


Global Load Balancing Strategies
Issue #99:System Design Interview Roadmap

What We'll Learn Today
Multi-region load balancer simulator with geographic routing
Health monitoring dashboard showing failover strategies
Latency-based traffic distribution with real-time metrics
DNS resolution patterns demonstrating anycast behavior
The Hidden Complexity of Global Traffic Distribution
When Netflix streams to 230 million users worldwide, a single DNS query triggers a sophisticated decision tree involving geographic proximity, server capacity, network conditions, and content availability. This isn't simple round-robin distribution—it's intelligent traffic orchestration that can make or break user experience at global scale.
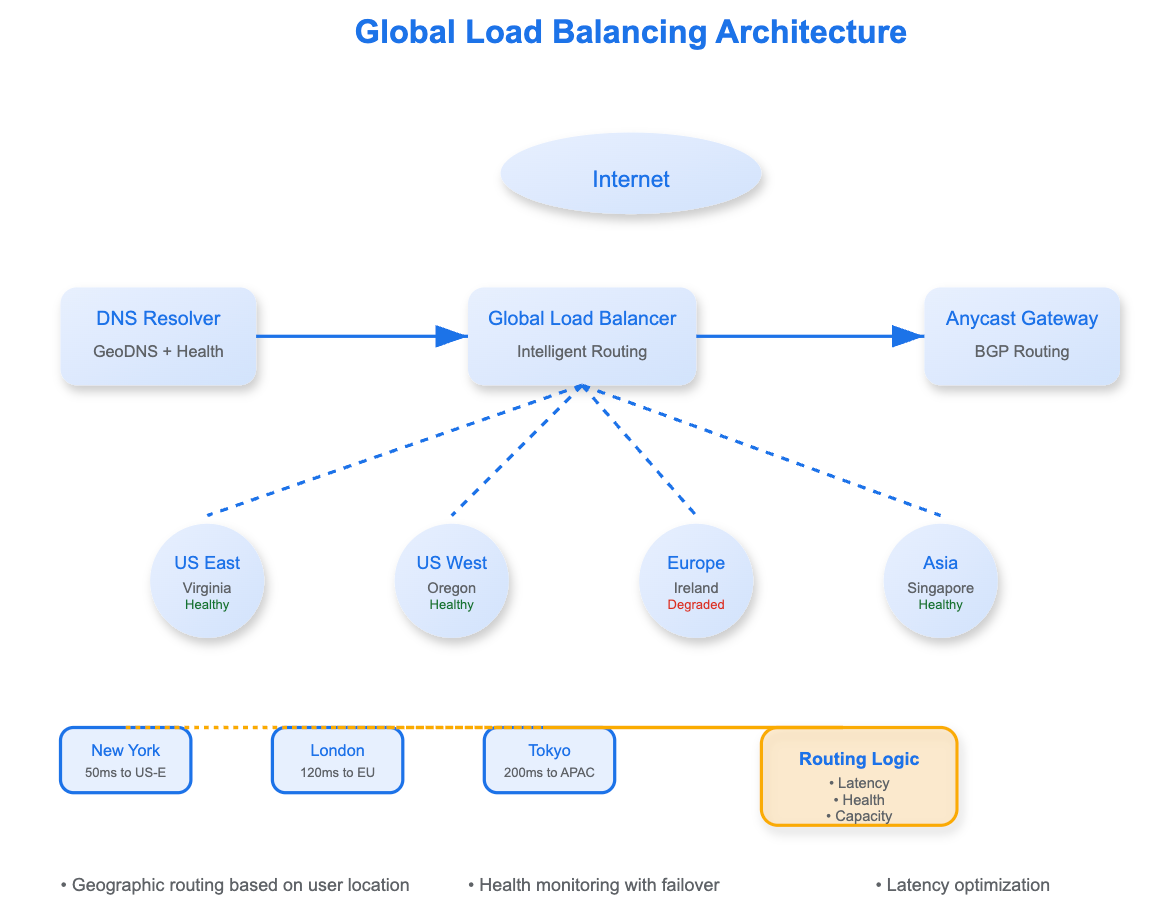
📊 [Global Load Balancing Architecture]
Most engineers understand load balancing within a data center, but global load balancing introduces unique challenges: cross-continental latencies, regulatory data residency requirements, submarine cable failures, and the physics of light speed through fiber optic networks.
Core Global Load Balancing Strategies
DNS-Based Geographic Routing
The foundation of global load balancing lies in DNS resolution intelligence. When a user queries api.company.com, authoritative name servers return different IP addresses based on the client's geographic location.
GeoDNS Implementation Insight: Major providers like Cloudflare and AWS Route 53 maintain global databases mapping IP address ranges to geographic regions. However, the accuracy varies significantly—mobile carrier networks and VPN usage can misplace users by thousands of miles.
Production Reality: Spotify discovered that 15% of their DNS-based routing decisions were geographically incorrect due to corporate VPNs and mobile roaming. Their solution combines GeoDNS with application-layer geo-detection for fallback routing.
Anycast Network Architecture
Anycast allows multiple servers to share the same IP address, with network routing protocols directing traffic to the "nearest" instance based on BGP (Border Gateway Protocol) metrics.
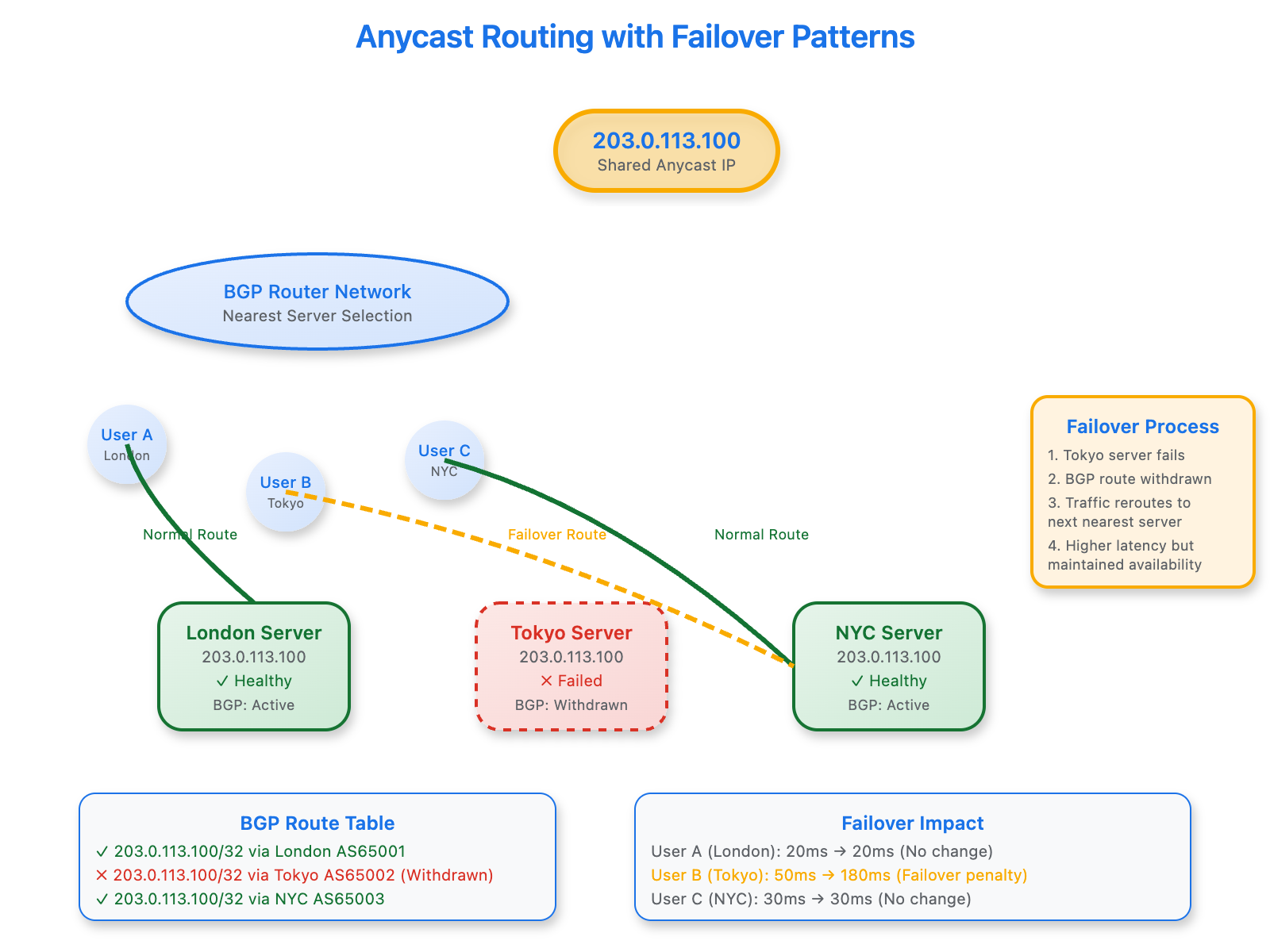
📊 [Anycast Routing with Failover Patterns]
The Non-Obvious Insight: Anycast "nearness" doesn't always correlate with physical proximity. BGP routing decisions consider network topology, not geographic distance. A user in Chicago might reach a server in Dallas instead of nearby Cleveland due to internet routing policies.
Enterprise Case Study: Cloudflare's global CDN uses anycast for their edge network, but they learned that during DDoS attacks, anycast can inadvertently concentrate malicious traffic on specific data centers. Their mitigation involves selective BGP announcements that temporarily make certain nodes "unreachable" to redistribute attack traffic.
Latency-Based Intelligent Routing
Advanced global load balancers continuously measure round-trip times from various global locations to each data center, dynamically routing traffic to minimize latency.
Implementation Complexity: AWS Route 53's latency-based routing performs health checks from 15+ global probe locations every 30 seconds. The routing decisions use a weighted algorithm that considers both latency and server health, not just the fastest response time.
Hidden Failure Mode: During network congestion, latency measurements can become unreliable. Amazon's solution involves composite health metrics that factor in sustained latency trends over rolling time windows rather than instantaneous measurements.
Advanced Enterprise Patterns
Multi-Layer Failover Hierarchies
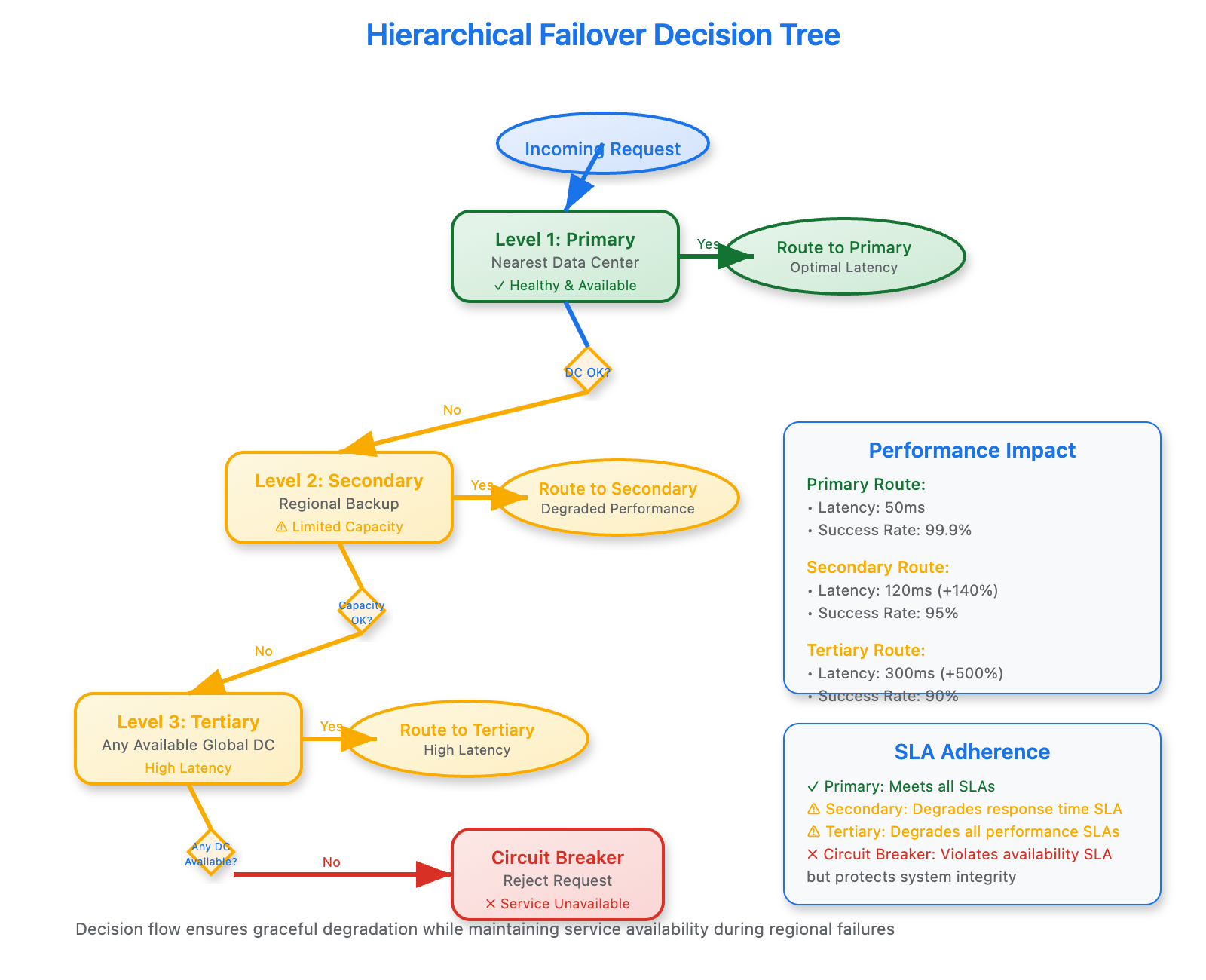
📊 [Hierarchical Failover Decision Tree]
Production-grade global load balancing implements multiple failover layers:
Primary: Route to nearest healthy data center
Secondary: Fallback to regional backup with capacity constraints
Tertiary: Emergency routing to any available global location
Circuit Breaker: Reject traffic when no healthy backends exist
Netflix's Implementation: Their Zuul gateway implements a sophisticated failover hierarchy. During the 2019 AWS outage, traffic automatically shifted from us-east-1 to us-west-2, then to European regions as capacity filled up. The system maintained 99.9% availability despite losing their primary region.
Cross-Region Data Consistency Challenges
Global load balancing exposes data consistency issues that don't exist in single-region deployments. Users might be routed to different regions mid-session, encountering stale data or missing state.
Google's Solution: Their global load balancer includes session affinity mechanisms that hash user identifiers to preferred regions while maintaining fallback capabilities. Critical for services like Gmail where inbox state must remain consistent.
Trade-off Insight: Session affinity improves consistency but reduces failover agility. Google's compromise involves "soft affinity"—preferential routing with automatic fallback when health degrades.
Production Implementation Insights
Health Check Sophistication
Simple ping tests are insufficient for global load balancing. Production systems implement multi-dimensional health checks:
Application-layer validation: Verify database connectivity and critical service dependencies
Capacity-aware scoring: Factor current load and available headroom into routing decisions
Synthetic transaction monitoring: Execute representative user workflows to validate end-to-end functionality
Uber's Approach: Their global platform uses synthetic ride requests to validate the complete booking pipeline across regions. A data center showing healthy ping responses but failing synthetic bookings gets removed from rotation.
Regulatory and Compliance Considerations
Data Residency Requirements: GDPR, data sovereignty laws, and industry regulations restrict where user data can be processed. Global load balancers must incorporate compliance routing rules.
Implementation Pattern: Maintain separate pools of compliant infrastructure and use DNS policies that consider both user location and data classification to ensure regulatory compliance.
Real-World Interview Insights
Common Question: "How would you handle a global service outage affecting 50% of your data centers?"
Expert Answer Framework:
Immediate: Activate remaining capacity with admission control to prevent overload
Short-term: Implement graceful degradation—disable non-critical features to preserve core functionality
Medium-term: Coordinate with CDN providers for additional edge capacity
Long-term: Analyze failure patterns and improve geographic distribution strategy
Follow-up Insight: Discuss the difference between "fail-open" vs "fail-closed" strategies. E-commerce might fail-open (degraded experience) while financial services fail-closed (reject requests rather than risk data corruption).
Build This: Global Load Balancer Simulator
Our demo creates a realistic global load balancing environment with:
4 simulated regions (US-East, US-West, Europe, Asia)
Health monitoring with configurable failure injection
Geographic latency simulation based on real-world measurements
Interactive dashboard showing routing decisions and performance metrics
🚀 Quick Start
git clone https://github.com/sysdr/sdir.git
git checkout global_load_balancing
cd global_load_balancing/cd global_load_balancing/
# Download and run the demo
chmod +x start.sh stop.sh
./start.sh
# Access the dashboard
open http://localhost:5000
# Clean up when done
./stop.sh🎯 Learning Outcomes
After working through this material, you'll understand:
How global CDNs route traffic across continents
Why geographic "nearest" doesn't always mean lowest latency
How to implement graceful degradation in distributed systems
Production patterns used by major cloud providers
Interview-ready explanations of global load balancing trade-offs
The demo provides hands-on experience with concepts that are typically only understood theoretically, making this an excellent preparation tool for both interviews and real-world system design decisions.
The implementation demonstrates production patterns used by AWS Route 53, Cloudflare, and Google Cloud Load Balancer, giving you hands-on experience with enterprise-grade global traffic management.
Next Steps: After mastering these concepts, implement geographic routing in your current project's infrastructure. Even simple GeoDNS can reduce global latency by 40-60% for geographically distributed users.
Next week in Issue #100: Autoscaling Strategies and Algorithms—we'll explore predictive scaling, custom metrics, and the mathematical models behind intelligent capacity management.