High-Frequency Trading Architecture: Kernel Bypass, DPDK, and Ultra-Low Latency
The Microsecond Advantage
In high-frequency trading, a single microsecond can mean the difference between a profitable trade and a loss. When you’re competing with thousands of other algorithms for the same arbitrage opportunity, the speed of your network stack matters more than your trading strategy. Traditional operating systems add 20-50 microseconds of latency just moving packets through the kernel. For context, light travels only 6 kilometers in 20 microseconds. This is why elite HFT firms bypass the kernel entirely, talking directly to network cards and processing millions of packets per second with sub-microsecond jitter.
How Kernel Bypass and DPDK Work
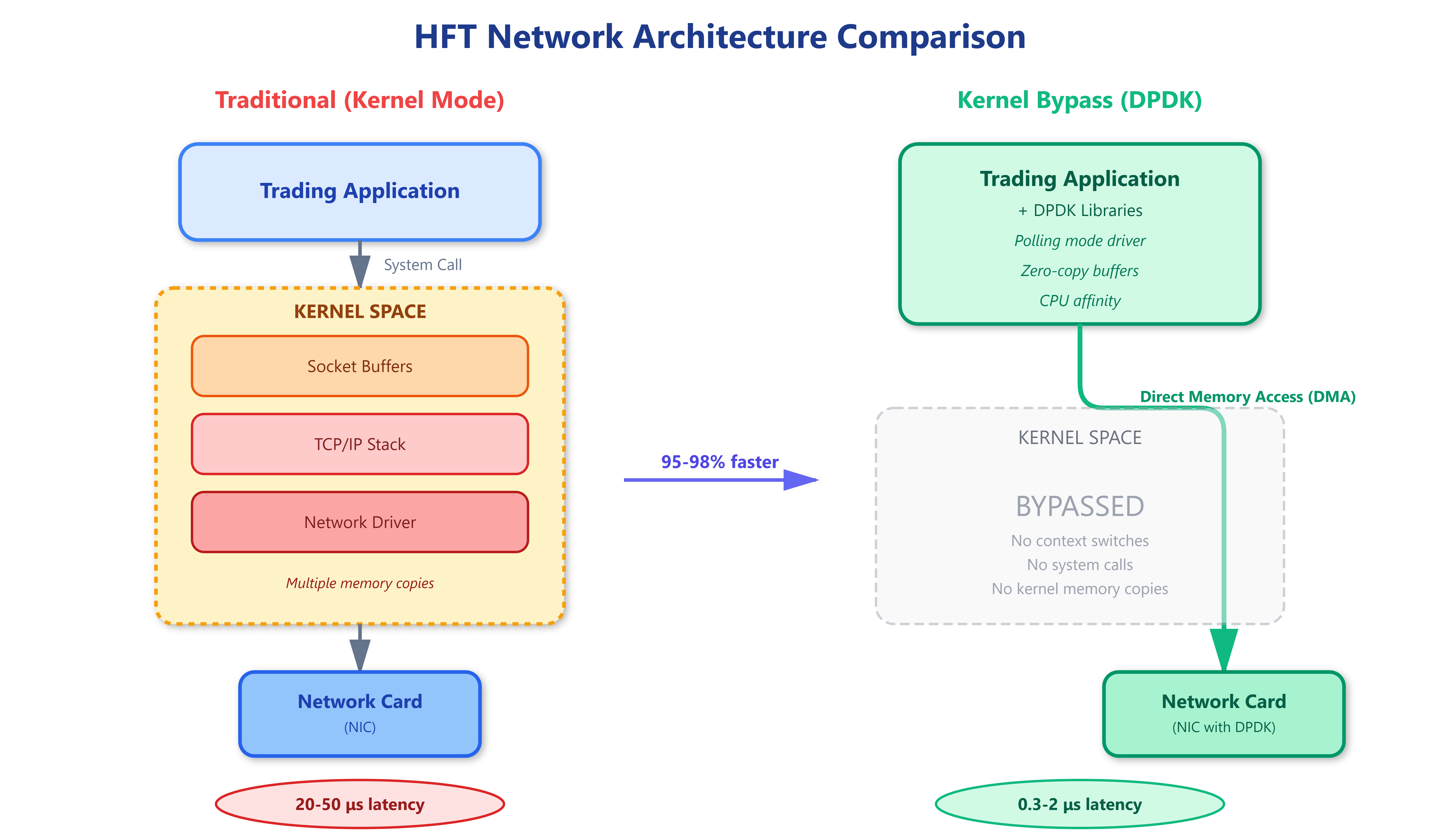
Traditional network processing routes every packet through the operating system kernel. Your application makes a system call, the kernel switches context from user space to kernel space, processes the packet through multiple layers (TCP/IP stack, socket buffers, network drivers), copies data between kernel and user memory, then context-switches back. Each step adds latency and unpredictability.
Kernel bypass eliminates this overhead by giving your application direct access to the network card’s receive and transmit queues. Technologies like DPDK (Data Plane Development Kit) map the NIC’s memory directly into your application’s address space using huge pages and memory-mapped I/O. Your code polls the receive queue continuously in a tight loop, processing packets the moment they arrive without any kernel involvement.
DPDK works by taking exclusive control of specific CPU cores and network ports. These cores run in polling mode—they never sleep, never context switch, and never share CPU time with other processes. The network card uses DMA (Direct Memory Access) to write incoming packets directly into pre-allocated memory buffers that your application owns. When you want to send a packet, you write it to a transmit buffer and update a ring buffer pointer. The NIC reads from this ring buffer using DMA and transmits packets without CPU intervention.
The magic happens through several key mechanisms. First, huge pages (2MB or 1GB instead of 4KB) reduce TLB misses by 99%, meaning address translation happens in nanoseconds instead of microseconds. Second, cache-aware data structures keep packet descriptors and buffers in L1/L2 cache. Third, CPU affinity pins threads to specific cores, eliminating scheduling delays. Fourth, interrupt-free polling means zero context switches—your code continuously checks for new packets instead of waiting for interrupts.