Developer Platform Design: Internal Tools Architecture
The Platform Paradox
Your engineering team just shipped 47 microservices. Each team deploys independently, monitors their own dashboards, manages their own configurations, and troubleshoots their own incidents. Six months later, you’re drowning in inconsistency—twelve different deployment scripts, eight monitoring solutions, five ways to handle secrets, and zero standardization. This is when you realize: developer productivity isn’t just about writing code faster; it’s about removing the cognitive overhead of everything surrounding that code.
The Core Architecture
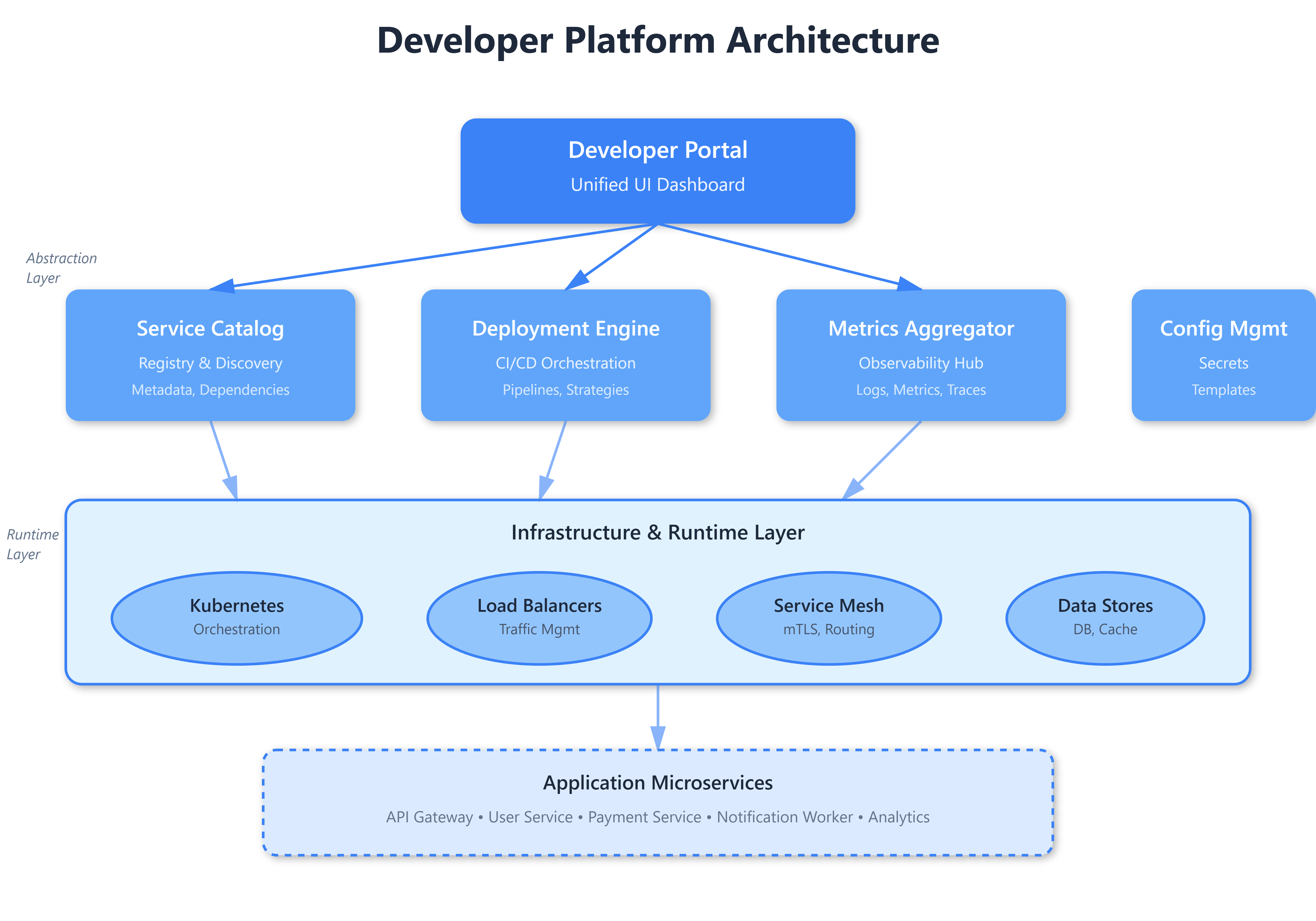
A developer platform is infrastructure that other engineers build upon. Unlike user-facing products, your customers are developers who demand reliability, clarity, and escape hatches when automation fails. The architecture centers on three pillars: abstraction layers that hide infrastructure complexity, self-service capabilities that eliminate bottlenecks, and golden paths that make the right way the easy way.
The typical stack includes a service catalog (what exists), a deployment pipeline (how to ship), observability aggregation (what’s happening), and a developer portal (unified interface). But here’s what most teams miss: these aren’t separate tools—they’re a connected graph. Your service catalog feeds your deployment pipeline, which triggers observability, which surfaces data back to the portal. Break one link, and the entire platform feels fragile.
The mechanism works through progressive disclosure.
Developers start with high-level primitives—”deploy this service” or “scale to 10 replicas”—without knowing the underlying Kubernetes manifests, load balancer configurations, or autoscaling policies. As they grow, they can peek under the hood, override defaults, or even fork the platform code. This layered approach prevents both the “too simple to be useful” and “too complex to adopt” failure modes.
What catches teams off guard: internal tools require more operational rigor than customer products, not less. When your deployment platform has an outage, every engineering team stops shipping. When your monitoring aggregator fails, incidents become invisible. The blast radius of platform failures is organizational, not just technical. This means your internal tools need 99.9%+ uptime, graceful degradation, and clear escalation paths—ironically higher standards than many customer-facing systems.