Designing a Distributed Job Scheduler: Handling Delayed and Recurring Tasks
The Silent Orchestrator
Your calendar sends reminders at precise times. Your payroll runs every two weeks. Your database backups trigger at 2 AM daily. Behind these seemingly simple scheduled tasks lies a distributed job scheduler—a system that must coordinate work across multiple machines while handling failures, retries, and time zones, all without dropping a single task.
When Airbnb processes millions of nightly pricing updates or Stripe schedules delayed invoice generation for thousands of merchants, they rely on distributed job schedulers that guarantee execution even when servers crash mid-task.
The Core Challenge: Time + Distribution + Reliability
A distributed job scheduler solves three simultaneous problems: tracking time-based triggers, coordinating across multiple worker nodes, and guaranteeing exactly-once execution despite failures.
Time Management Architecture
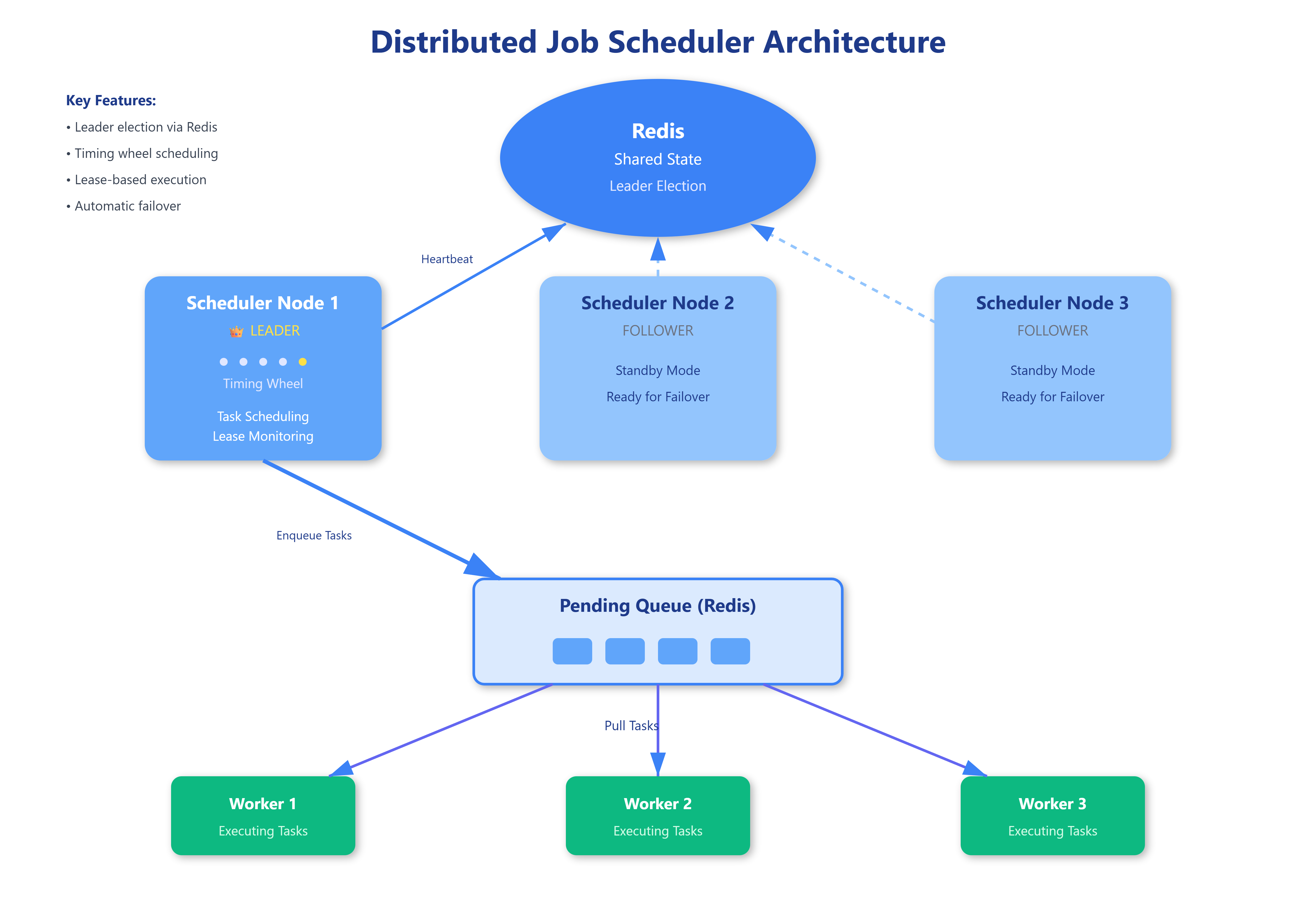
The scheduler maintains a priority queue of tasks sorted by execution time. Unlike simple cron jobs on a single machine, distributed schedulers use a centralized timing wheel—a circular buffer where each slot represents a time interval (say, 1 second). Tasks scheduled for near-future execution sit in the wheel, while far-future tasks live in a backing store until they’re within the wheel’s time range.
When a task’s slot arrives, the scheduler moves it to a pending queue. This two-tier design prevents memory exhaustion from storing millions of tasks scheduled months ahead while maintaining O(1) insertion and deletion for near-term tasks.
Distribution and Partitioning
Multiple scheduler instances operate simultaneously, each responsible for a partition of tasks. Partitioning happens by task ID (using consistent hashing) rather than execution time, ensuring a crashed scheduler’s tasks can be reassigned to healthy nodes without reprocessing the entire schedule.
Worker nodes pull tasks from the pending queue. The scheduler tracks task state transitions: scheduled → pending → running → completed/failed. This state machine prevents double-execution—if a worker crashes mid-task, the scheduler can detect the stalled “running” state and reassign after a timeout.
The Lease-Based Execution Model
Here’s where it gets subtle. When a worker claims a task, it receives a time-bounded lease (typically 30-60 seconds). The worker must complete the task and report success before the lease expires, or the scheduler assumes failure and reassigns the task.
This creates a critical race condition: what if a worker completes the task successfully but the network delays its success report beyond the lease timeout? The scheduler reassigns the task, and suddenly two workers execute the same job.
The solution: idempotency tokens. Each task carries a unique execution ID that workers include in their work. The downstream system (like a database or API) checks this token and rejects duplicate operations, achieving exactly-once semantics despite at-least-once scheduling.