
Handling Late Data and Watermarks: Accuracy in Real-Time Stream Processing
The Hidden Cost of Speed
You’re running a real-time analytics dashboard tracking user clicks across 50 million daily active users. Events flood in from mobile apps, web browsers, and IoT devices worldwide. Your system computes click-through rates every 10 seconds with impressive sub-second latency. Then your VP notices something odd: yesterday’s hourly report shows 2% more clicks than the real-time dashboard reported. Where did those extra clicks come from?
Welcome to the late data problem—the silent accuracy killer in stream processing systems. Those “missing” clicks arrived late, after your system already computed and published results. Your dashboard was fast but wrong. This is where watermarks become your precision instrument for balancing speed against completeness.
What Watermarks Actually Do
A watermark is a timestamp assertion flowing through your stream that declares: “I’ve seen all events with timestamps up to time T.” It’s not just metadata—it’s a promise about data completeness that triggers computations.
Think of watermarks like airport security checkpoints. A checkpoint at 2:00 PM means “all passengers for the 2:15 PM flight should have passed through by now.” Passengers (events) arriving at 2:30 PM for that 2:15 PM flight are late arrivals. The checkpoint (watermark) helps the airline decide: do we hold the plane or leave without them?
Stream processors use watermarks to answer: “When is it safe to compute a result for time window W?” Without watermarks, you face an impossible choice—wait forever for potentially late data (infinite latency) or compute immediately (miss late data, get wrong answers).
Here’s the mechanism: As events flow through your system, the processor tracks timestamps and periodically emits watermarks. When a watermark reaches time T, it triggers computation for all windows ending before T. A 10-second tumbling window from 14:00:00 to 14:00:10 fires when the watermark advances past 14:00:10.
The critical insight: watermarks decouple event time (when something happened) from processing time (when you learned about it). Events carry timestamps from when they occurred. Watermarks advance based on observed event timestamps, not wall-clock time. This separation enables accurate computations despite network delays, clock skew, and mobile devices reconnecting after hours offline.
Allowed lateness extends this further. After a watermark triggers a window’s computation, you might still accept late data for another 5 minutes, updating already-published results. It’s like the airline sending an email: “Flight departed, but we’ll add you to the next one automatically.”
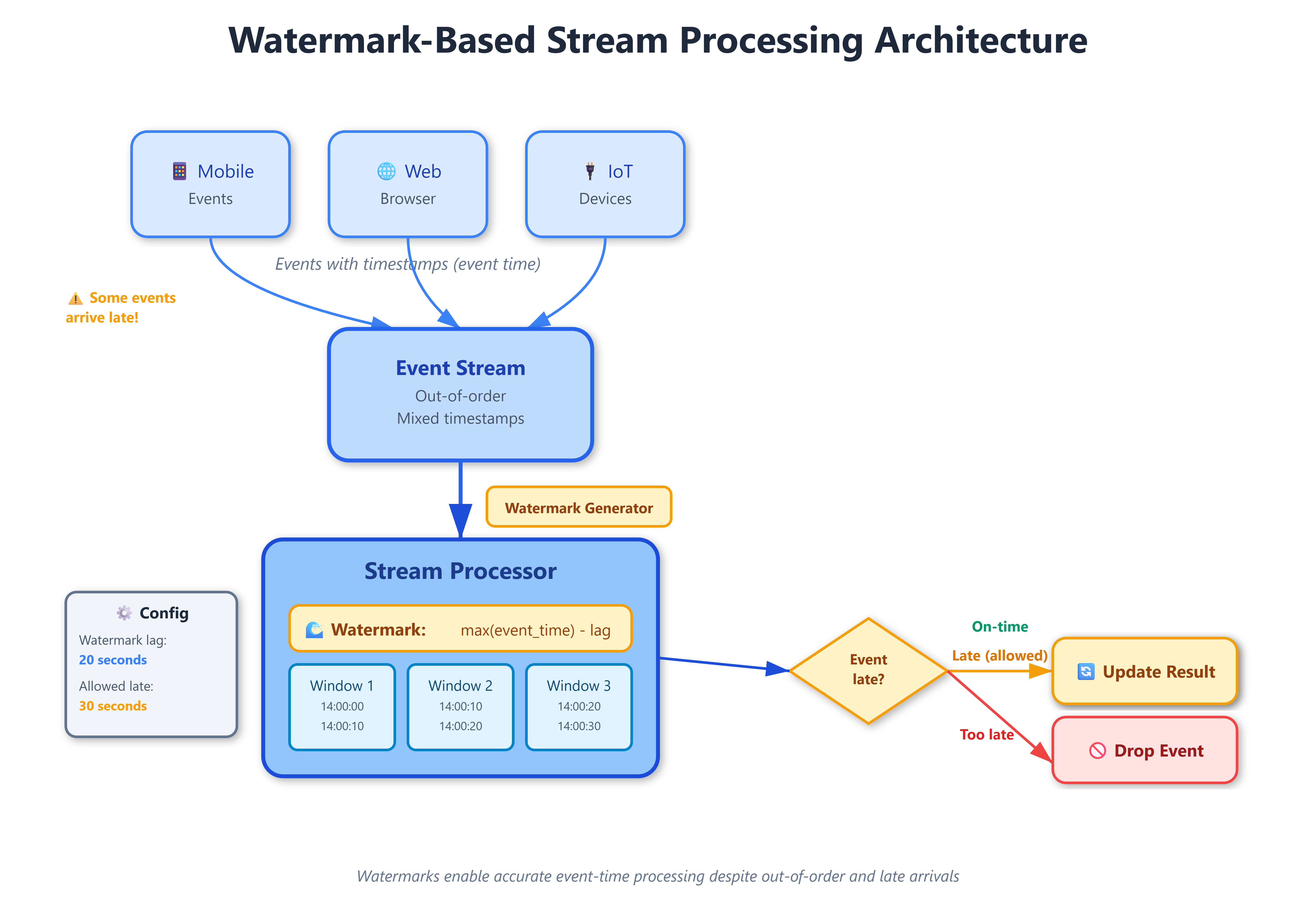
The watermark generation strategy determines accuracy vs. latency:
Perfect watermarks guarantee no late data ever arrives after the watermark passes. Achievable only when you control all event sources and can track maximum delays precisely. Netflix uses this for internal microservice streams where they instrument every producer.
Heuristic watermarks advance based on observed patterns—like “watermark = max observed timestamp - 30 seconds.” Trades strict correctness for practical latency. Most production systems use this approach because perfect watermarks often require unacceptable delays.
Punctuated watermarks rely on explicit signals from data sources. When Kafka partition reaches end-of-log, it emits a watermark. Useful for bounded datasets masquerading as streams.
Critical Insights You Won’t Find Elsewhere
Common knowledge: Watermarks solve out-of-order data. Late events get dropped or trigger retractions.
Rare insight #1:
Watermark lag amplifies downstream. If service A has 10-second lag and B has 15-second lag, their join might need 25-second watermark lag. This cascading effect means your system’s end-to-end latency often depends on your slowest event source, not your average source. Production systems at Uber discovered that a single struggling mobile region delayed global analytics by minutes.
Rare insight #2:
Watermark advancement stalls cause memory explosions. State for “open” windows accumulates in memory. If watermarks stop advancing (stuck producer, network partition), windows never close, and memory usage grows unbounded until OOM kills your job. Apache Flink jobs have crashed holding 50GB+ of state for windows that should’ve closed hours ago.
Advanced insight #3:
Clock skew between producers creates phantom late data. Two servers with 5-second clock difference produce events that appear 5 seconds apart even if simultaneous. Your watermark strategy must account for NTP drift. Google Spanner uses TrueTime (GPS + atomic clocks) partly to avoid this problem in globally distributed streams.
Strategic impact: Allowed lateness creates dual versions of truth. You publish result R1 at watermark time, then R2, R3... as late data arrives. Downstream consumers must handle updates or decide which version to trust. Financial systems often reject this complexity and use perfect watermarks with high latency instead.
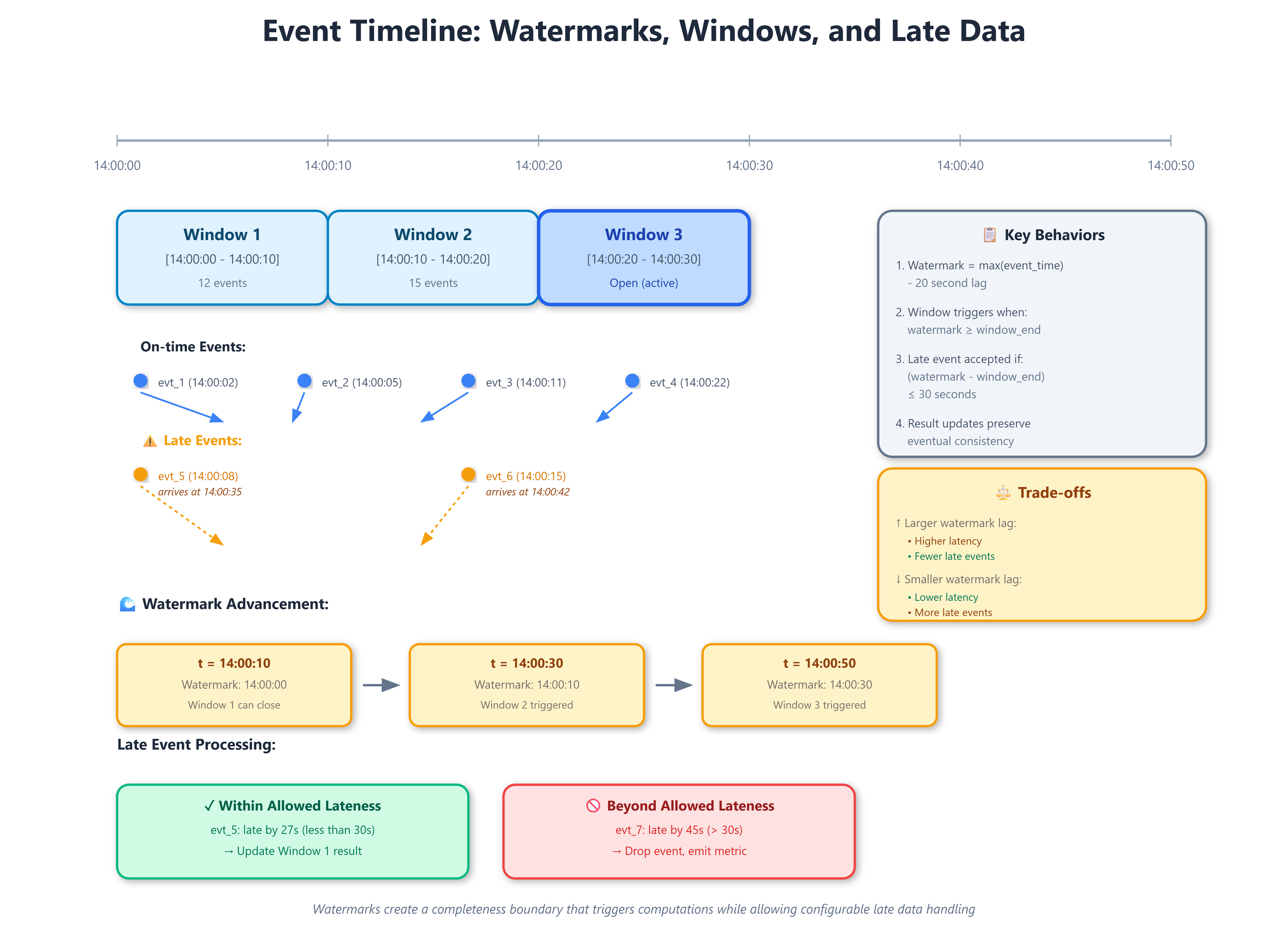
Implementation nuance #4: Session windows interact pathologically with watermarks. A user’s 30-minute inactivity session might not close for 30 minutes after their last event. If that last event arrives late, you’re 30 minutes behind real-time. Spotify’s recommendation system combats this with speculative session closure and retroactive corrections.
Esoteric behavior #5: Watermark alignment in multi-input operators creates deadlocks. Consider a join of streams A and B. If A’s watermark advances to T=100 but B stalls at T=50, the join can’t make progress—it’s waiting for B to catch up. Your job appears hung despite one stream flowing normally. The solution requires watermark synchronization protocols that most engineers never see in documentation.
How The Giants Handle Late Data
LinkedIn’s Brooklin processes 2 trillion events daily across their entire infrastructure. They use dynamic watermark strategies that adjust lag based on observed late arrival patterns. For critical metrics like ad impressions, they combine 5-second heuristic watermarks for speed with 1-hour allowed lateness for accuracy, publishing preliminary results fast then corrections asynchronously. Their debugging insight: watermark metrics (lag, advancement rate) correlate better with job health than CPU or memory.
Stripe’s payment processing demands exactly-once semantics with audit trails. They use punctuated watermarks from database change streams where each transaction log position represents a perfect watermark. When processing refunds, they implement zero allowed lateness—late refund events cause alerts, not automatic reprocessing. This trade-off prioritizes auditability over automatic correction.
Twitter’s real-time trends faces extreme spikes during breaking news. They use adaptive watermarks that tighten during normal periods (30-second lag) but expand during traffic surges (5-minute lag) to prevent dropped data. The trend calculation uses allowed lateness with exponential decay—events arriving within 1 minute get full weight, 1-5 minutes get 50% weight, >5 minutes get dropped. This degrades gracefully rather than failing binary.
Architectural Integration
GitHub Link
https://github.com/sysdr/sdir/tree/main/Handling_late_data_and_Watermarks/watermark-demoWatermarks aren’t just a stream processing concern—they ripple through your entire architecture. Your monitoring must track watermark lag as a first-class SLO. When lag exceeds thresholds, you’re choosing between data loss and latency violations. This metric often predicts outages before error rates spike.
Debugging late data requires distributed tracing that preserves original event timestamps through every transformation. Production issues often stem from timezone conversions, serialization bugs, or retry logic that modifies timestamps. Without end-to-end timestamp lineage, you’re debugging blind.
Cost implications surprise teams. Allowed lateness means maintaining state longer. A 1-hour allowed lateness on 1TB/hour data means storing 1TB of state for potential updates. RocksDB disk I/O costs real money at scale. Teams often discover that reducing allowed lateness from 1 hour to 10 minutes cuts infrastructure costs 20%.
Use watermarks when: correctness matters more than latency, data sources can’t guarantee order, and you need to reason about event time vs. processing time separately.
Avoid watermarks when: processing time semantics suffice, all data arrives in order with bounded delay, or you’re willing to reprocess entire datasets for corrections.
Master This Concept
The watermark pattern appears in every major streaming framework—Flink, Spark Structured Streaming, Kafka Streams, Beam. Understanding it deeply transforms you from someone who configures stream processors to someone who architects resilient real-time systems.
Run bash setup.sh to launch a complete demonstration. You’ll see a stream of e-commerce events (page views, add-to-carts, purchases) flowing through a processing pipeline with configurable watermark lag and allowed lateness. The dashboard visualizes:
Events arriving in real-time with their event timestamps
Watermark advancement (the “completeness boundary”)
Windows triggering computations when watermarks pass
Late events arriving after window computation
Result corrections when allowed lateness is enabled
Experiment by introducing network delays to see late data patterns emerge. Adjust watermark lag and observe the accuracy vs. latency trade-off. Most importantly, intentionally stall watermarks by pausing a producer and watch state accumulate—this controlled chaos teaches you what to monitor in production.
The goal isn’t just understanding watermarks intellectually. You should be able to debug production issues like “why did yesterday’s revenue report change overnight?” (late data arrived within allowed lateness) or “why is my stream job stuck?” (watermark stall preventing progress). These scenarios define the difference between engineers who use streaming frameworks and engineers who master them.
When you can explain to your team exactly how much latency you’re trading for accuracy and why, you’ve achieved true mastery of this concept. That precision is what separates $100M infrastructure bills from $10M ones.