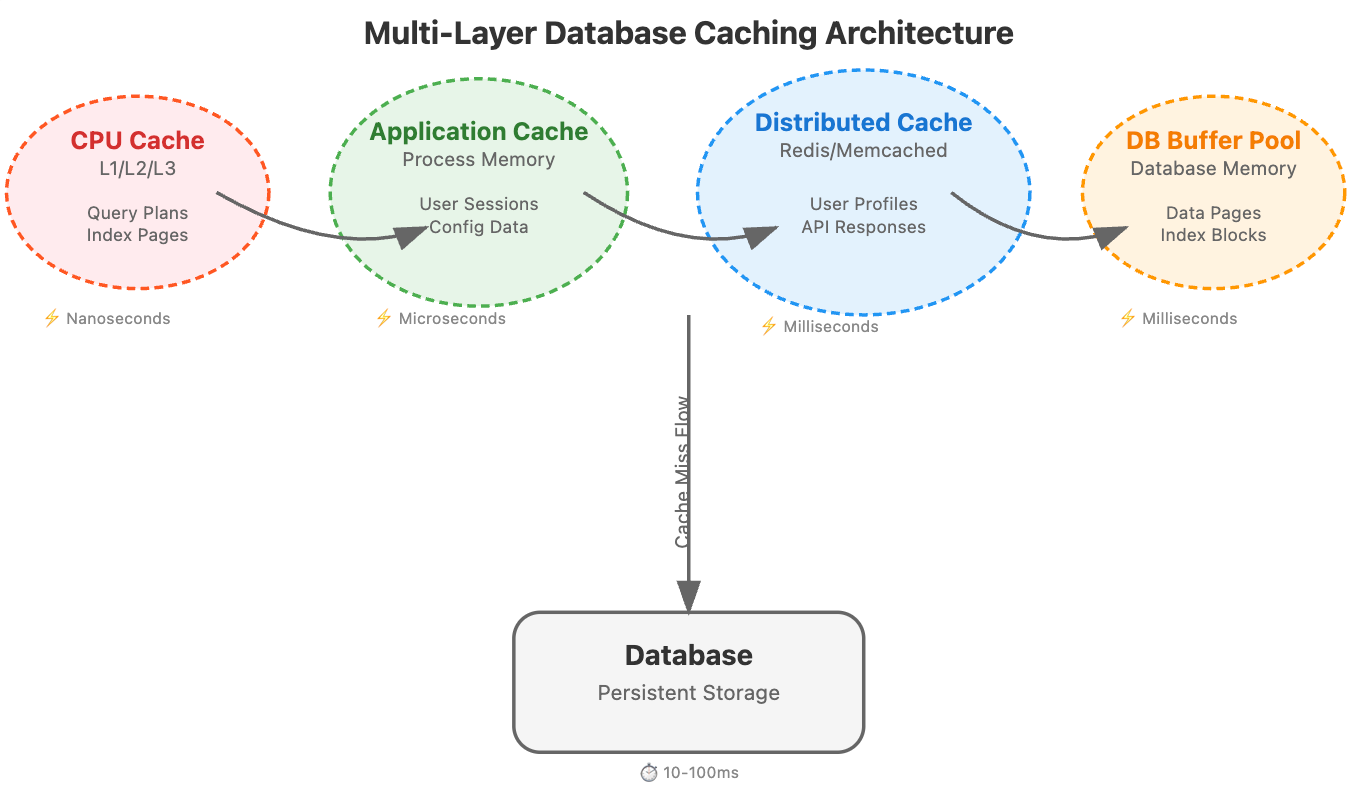
CPU Cache (L1/L2/L3): Your processor's built-in memory hierarchy handles frequently accessed query execution plans and index pages. This is often invisible to application developers, but database engines leverage it heavily for query optimization.
Application-Level Cache: This lives within your application process memory. It's blazingly fast but constrained by the memory limits of a single process. Perfect for frequently accessed configuration data, user sessions, or computed results that don't change often.
Distributed Cache Layer: Services like Redis, Memcached, or Hazelcast that sit between your application and database. This is where most engineers focus, but they often miss the nuanced configuration strategies that make the difference at scale.
Database Buffer Pool: Your database's own caching mechanism that keeps frequently accessed pages in memory. PostgreSQL's shared_buffers, MySQL's InnoDB buffer pool, or MongoDB's WiredTiger cache all fall into this category.