
Geospatial System Design Patterns
When Location Becomes Your Biggest Challenge
When Uber’s engineering team realized their location queries were taking 800ms during peak hours in New York City, they discovered that traditional database indexes simply don’t work for spatial data. A user requesting nearby drivers was scanning millions of records, bringing their entire matching system to its knees. This wasn’t a code problem—it was a fundamental architectural challenge that required rethinking how location data flows through distributed systems.
Today you’ll master the patterns that power location-aware systems at hyperscale, understanding why companies like Google Maps, DoorDash, and Pokemon GO architect their geospatial systems so differently.
What You’ll Learn:
Spatial indexing strategies that scale to billions of points
Geofencing patterns that handle millions of concurrent checks
Real-time location tracking without overwhelming your infrastructure
Why traditional sharding breaks with geographic data
The Hidden Complexity of “Nearby”
The innocent query “find nearby restaurants” becomes exponentially complex at scale. Traditional B-tree indexes excel at range queries on single dimensions, but spatial queries require multidimensional range searches across latitude and longitude simultaneously.
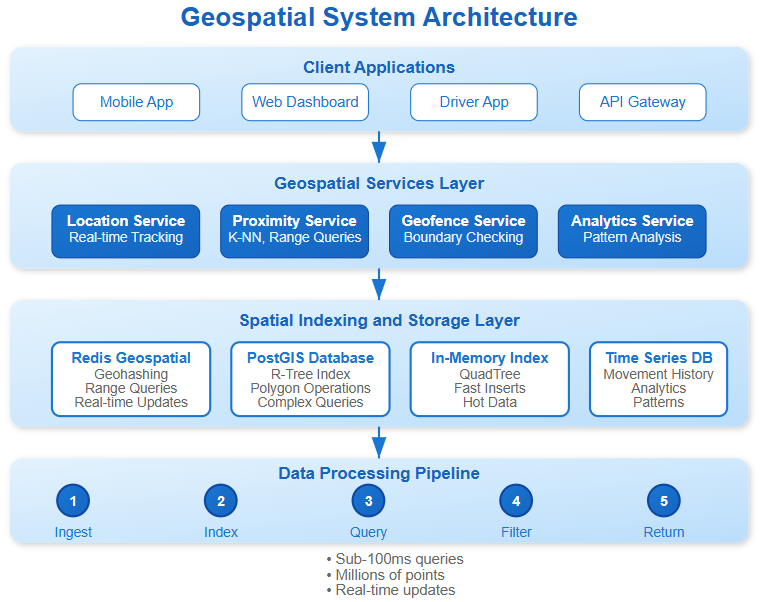
Spatial Indexing: Beyond Traditional Approaches
R-Trees partition space hierarchically, grouping nearby objects into bounding rectangles. Each node represents a spatial region, with children containing smaller regions within their parent’s bounds. This structure excels for range queries but struggles with high write throughput due to tree rebalancing overhead.
QuadTrees recursively divide 2D space into quadrants, creating a pyramid of spatial regions. Instagram uses QuadTrees for photo geotagging because insertions are faster than R-Trees, though range queries can be less efficient for sparse data.
Geohashing converts 2D coordinates into 1D strings by interleaving latitude and longitude bits. Base32 encoding creates human-readable strings where spatial proximity often correlates with string similarity. Redis uses geohashing for its spatial commands because it leverages existing sorted set data structures.
The non-obvious insight: choose indexing based on your read/write ratio. High-write systems like real-time tracking benefit from simpler structures like geohashing, while read-heavy systems like POI search optimize for R-Tree complexity.
Enterprise Patterns: Learning from Scale
Uber’s Proximity Engine
Uber’s RINGPOP architecture uses consistent hashing with geographic partitioning. Instead of random hash distribution, they partition cities into geographic regions, ensuring location queries hit only relevant shards. The breakthrough insight: geographic data locality enables predictable sharding.
Their system maintains separate indexes for different entity types (drivers, riders, restaurants) because update frequencies differ dramatically. Drivers update location every 4 seconds, while restaurants are nearly static.
Google Maps: Hierarchical Spatial Caching
Google’s approach layers multiple indexing strategies. Country-level data uses R-Trees for complex polygon intersections, city-level uses QuadTrees for fast point queries, and street-level uses linear referencing systems for routing. Each layer caches at different granularities, enabling global scale with local performance.
The counterintuitive pattern: they intentionally duplicate data across indexes. A restaurant exists in the POI index, the business listing index, and the review aggregation index. This denormalization enables independent scaling of different query patterns.
Pokemon GO: Real-Time Geofencing at Scale
Niantic handles 500M+ geofence checks daily using a hybrid approach. Static geofences (city boundaries, restricted areas) use precomputed spatial indexes, while dynamic geofences (events, temporary restrictions) use real-time computation with aggressive caching.
Their key insight: separate hot and cold geofences. Frequently-checked areas get in-memory spatial indexes, while rarely-accessed regions use database-backed queries with longer cache TTLs.
Critical Performance Patterns
The Precision vs. Performance Trade-off
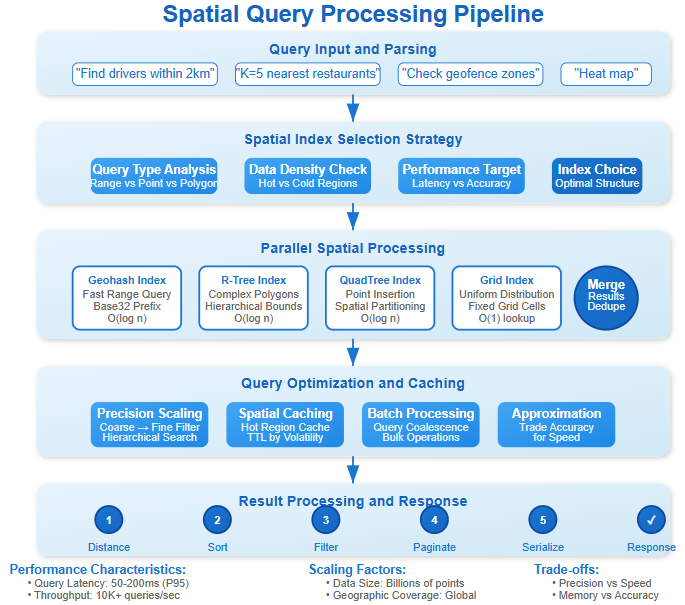
Geohashing precision directly impacts query performance. 5-character geohashes (±2.4km precision) enable fast neighbor finding but require querying 9 adjacent cells for comprehensive results. 8-character hashes (±19m precision) provide accuracy but explode query complexity.
Production systems use hierarchical precision: initial queries use coarse hashes for fast filtering, then refine with precise calculations for the final result set.
Avoiding the Geographic Hot Spot Problem
Traditional sharding by location creates hot spots in dense areas. Manhattan’s financial district might overwhelm a single shard while rural Wyoming sits nearly empty.
Solution Pattern: Adaptive spatial partitioning that considers both geography and data density. Split dense regions into smaller shards while merging sparse areas. Foursquare’s implementation uses k-means clustering on historical query patterns to determine optimal boundaries.
Real-Time Location Updates Without Overload
Location updates follow power-law distributions—some users move constantly while others remain stationary. Naive approaches flood the system with redundant updates.
Intelligent Update Patterns:
Movement-based: Only update when displacement exceeds threshold
Time-decay: Reduce update frequency for stationary objects
Context-aware: Higher frequency during rides/deliveries, lower when static
DoorDash reduces location updates by 70% using movement detection algorithms that distinguish between actual movement and GPS jitter.
Implementation Strategy: Building Your Geospatial System
Github Link:
https://github.com/sysdr/sdir/tree/main/geospatial_system_design/geospatial-demoData Layer Design
# Spatial index selection based on access patterns
class SpatialDataRouter:
def __init__(self):
self.rtree_index = RTreeIndex() # Complex queries
self.quadtree_index = QuadTreeIndex() # Fast inserts
self.geohash_index = GeohashIndex() # Range queries
def choose_index(self, query_type, data_density):
if query_type == “range” and data_density == “high”:
return self.rtree_index
elif query_type == “insert_heavy”:
return self.quadtree_index
else:
return self.geohash_index
Geofencing at Scale
Efficient geofencing requires pre-computation and spatial acceleration structures. Instead of checking every fence for every location update, maintain reverse indexes mapping geographic regions to relevant fences.
Cross-Region Synchronization
Global location services face consistency challenges when users cross geographic boundaries. Eventual consistency works for most location data, but safety-critical applications (emergency services) require stronger guarantees.
Pattern: Use geographic boundaries as consistency boundaries. Maintain strong consistency within regions while accepting eventual consistency across regions.
Production Insights: The Devil in the Details
Memory Management for Spatial Indexes
Spatial indexes consume significantly more memory than traditional indexes due to bounding box overhead. R-Trees typically require 3-5x more memory than equivalent B-trees. Budget memory accordingly and consider disk-based spatial indexes for cold data.
Geographic Coordinate Precision
Storing full double-precision coordinates (16 bytes) is wasteful for most applications. 32-bit integers provide ~1cm precision globally, sufficient for virtually all use cases while halving storage costs.
Time Zone Complexity
Location-aware systems must handle time zone transitions carefully. A user’s “nearby” query at 9 PM might cross time zones where businesses have different operating hours. Pre-compute time zone boundaries and factor into business logic.
Your Next Challenge: Build a Location Intelligence Platform
Project Goal: Create a system that handles real-time location tracking, geofencing, and proximity queries for a delivery service.
Core Requirements:
Track 10,000+ delivery drivers with 4-second update intervals
Support geofenced delivery zones with dynamic boundaries
Find nearest available drivers within 5km of customer locations
Handle geographic hot spots without performance degradation
Success Metrics:
Sub-100ms proximity query response times
Support 1,000+ concurrent location updates
99.9% uptime during peak hours
Horizontal scaling across multiple cities
Working Code Demo:
This project will expose you to the real challenges of geospatial systems: managing memory-intensive spatial indexes, handling uneven geographic data distribution, and optimizing for both read and write workloads simultaneously.
The patterns you learn here directly apply to any location-aware application, from social media check-ins to IoT device tracking to autonomous vehicle coordination.
Start building, and you’ll discover why geographic data requires fundamentally different architectural thinking than traditional business applications.
Next week in Issue #146, we’ll explore Recommendation Systems at Scale, where geographic patterns become one input into complex machine learning pipelines that must process billions of user interactions in real-time.