
How Circular Dependencies Kill Your Microservices
Our payment service was down. Not slow—completely dead. Every request timing out. The culprit? A circular dependency we never knew existed, hidden five service hops deep. One team added a “quick feature” that closed the circle, and under Black Friday load, 300 threads sat waiting for each other forever.
The Problem: A Thread Pool Death Spiral
Here’s what actually happens: Your user-service calls order-service with 10 threads available. Order-service calls inventory-service, which needs user data, so it calls user-service back. Now all 10 threads in user-service are blocked waiting for order-service, which is waiting for inventory-service, which is waiting for those same 10 threads. Deadlock. Game over
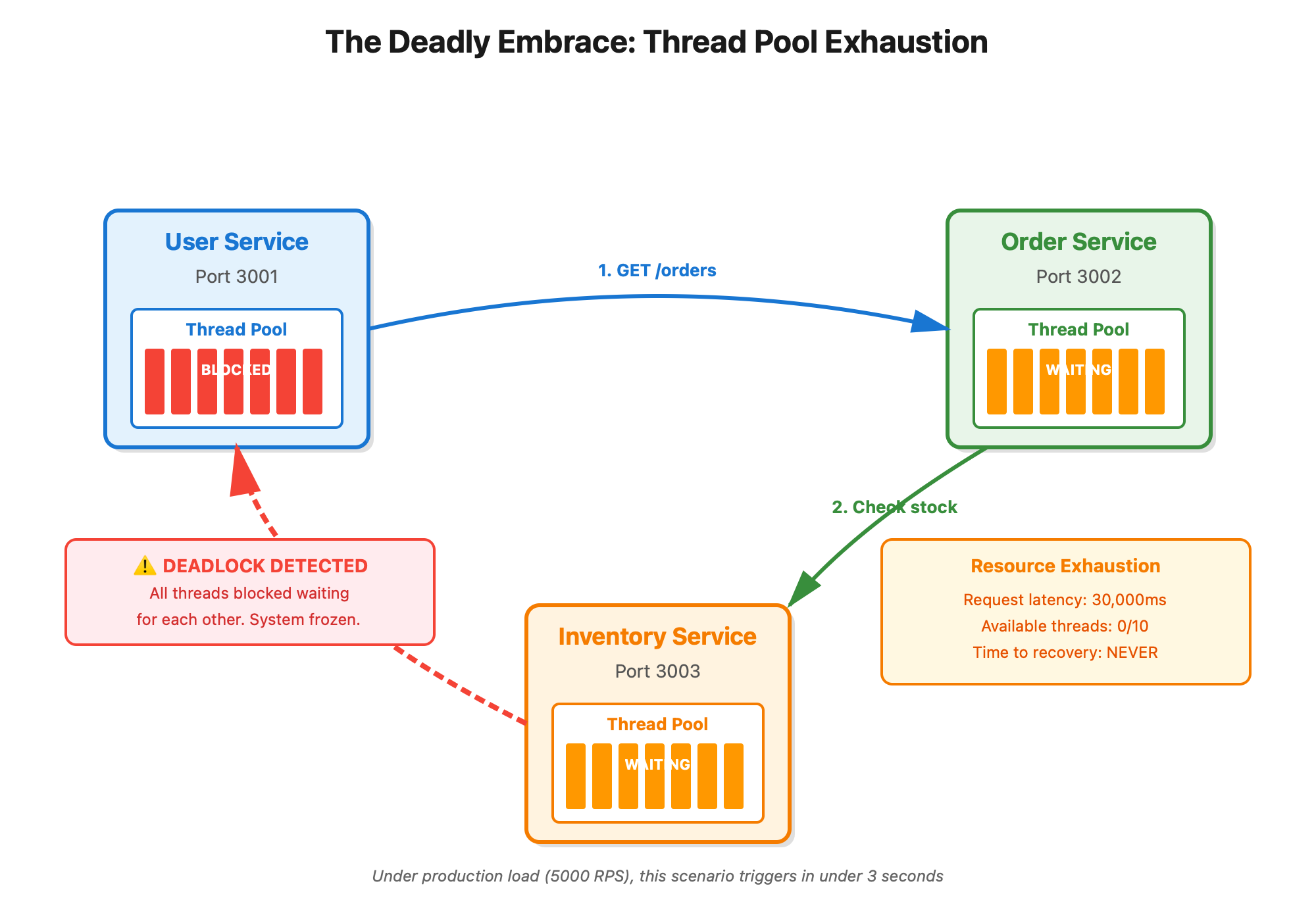
.
The terrifying part? This works fine in staging with 5 requests per second. At 5,000 RPS in production, your thread pools drain in under 3 seconds.
What Nobody Tells You
Circles hide in plain sight. I’ve seen companies with pristine architecture diagrams showing zero circular dependencies, while their production runtime created circles through feature flags. Service A calls Service B’s v2 endpoint only for premium users, and v2 calls Service C, which calls A. Your dependency graph is a lie.
The “works until it doesn’t” trap. Synchronous circular calls succeed under low load because requests complete before resource exhaustion. This creates a production time bomb. You won’t find it in testing.
Request amplification is brutal. One user request enters the circle. With retries (3 attempts per service × 3 services), that’s 27 requests spinning in your system. Now multiply by 1,000 concurrent users. Your logs show millions of requests from one endpoint.
Cross-team blindness. Team X owns Service A, Team Y owns Service B, Team Z owns Service C. Nobody sees the full picture. I’ve debugged circles where three teams insisted their service was “just calling one other service”—all pointing fingers in a literal circle.
Detection: Request IDs Are Your Best Friend
The only reliable way to catch circles: distributed tracing with request IDs. In 2025, OpenTelemetry is the standard. Every request gets a unique ID that propagates through all service calls. When Service A sees its own request ID coming back, you’ve found your circle
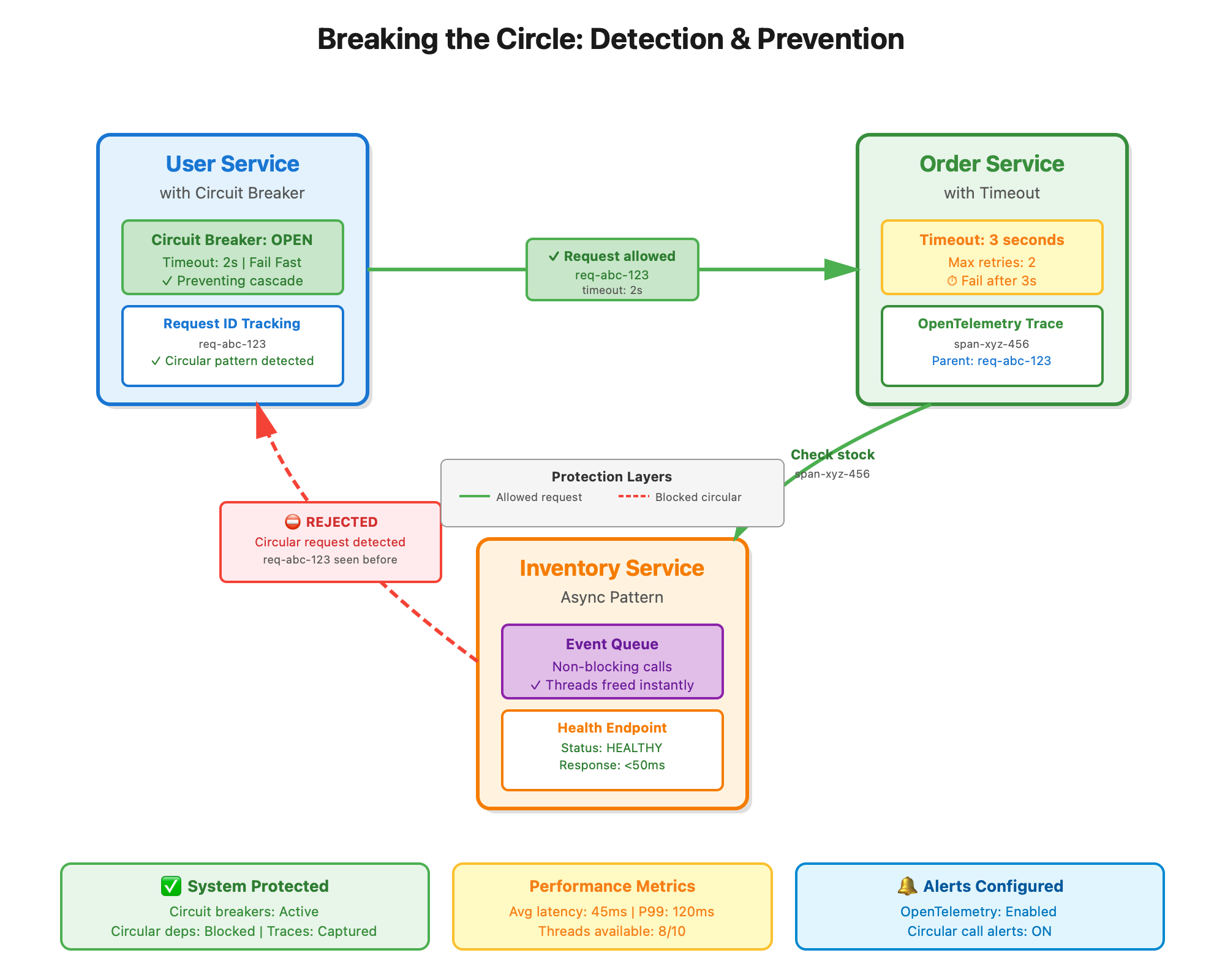
Better yet, implement runtime checks. If your service sees the same request ID twice, reject it immediately and log it. This saved us from three outages last quarter.
eBPF-based tools can now detect circular calls at the kernel level without code changes. Service meshes like Istio have built-in warnings. Use them.
Breaking the Circle
Circuit breakers are non-negotiable. When Service B starts timing out, your circuit breaker opens and fails fast instead of waiting. This breaks the circle and prevents resource exhaustion. Set aggressive timeouts—2-3 seconds max for inter-service calls.
Async breaks everything (in a good way). Instead of Service A waiting for Service B synchronously, drop the request in a queue. Service A’s thread is free immediately. Even if there’s a circle in the async chain, you won’t exhaust resources.
Dependency graph analysis. Tools now use AI to analyze production logs and build actual runtime dependency graphs, not your aspirational architecture. Run these weekly. The circles you find will shock you.
Chaos engineering. Intentionally create circular call patterns in staging with production-level load. If your system survives 10,000 RPS with a circular dependency, you’re probably safe. Probably.
Real-World Battle Scars
AWS’s DynamoDB team discovered a five-hop circular dependency during a 2015 scaling test. It only triggered under specific partition key patterns at scale.
Uber’s dispatch system had a hidden circle: location-service → driver-service → trip-service → location-service. It appeared only when drivers and riders were in the same geohash bucket, making it nearly impossible to reproduce in testing.
Netflix prevents this with their “chaos gorilla” continuously testing for circular dependencies in production. If a circle exists, they find it before you do.
Build This Right Now
Add request ID propagation to every service call today. Use OpenTelemetry—it’s 10 lines of code.
Implement circuit breakers with reasonable timeouts (use Resilience4j for JVM, Polly for .NET, or Opossum for Node.js).
Set up distributed tracing and create alerts for circular request patterns.
Run the demo (see demo.sh) to watch a circular dependency melt down in real-time, then see circuit breakers save the day.
Do a dependency audit next sprint. Map every service call. Use tools like Zipkin or Jaeger to visualize actual traffic patterns.
The circle is already in your system. You just haven’t found it yet. When you do—and you will—you’ll be ready.
Github demo source code : https://github.com/sysdr/sdir/tree/main/circular_dependancy
Run the demo to see thread pool exhaustion happen live. Watch 100 threads disappear in 10 seconds, then see circuit breakers prevent the cascade.