
Database Migration Strategies: Zero-Downtime Approaches
The Black Friday Migration: How to Change Your Database While Processing $100M in Sales
From the "System Design Interview Roadmap" series - Real insights from engineers who've scaled systems handling 10+ million requests per second
Picture this nightmare scenario: It's 11:47 PM on Black Friday. Your e-commerce platform is crushing records with $2.3 million in sales every minute. Your database team Slack channel lights up with a message that makes your stomach drop: "We need to migrate the payment database to handle the load. MySQL is hitting its limits."
The CEO's response comes instantly: "How long will the site be down?"
The silence that follows is deafening.
This exact scenario has played out at companies you know and love. Some handled it brilliantly. Others... well, let's just say their customers found alternative places to shop that weekend.
The difference? The successful companies had already mastered zero-downtime database migrations. They could evolve their systems without missing a single heartbeat, even during peak traffic.
Today, I'm sharing the battle-tested strategies that let Netflix migrate their recommendation engine, GitHub transition their core Rails database, and Shopify handle Black Friday migrations without dropping a single transaction.
The Heart Surgery Problem
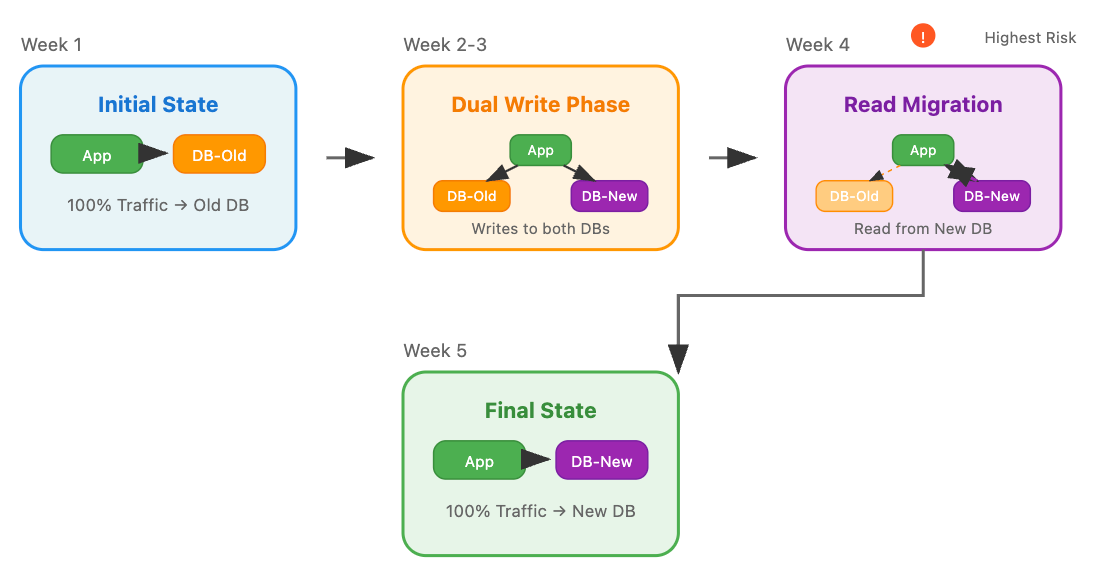
Zero-downtime migration is like performing heart surgery on a marathon runner without making them stop running. You need to keep the old system pumping data while carefully transitioning to the new one, ensuring no heartbeat is missed.
Most engineers think this is simply about having two databases and flipping a switch. The reality is exponentially more complex.
The Hidden Complexity Everyone Misses:
During migration, you're maintaining distributed state across two systems. Every write operation must be orchestrated to prevent data divergence. Applications need to handle mixed states gracefully - some data exists in the old system, some in the new, some in both.
But here's the killer: if something goes wrong mid-migration, rolling back becomes exponentially harder because you now have two potentially divergent data sources.
The Three Battle-Tested Migration Patterns
