
Fault Tolerance vs. High Availability: Visual Guide
Issue #113: System Design Interview Roadmap • Section 5: Reliability & Resilience
Agenda
Core distinction between fault tolerance and high availability
Design patterns for each approach with real-world examples
Decision framework for choosing the right strategy
Implementation insights from Netflix, Google, and Amazon
The Tale of Two Outages
Your payment service just crashed during Black Friday. Do you: A) Restart it and hope for the best, or B) Route traffic to a backup service instantly?
If you chose A, you're thinking fault tolerance—making systems survive failures. If you chose B, you're thinking high availability—ensuring services stay accessible. Both are crucial, but they solve different problems.
The Core Distinction That Changes Everything
Fault Tolerance asks: "How do we keep working when things break?" High Availability asks: "How do we stay accessible when things break?"
Netflix's video streaming exemplifies this difference. Their fault tolerance includes smart retries and graceful degradation—if recommendations fail, you still see trending content. Their high availability means multiple data centers serve content—if one fails, another takes over seamlessly.
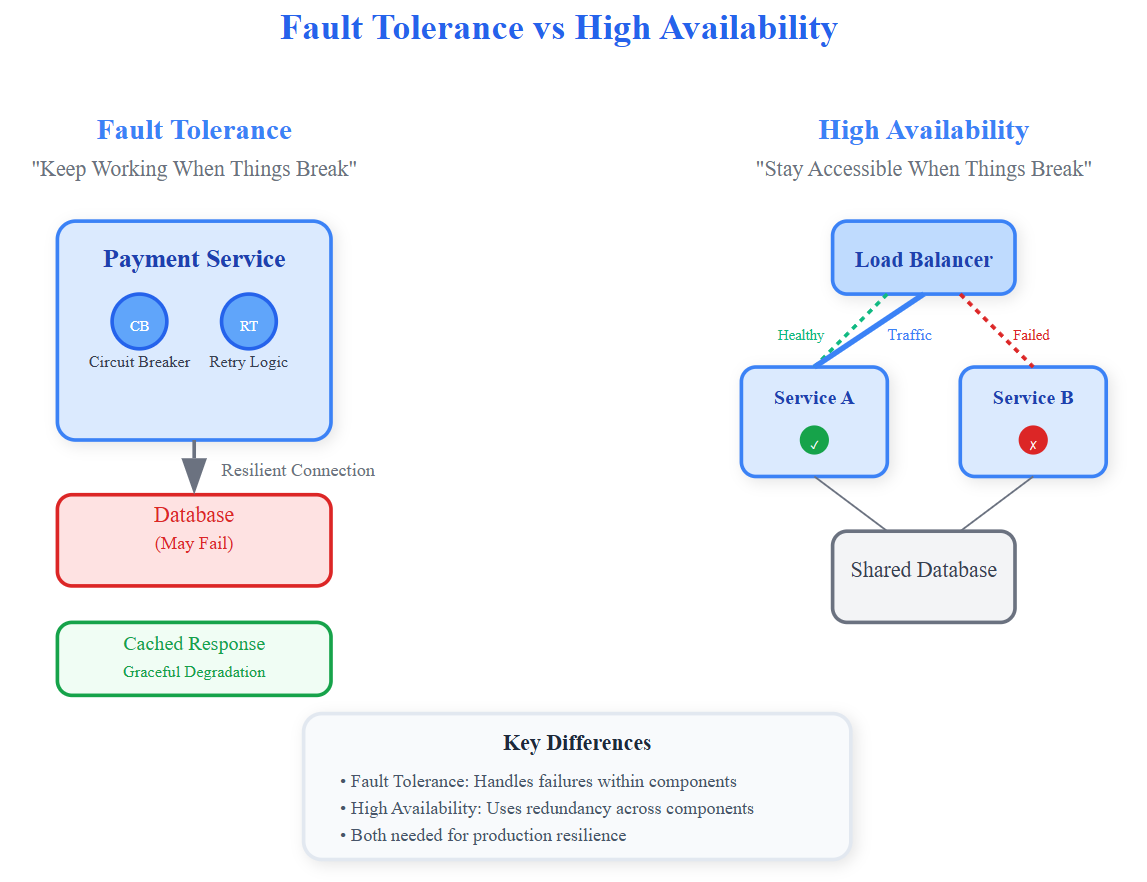
The insight most engineers miss: fault tolerance is about resilience within components, while high availability is about redundancy across components.
Real-World Implementation Patterns
Fault Tolerance Mechanisms
Circuit Breakers: Hystrix at Netflix prevents cascading failures by failing fast when downstream services are unhealthy. When error rates exceed thresholds, the circuit "opens" and returns cached responses instead of overwhelming failing services.
Exponential Backoff with Jitter: AWS services use randomized retry delays to prevent thundering herd problems. Instead of all clients retrying simultaneously, jitter spreads requests across time windows.
Bulkhead Isolation: Like ship compartments, isolating thread pools prevents one failing operation from consuming all system resources. Critical operations get dedicated resource pools.
High Availability Strategies
Active-Passive Failover: Database clusters maintain hot standbys that activate when primaries fail. Kubernetes does this with pod replicas—if one dies, traffic routes to healthy instances.
Geographic Distribution: Google Search serves from multiple continents. Regional failures don't impact global availability because traffic automatically routes to healthy regions.
Load Balancer Health Checks: Continuously probe backend services and remove unhealthy instances from rotation. Users never see failed requests.
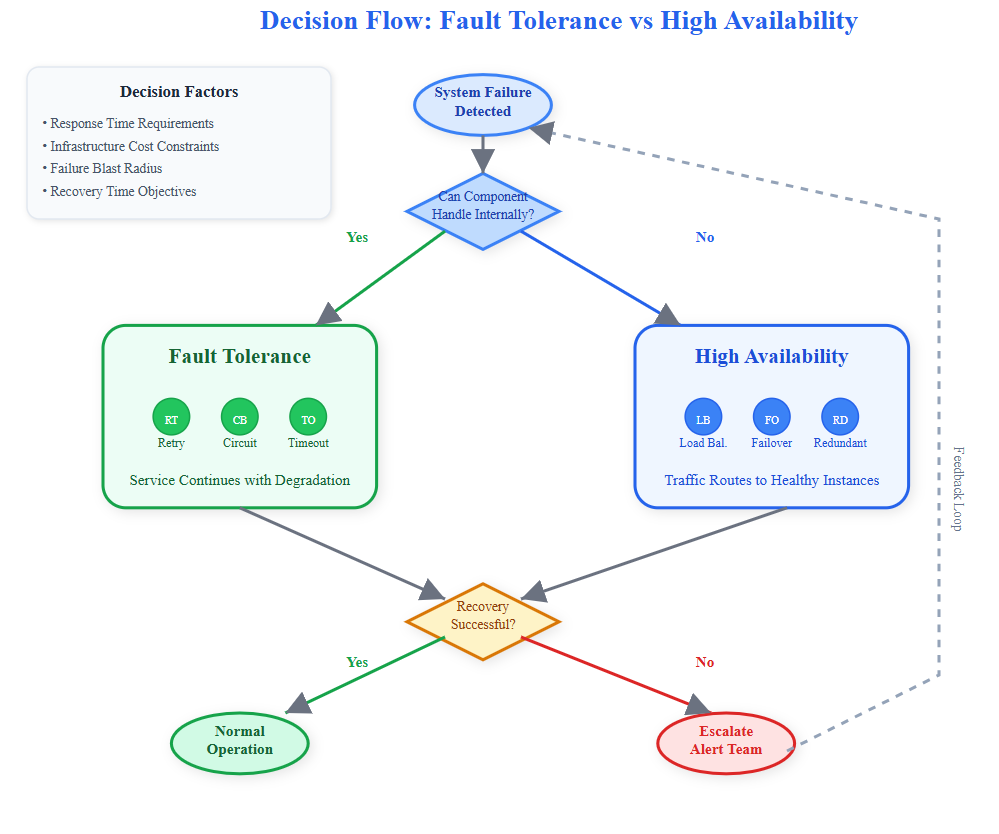
The Decision Framework
Choose Fault Tolerance when:
Building stateful services that can't easily restart
Handling external dependencies prone to temporary failures
Operating under resource constraints where redundancy is expensive
Choose High Availability when:
Serving user-facing traffic requiring sub-second response times
Managing critical business processes where downtime costs exceed infrastructure costs
Operating in environments with frequent hardware failures
Advanced Insights From Production
The Temporal Dimension
Fault tolerance operates in milliseconds to minutes—how quickly can you detect and recover from failures? High availability operates in seconds to hours—how long can you maintain service during extended outages?
Google's Spanner database demonstrates both: fault tolerance through automatic retries and transaction replay, plus high availability through multi-region replication with automatic failover.
The Cost-Complexity Trade-off
Fault tolerance typically costs more in development time but less in infrastructure. High availability costs more in infrastructure but less in complexity. Amazon's approach: heavy fault tolerance within services (retries, timeouts, circuit breakers) combined with simple high availability patterns (auto-scaling groups, health checks).
The Observer Effect
Adding fault tolerance can create new failure modes. Retries can overwhelm recovering services. Circuit breakers can cause avalanche failures when they close simultaneously. High availability's redundancy can hide subtle bugs that only manifest under specific failure combinations.
Interview Gold: What Seniors Get Wrong
Common Misconception: "High availability means no downtime." Reality: High availability means planned recovery from predictable failures. Fault tolerance handles unpredictable failures within acceptable degradation bounds.
The Netflix Example: During AWS outages, Netflix's fault tolerance keeps video playing for current users (graceful degradation), while their high availability moves login services to other regions (maintaining core functionality).
Building Your Mental Model
Think of fault tolerance as immune system—internal mechanisms that fight off problems. High availability is emergency backup—external redundancy that activates when internal systems fail.
Modern systems need both: microservices with fault tolerance patterns (circuit breakers, retries, timeouts) deployed across highly available infrastructure (multiple zones, load balancers, auto-scaling).
Your Next Production Decision
When designing your next system, ask:
What's the blast radius if this component fails?
What's the recovery time users will tolerate?
What's the cost of redundancy vs. fault tolerance?
Start with fault tolerance for predictable failures, add high availability for business-critical components. Monitor both—fault tolerance through error rates and latency, high availability through uptime and failover success rates.
Building the Demo: Hands-On Implementation
Github Link: https://github.com/sysdr/sdir/tree/main/fault_tolerance
Let's build a real system that demonstrates both patterns working together. You'll see circuit breakers, retries, load balancing, and automatic failover in action.
System Architecture
Our demo creates a realistic e-commerce microservices system:
Payment Service (Fault Tolerant)
Circuit breaker protection
Exponential backoff retries with jitter
Graceful degradation with cached responses
Real-time state monitoring
User Service Cluster (High Availability)
Three service instances
Load balancer with health checks
Automatic failover on instance failure
Round-robin traffic distribution
API Gateway
Request routing and metrics collection
Rate limiting and CORS handling
Service discovery and health monitoring
React Dashboard
Real-time system metrics visualization
Interactive failure injection testing
Circuit breaker state display
Request success rate monitoring
Quick Setup
Prerequisites: Docker, Node.js 18+, and a terminal
Step 1: Download and extract the demo script
bash
cd fault-tolerance-ha-demo
chmod +x demo.shStep 2: Start the complete system
bash
./demo.shThis installs dependencies, builds Docker containers, and starts all services. Takes about 2-3 minutes.
Step 3: Access the dashboard Open
http://localhost:80
in your browser to see the live system dashboard.
Testing Both Patterns
Fault Tolerance Test
Click "Test Fault Tolerance" in the dashboard:
Normal Operation: Payment service processes requests normally
Failure Injection: Service starts failing 70% of requests
Circuit Breaker Opens: After 5 failures, circuit breaker triggers
Graceful Degradation: Service returns cached "queued payment" responses
Automatic Recovery: After 30 seconds, circuit breaker closes and service recovers
What You'll See:
Circuit breaker state changes from CLOSED → OPEN → HALF_OPEN → CLOSED
Retry counter increases during failures
Service status changes from healthy → degraded → healthy
Fallback responses maintain user experience
High Availability Test
Click "Test High Availability" in the dashboard:
Load Balancing: Requests distribute across three user service instances
Instance Failure: One randomly selected instance stops responding
Health Check Detection: Load balancer marks failed instance as unhealthy
Automatic Failover: Traffic routes only to healthy instances
Continued Service: Users experience no service interruption
What You'll See:
Instance status indicators change from green to red
Request distribution shifts to healthy instances
Overall service availability remains at 100%
Failed instance automatically recovers after 20 seconds
Key Implementation Details
Circuit Breaker Logic (Payment Service)
javascript
// Circuit breaker with configurable thresholds
const circuitBreaker = new CircuitBreaker({
timeout: 5000, // 5 second timeout
errorThreshold: 50, // Open after 50% error rate
resetTimeout: 30000 // Try to close after 30 seconds
});
// Exponential backoff with jitter
async function retryWithBackoff(fn, maxRetries = 3) {
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
return await fn();
} catch (error) {
if (attempt === maxRetries) throw error;
const delay = Math.min(1000 * Math.pow(2, attempt - 1), 10000);
const jitter = Math.random() * 0.1 * delay;
await new Promise(resolve => setTimeout(resolve, delay + jitter));
}
}
}Load Balancer Logic (API Gateway)
javascript
// Health-aware round-robin load balancing
function getHealthyUserService() {
const healthyInstances = userServiceInstances.filter(instance => instance.healthy);
if (healthyInstances.length === 0) return null;
const instance = healthyInstances[currentUserInstance % healthyInstances.length];
currentUserInstance++;
return instance;
}
// Continuous health monitoring
setInterval(async () => {
for (const instance of userServiceInstances) {
try {
const response = await fetch(`${instance.url}/health`, { timeout: 5000 });
instance.healthy = response.ok;
} catch (error) {
instance.healthy = false;
}
}
}, 10000); // Check every 10 secondsAutomated Testing
The system includes comprehensive automated tests:
bash
cd tests && npm testTest Coverage:
Circuit breaker state transitions
Retry mechanism behavior
Load balancer failover logic
Health check accuracy
Graceful degradation responses
Service recovery timing
Monitoring and Metrics
The dashboard displays real-time metrics:
Fault Tolerance Metrics:
Circuit breaker state (CLOSED/OPEN/HALF_OPEN)
Retry attempt counts
Service health status
Response time distribution
High Availability Metrics:
Individual instance health
Request distribution patterns
Failover timing
Overall system availability
System-Wide Metrics:
Request success rates over time
Average response times
Error rate trends
Traffic patterns
Production Considerations
Fault Tolerance Tuning
Circuit Breaker Thresholds: Start with 50% error rate over 10 requests. Adjust based on your service's normal error patterns.
Retry Policies: Use exponential backoff with jitter. Maximum of 3 retries for user-facing requests, more for background jobs.
Timeout Values: Set to 3x your 95th percentile response time. Monitor and adjust based on real traffic patterns.
High Availability Configuration
Health Check Frequency: Every 10-30 seconds for most services. More frequent for critical services, less for stable ones.
Instance Count: Minimum 3 instances across 2 availability zones. Scale based on traffic and redundancy requirements.
Load Balancer Algorithms: Round-robin for stateless services, sticky sessions for stateful ones.
Cleanup
When you're done exploring:
bash
./cleanup.shThis stops all containers, removes images, and cleans up the project directory.
Key Takeaways
Fault Tolerance and High Availability solve different problems and work best together:
Fault tolerance handles unexpected failures within services through retries, circuit breakers, and graceful degradation
High availability ensures service accessibility through redundancy, load balancing, and automatic failover
Modern systems need both patterns working together for true resilience
Implementation details matter—proper timeouts, health checks, and monitoring are critical for production success
The next time you design a distributed system, remember: fault tolerance makes your services resilient, but high availability keeps your users happy. Design for both, test regularly, and monitor everything.
Next Week: Issue #114 explores Redundancy Patterns in System Design, diving deep into the implementation details of the high availability strategies we introduced today.
Build This: Use our hands-on demo to experience both patterns in action. You'll see circuit breakers, retries, and load balancer failover working together in a realistic microservices environment.