
Database Replication: Master-Slave vs. Multi-Master
Issue# 26 of System Design Interview Roadmap: Part II Data Storage
The silent guardians of your data's availability and durability
Last week, I was troubleshooting a production incident at 3 AM when our primary database server unexpectedly went down. What saved us wasn't heroic coding—it was the replication architecture we'd carefully designed months before. Within seconds, a slave node seamlessly promoted itself to master, and most users never noticed the hiccup. This experience reminded me why database replication isn't just theoretical—it's the difference between a minor incident and a career-defining disaster.
The Hidden Power of Database Replication
Database replication creates and maintains copies of your data across multiple database instances. But replication isn't just about having backups—it's about ensuring data accessibility, load distribution, and failure resilience at scale.
At its core, database replication needs to answer two critical questions:
How do we propagate changes across database instances?
How do we handle conflicts when they inevitably arise?
Let's explore the two dominant replication models that solve these problems in fundamentally different ways.
Master-Slave Replication: The Reliable Workhorse
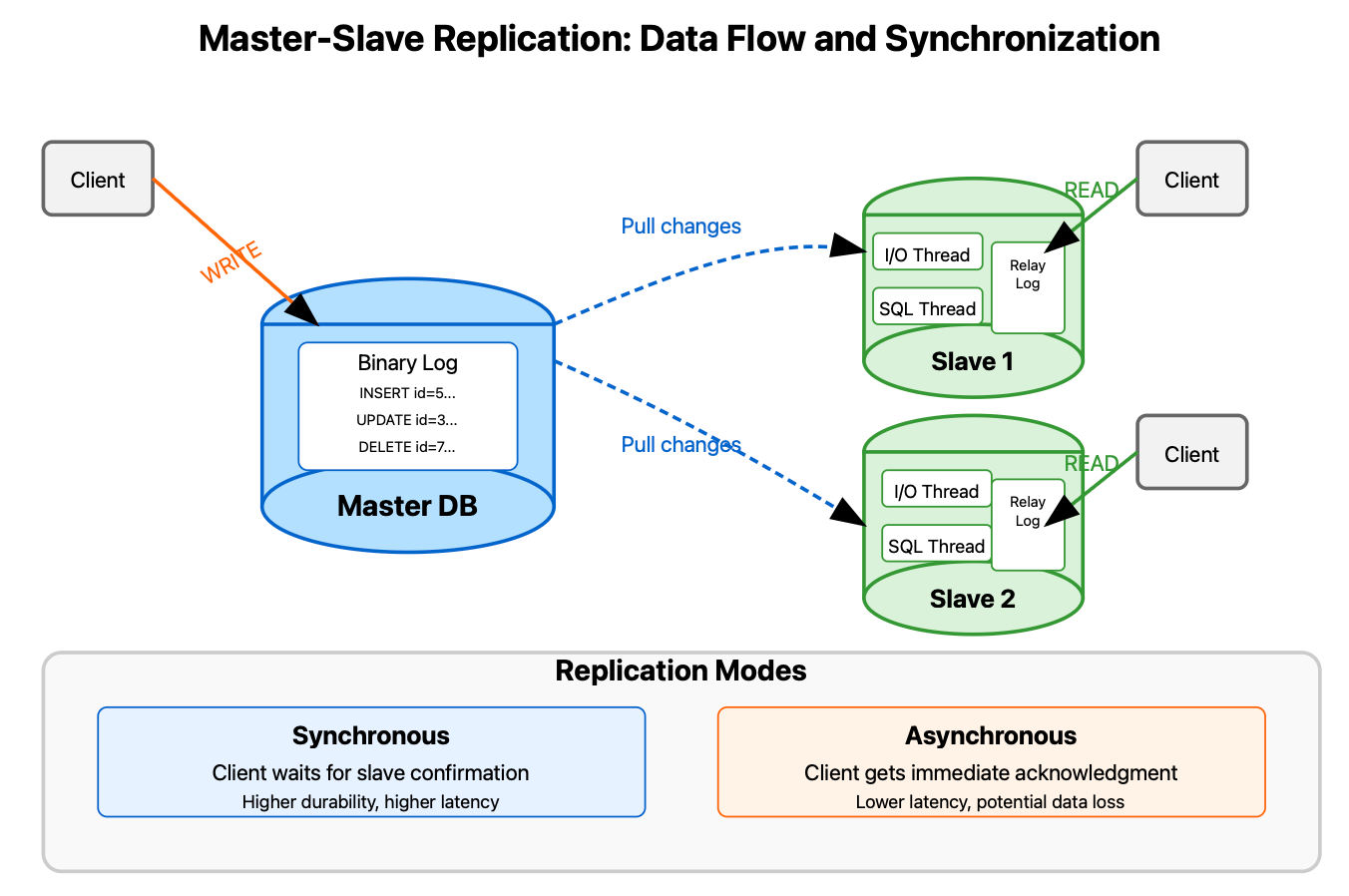
Master-slave replication (also called primary-replica) establishes a clear hierarchy: one primary database (the master) processes all write operations, while multiple replicas (slaves) synchronize with it to serve read operations.