
Database Partitioning Strategies Compared: The Hidden Art of Scaling Data at 10M+ Requests
A story from the trenches: when our payment processing system started throwing timeout errors. User complaints flooded in as checkout pages hung indefinitely. The culprit? A single database table with 500 million rows that had grown beyond our wildest projections. Our queries, once lightning-fast, now crawled through endless data like rush-hour traffic on a single-lane highway. That night taught me something most engineers learn the hard way: data growth is exponential, but most partition strategies are linear thinking applied to an exponential problem.
The Reality Behind Database Partitioning
When your database starts handling millions of records per second, traditional scaling approaches hit an invisible ceiling. Most engineers know about partitioning in theory, but the nuanced decisions that separate production-ready systems from academic exercises remain hidden in the war stories of senior architects.
Database partitioning isn't just about splitting data—it's about understanding how your application's access patterns, consistency requirements, and failure modes interact with different partitioning strategies. Each strategy carries hidden trade-offs that only become apparent under real-world load.
The Spectrum of Partitioning Strategies
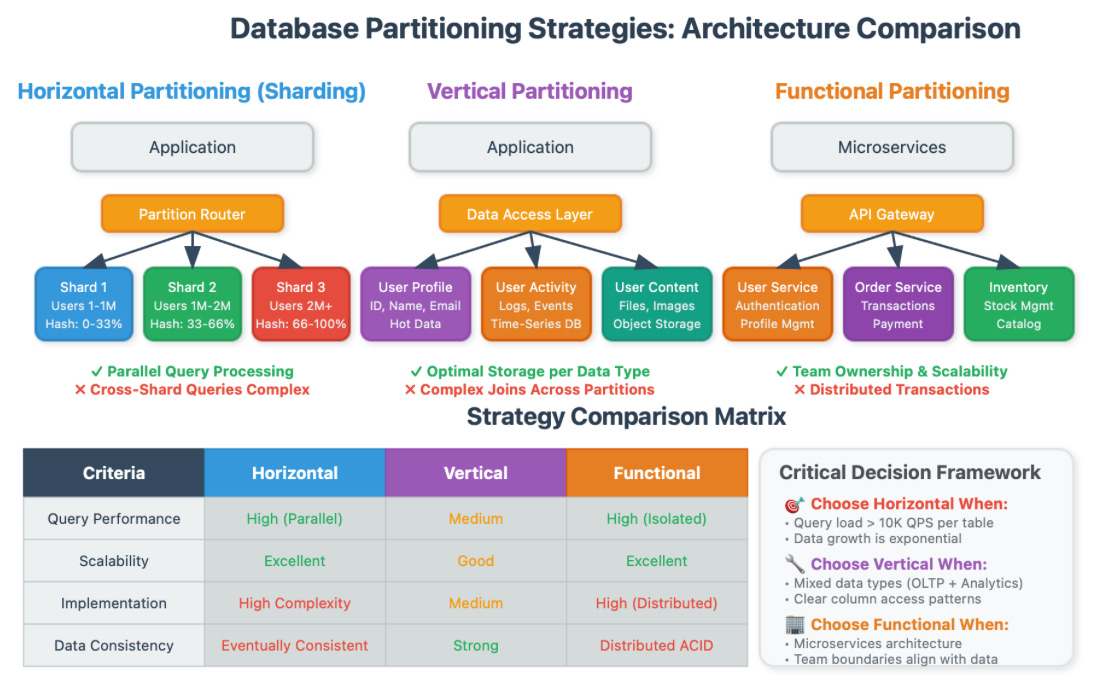
Horizontal Partitioning (Sharding): The Double-Edged Sword
Horizontal partitioning splits your data across multiple database instances based on a partition key. Think of it like organizing a massive library by moving different sections to separate buildings.
The Insight Most Miss: Sharding isn't primarily about storage capacity—it's about query parallelization and write distribution. Netflix's subscriber database, for instance, shards by user ID ranges not because they lack storage, but because user authentication queries need sub-100ms response times across 200+ million users.
The Critical Decision Point: Your sharding key determines your system's scalability ceiling. Choose poorly, and you'll face expensive re-sharding operations later. Instagram learned this lesson when they had to migrate from a simple auto-incrementing ID to a time-based sharding scheme as their photo upload patterns became increasingly skewed.
Hidden Complexity: Cross-shard transactions become distributed transactions, introducing the CAP theorem into what used to be simple ACID operations. Many teams underestimate this architectural shift.
Vertical Partitioning: The Microservices of Database Design
Vertical partitioning separates columns into different tables or databases, typically grouping frequently accessed columns together.
The Rare Insight: Vertical partitioning is often the first step toward service decomposition. When you separate user profile data from user activity data, you're implicitly defining service boundaries. LinkedIn's evolution from a monolithic database to separate services for profiles, connections, and messaging followed vertical partition lines.
Why It Matters More Than You Think: Modern applications generate increasingly diverse data types—structured transaction data, semi-structured event logs, unstructured content. Vertical partitioning allows each data type to live in its optimal storage engine.
Functional Partitioning: Domain-Driven Database Architecture
Functional partitioning separates data by business function or domain—user management, order processing, inventory tracking each get their own database.
The Strategic Insight: This strategy aligns database boundaries with team ownership and service boundaries. Amazon's "two-pizza team" rule works partly because each team can own their data completely, including partition strategy decisions.
The Operational Advantage: Different business functions have different availability requirements. Your product catalog might need 99.99% uptime, while your analytics data can tolerate occasional downtime for maintenance.
The Engineering Reality: Choosing Your Strategy
Access Pattern Analysis: The Foundation Decision
Before choosing a partitioning strategy, you must understand your data access patterns with surgical precision. Here's the analysis framework used by high-scale systems:
Query Heat Mapping: Identify which 20% of your queries account for 80% of your load. These queries dictate your partitioning strategy. Spotify discovered that 70% of their music streaming queries accessed recently played tracks, leading them to partition by recency rather than user ID.
Data Relationship Mapping: Map which data is accessed together. If user profiles and user preferences are always queried together, splitting them across partitions creates unnecessary complexity.
Write vs. Read Optimization: Writes often require different partitioning strategies than reads. Discord optimized for write-heavy chat messages by partitioning by channel and time, even though it complicated some read queries.
The Partition Key Decision: Your System's DNA
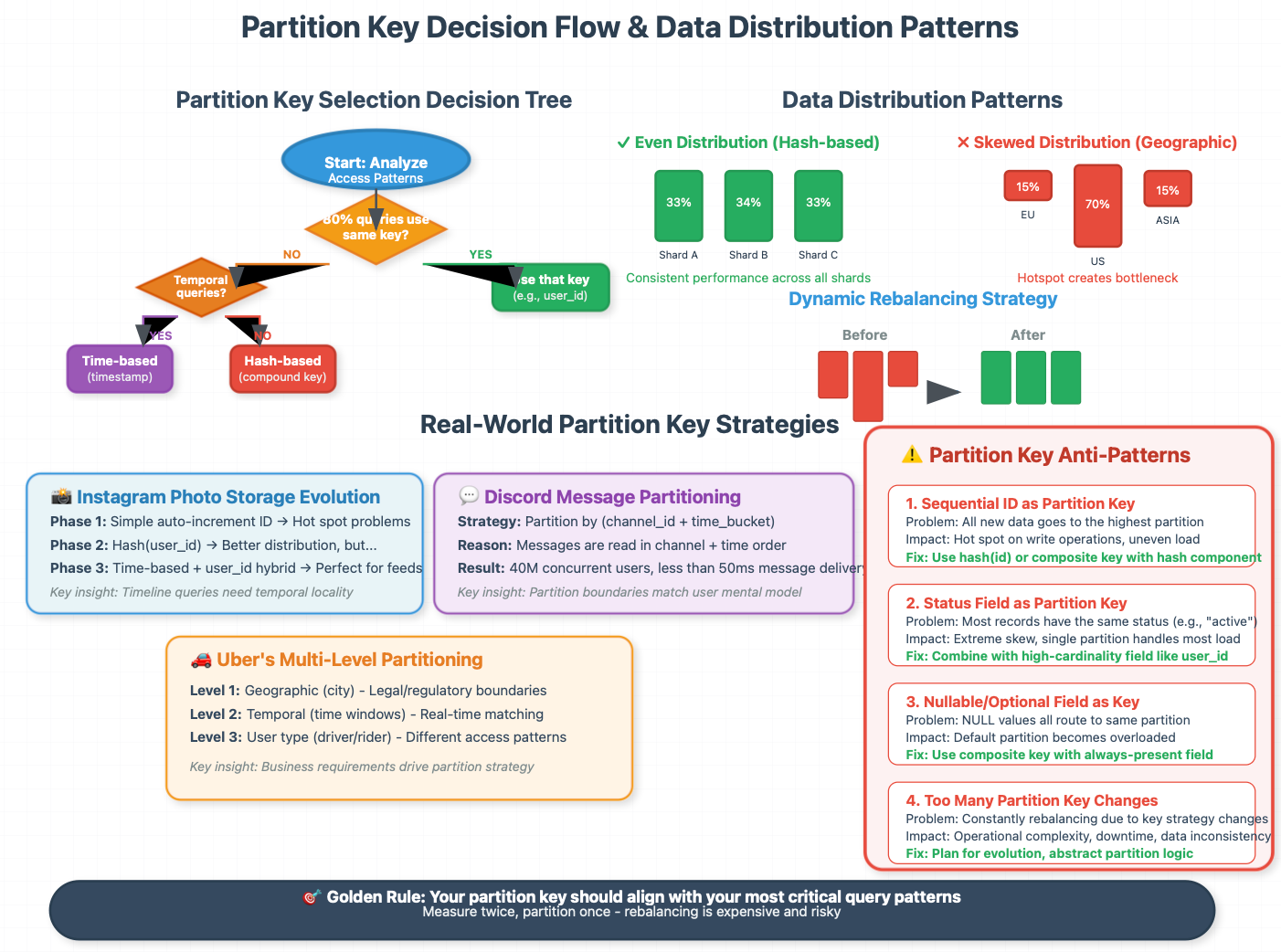
Your partition key choice has cascading effects throughout your entire system architecture. Here's the decision framework:
Even Distribution Requirement: Your partition key should distribute data evenly across partitions. Hashing user IDs works well; partitioning by geographic location often doesn't due to population density variations.
Query Alignment: Your most critical queries should be answerable within a single partition. Cross-partition queries kill performance at scale.
Operational Simplicity: More complex partition keys make operations like backup, recovery, and monitoring exponentially harder.
Real-World Example: Twitter's tweet storage evolved through multiple partitioning strategies. Initially partitioned by user ID, they moved to time-based partitioning for the public timeline, then to a hybrid approach that considers both user relationships and temporal locality.
Advanced Partitioning Patterns from the Field
The Hybrid Approach: Lessons from Uber
Uber's ride-matching system uses a sophisticated multi-level partitioning strategy that most textbooks don't cover:
Geographic Partitioning: Data is first partitioned by city to ensure ride requests stay within regional boundaries.
Temporal Sub-partitioning: Within each city, data is sub-partitioned by time windows to optimize for the real-time nature of ride matching.
User Type Partitioning: Driver and rider data use different partition strategies optimized for their distinct access patterns.
This hybrid approach allows Uber to handle millions of ride requests while maintaining sub-second response times.
The Re-partitioning Strategy: Slack's Evolution
Slack's message storage demonstrates how partitioning strategies must evolve with business growth:
Phase 1: Simple partitioning by team ID worked for small teams.
Phase 2: As teams grew larger, they added sub-partitioning by channel within teams.
Phase 3: For enterprise customers, they introduced time-based archival partitioning to separate active from historical data.
The Key Insight: Plan for partition strategy evolution from day one. Build abstractions that can accommodate changing partition keys without application rewrites.
The Operational Complexity Hidden Beneath
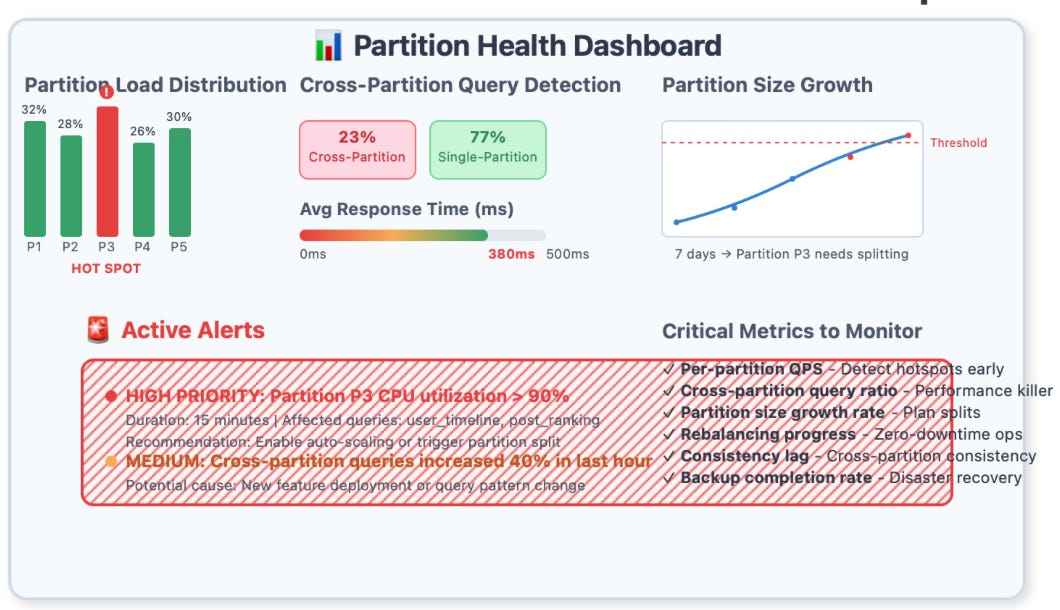
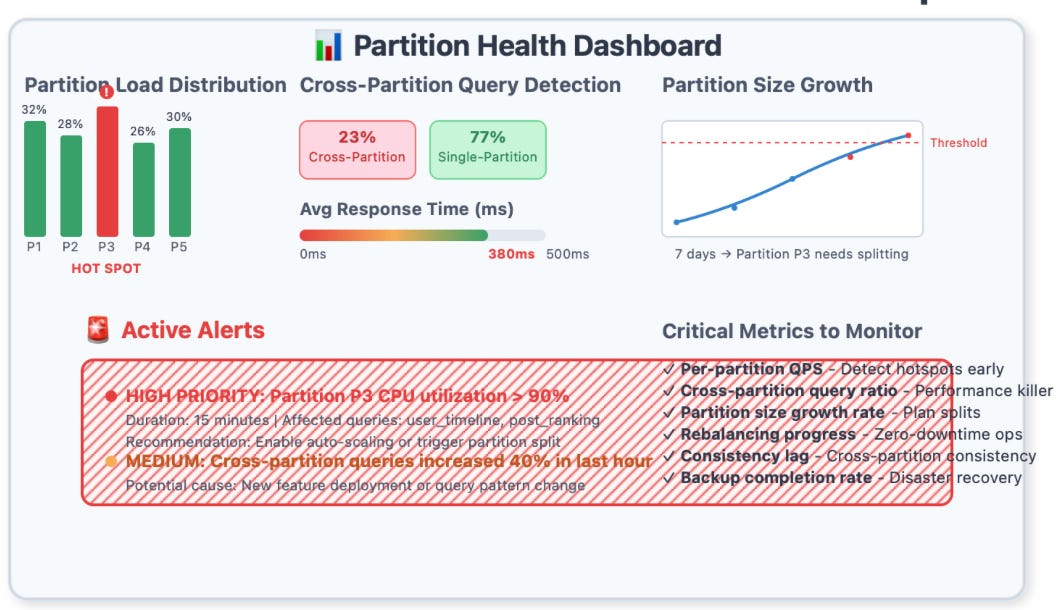
Monitoring and Observability
Partitioned systems require fundamentally different monitoring approaches:
Partition-Level Metrics: You need visibility into per-partition query performance, data distribution, and resource utilization.
Cross-Partition Query Detection: Identify queries that span multiple partitions—these often indicate architectural problems or evolution needs.
Hotspot Detection: Monitor for partition-level hotspots that can bring down your entire system.
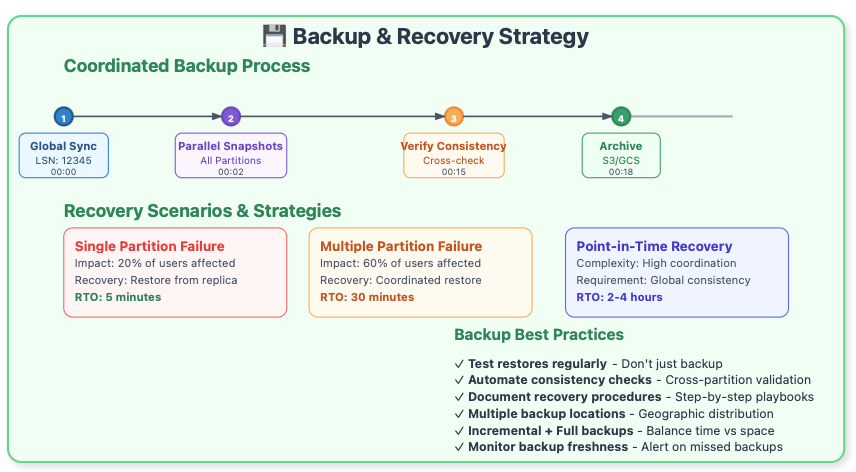
Backup and Recovery Complexity
Partitioned systems complicate backup and recovery operations in ways that catch many teams off-guard:
Consistency Points: Taking consistent backups across multiple partitions requires coordination mechanisms.
Partial Recovery Scenarios: You need procedures for recovering individual partitions while maintaining system consistency.
Point-in-Time Recovery: Coordinating point-in-time recovery across partitions is exponentially more complex than single-database recovery.
When Partitioning Goes Wrong: Avoiding the Pitfalls
The Hotspot Problem
Even well-designed partition strategies can develop hotspots. Instagram faced this when celebrity posts created partition hotspots that affected the entire platform's performance.
The Solution Pattern: Implement dynamic partition splitting and load-based routing. Modern systems like Spanner and CockroachDB do this automatically, but most traditional databases require manual intervention.
The Cross-Partition Query Trap
Cross-partition queries are the performance killer in partitioned systems. Many teams underestimate how application features will evolve to require cross-partition access.
The Mitigation Strategy: Design your application API to discourage cross-partition queries. Use data denormalization and caching strategies to keep related data co-located.
The Rebalancing Challenge
As your data grows unevenly, you'll need to rebalance partitions. This operation is complex and risky in production systems.
The Preparation Principle: Build rebalancing capabilities into your system from the beginning. Don't wait until you need them—it's too late then.
Production-Ready Implementation Guide
Building Your Partitioning Layer
Here's a practical approach to implementing partitioning that you can start using today:
Abstract the Partitioning Logic: Create a routing layer that handles partition key calculation and routing decisions. This abstraction allows you to change partitioning strategies without application changes.
Implement Gradual Migration: Build mechanisms to migrate data between partition strategies gradually. Airbnb's booking system uses a dual-write approach during migration phases.
Plan for Monitoring: Implement comprehensive monitoring from day one. You can't optimize what you can't measure.
The Configuration Framework
Production partitioning systems need sophisticated configuration management:
Dynamic Reconfiguration: Your partitioning parameters should be adjustable without downtime.
A/B Testing Capability: You should be able to test different partitioning strategies on subsets of your data.
Emergency Bypass: Include circuit breakers that can route traffic away from problematic partitions.
Build This: A Production-Ready Partition Router
Let's implement a practical partition routing system that you can adapt for your own projects. This example demonstrates the key concepts while being production-ready:

import hashlib
import time
from typing import Dict, List, Optional, Tuple
from dataclasses import dataclass
from enum import Enum
class PartitionStrategy(Enum):
HASH = "hash"
RANGE = "range"
DIRECTORY = "directory"
@dataclass
class PartitionConfig:
partition_id: str
database_url: str
weight: float = 1.0
is_active: bool = True
class PartitionRouter:
"""Production-ready partition router with monitoring and graceful degradation"""
def __init__(self, strategy: PartitionStrategy = PartitionStrategy.HASH):
self.strategy = strategy
self.partitions: Dict[str, PartitionConfig] = {}
self.metrics = {
'total_routes': 0,
'cross_partition_queries': 0,
'hotspot_warnings': 0
}
self.partition_load: Dict[str, int] = {}
def register_partition(self, config: PartitionConfig):
"""Register a new partition with the router"""
self.partitions[config.partition_id] = config
self.partition_load[config.partition_id] = 0
def route_query(self, partition_key: str, query_type: str = "read") -> str:
"""Route a query to the appropriate partition"""
self.metrics['total_routes'] += 1
if self.strategy == PartitionStrategy.HASH:
return self._hash_route(partition_key, query_type)
elif self.strategy == PartitionStrategy.RANGE:
return self._range_route(partition_key)
else:
return self._directory_route(partition_key)
def _hash_route(self, key: str, query_type: str) -> str:
"""Hash-based routing with consistent hashing"""
# Use consistent hashing for even distribution
hash_value = int(hashlib.md5(key.encode()).hexdigest(), 16)
active_partitions = [p for p in self.partitions.values() if p.is_active]
if not active_partitions:
raise Exception("No active partitions available")
# Simple modulo for demonstration - use consistent hashing in production
partition_idx = hash_value % len(active_partitions)
selected_partition = active_partitions[partition_idx]
# Track load for hotspot detection
self.partition_load[selected_partition.partition_id] += 1
self._check_hotspots()
return selected_partition.partition_id
def _check_hotspots(self):
"""Detect partition hotspots"""
if len(self.partition_load) < 2:
return
loads = list(self.partition_load.values())
avg_load = sum(loads) / len(loads)
max_load = max(loads)
# Alert if any partition has > 2x average load
if max_load > avg_load * 2:
self.metrics['hotspot_warnings'] += 1
# In production: trigger alerts, auto-scaling, or rebalancing
def get_cross_partition_query_ratio(self) -> float:
"""Calculate percentage of cross-partition queries"""
if self.metrics['total_routes'] == 0:
return 0.0
return self.metrics['cross_partition_queries'] / self.metrics['total_routes']
def health_check(self) -> Dict:
"""Return partition router health metrics"""
return {
'total_partitions': len(self.partitions),
'active_partitions': len([p for p in self.partitions.values() if p.is_active]),
'cross_partition_ratio': self.get_cross_partition_query_ratio(),
'hotspot_warnings': self.metrics['hotspot_warnings'],
'partition_load_distribution': dict(self.partition_load)
}
# Usage Example
if __name__ == "__main__":
# Initialize router
router = PartitionRouter(PartitionStrategy.HASH)
# Register partitions
router.register_partition(PartitionConfig("shard_1", "postgres://db1:5432/app"))
router.register_partition(PartitionConfig("shard_2", "postgres://db2:5432/app"))
router.register_partition(PartitionConfig("shard_3", "postgres://db3:5432/app"))
# Route some queries
user_queries = ["user_123", "user_456", "user_789", "user_123"] # Note: repeat user
for user_id in user_queries:
partition = router.route_query(user_id)
print(f"User {user_id} -> Partition {partition}")
# Check system health
health = router.health_check()
print(f"\nSystem Health: {health}")This implementation provides:
Consistent hashing for even distribution
Hotspot detection with configurable thresholds
Health monitoring with key metrics
Graceful degradation when partitions fail
Real-World Implementation References
Here are production-proven systems you can study and adapt:
Sharding Libraries:
Vitess - YouTube's MySQL sharding solution, battle-tested at massive scale
Citus - PostgreSQL extension for distributed tables
Apache ShardingSphere - Comprehensive database middleware
Partition Management Tools:
Pinterest's MySQL Sharding - Production tooling from Pinterest's infrastructure team
Facebook's MySQL Tools - Custom partitioning extensions
Monitoring Solutions:
Study Uber's M3 platform for partition-aware metrics
Examine Discord's database monitoring approach for real-time partition health
Your Implementation Roadmap
Week 1-2: Foundation
Implement basic partition routing logic
Set up monitoring for partition load distribution
Create health check endpoints
Week 3-4: Production Hardening
Add circuit breakers for failing partitions
Implement gradual rollout mechanisms
Build operational dashboards
Month 2: Advanced Features
Dynamic rebalancing capabilities
Cross-partition query optimization
Automated backup coordination
Month 3+: Scale & Optimize
Machine learning-based partition key suggestions
Predictive scaling based on growth patterns
Zero-downtime partition migrations
The Path Forward: Your Next Steps
Understanding partitioning strategies is one thing—implementing them successfully in production requires careful planning and execution. Here's your roadmap:
Start Small, Think Big: Begin with simple partitioning strategies that solve your immediate problems while building infrastructure that can evolve.
Measure Everything: Implement comprehensive monitoring and alerting for your partitioned system from day one.
Plan for Growth: Design your partitioning strategy to handle 10x your current scale, but implement only what you need today.
Learn from Others: Study how companies similar to yours have solved partitioning challenges. Their war stories contain insights you can't find in documentation.
The most successful partitioning implementations aren't the most sophisticated—they're the ones that evolve gracefully with business requirements while maintaining operational simplicity. Your partitioning strategy should feel like a natural extension of your application architecture, not a complex overlay that fights against your system's inherent patterns.
Remember: the best partitioning strategy is the one your team can operate confidently at 3 AM when things go wrong. Technical elegance matters less than operational clarity when your system is processing millions of requests per second and every minute of downtime costs thousands of dollars.
The journey from single-database simplicity to partitioned-system complexity is inevitable for successful applications. The question isn't whether you'll need partitioning—it's whether you'll be ready when that moment arrives.