
Incident Response Automation
Issue #130: System Design Interview Roadmap • Section 5: Reliability & Resilience
Video :
When Your System Breaks at 3 AM
You're sound asleep when your phone buzzes. Another production outage. By the time you're dressed and logged in, hundreds of users are already complaining on social media. What if your system could have detected the issue, diagnosed the root cause, and even fixed itself—all before you woke up?
This isn't science fiction. Companies like Netflix, Google, and Amazon rely on sophisticated incident response automation that prevents millions of dollars in losses while their engineers sleep peacefully.
What We'll Master Today
Automated Detection: How systems recognize problems before humans do
Smart Escalation: When to auto-fix vs. when to wake someone up
Self-Healing Actions: Teaching your system to fix common issues
Observability Integration: Making automation decisions with confidence
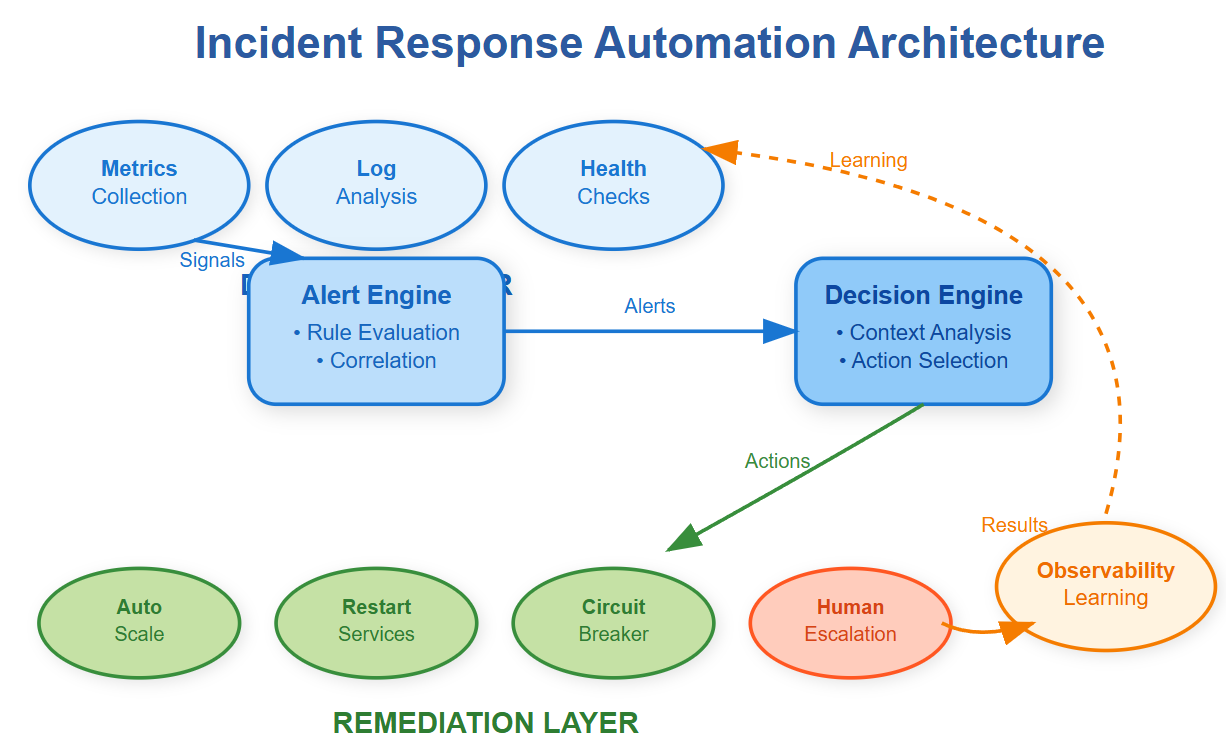
The Three Pillars of Incident Response Automation
Modern incident response automation rests on three foundational pillars that work together to maintain system health without human intervention.
Pillar 1: Intelligent Detection
Traditional monitoring waits for things to break completely. Smart detection catches problems early using predictive signals. Instead of alerting when CPU hits 90%, advanced systems recognize unusual patterns—like gradual memory leaks or increasing error rates—that indicate impending failures.
The key insight: Detection systems must understand normal vs. abnormal behavior for your specific workloads. A 50% CPU spike might be normal during daily batch processing but catastrophic during low-traffic hours.
Pillar 2: Context-Aware Decision Making
Raw alerts are useless noise. The automation engine must correlate signals across your entire stack to make intelligent decisions. When your database connection pool exhausts, the system should know whether to restart the application, scale the database, or redirect traffic to healthy regions.
Netflix's automation considers dozens of factors: time of day, recent deployments, regional traffic patterns, and historical incident data. Their system learned that database timeouts during European morning hours usually require different responses than the same symptoms during US peak traffic.
Pillar 3: Safe Remediation Actions
Automation must be fail-safe. Each remediation action includes rollback procedures and blast radius limits. When automatically scaling up instances, the system caps the maximum count to prevent runaway costs. When restarting services, it does so gradually with health checks at each step.
Enterprise Case Studies: Learning from the Best
Netflix: Chaos-Informed Automation
Netflix runs hundreds of thousands of instances across multiple AWS regions. Their incident response automation emerged from their famous Chaos Engineering practices. By intentionally breaking things, they learned which failures could be automatically resolved and which required human intervention.
Their automation handles 80% of common failures: instance failures (auto-replace), traffic spikes (auto-scale), and dependency timeouts (circuit breakers with fallbacks). The remaining 20% escalate to engineers with rich context about what automation already attempted.
Key Insight: Netflix's automation is conservative by design. It prefers false negatives (missing some incidents) over false positives (unnecessary remediations) because automated actions at their scale can impact millions of users.
Google: SRE-Driven Automation Philosophy
Google's Site Reliability Engineering teams treat automation as a core reliability mechanism. Their automation focuses on eliminating "toil"—repetitive manual work that doesn't require human judgment.
Their systems automatically handle capacity management, failover procedures, and even some security incident responses. When a service experiences elevated error rates, automation first checks for recent deployments, then evaluates rollback safety, and can automatically revert problematic changes within minutes.
Production Wisdom: Google learned that automation must be auditable. Every automated action generates detailed logs explaining the decision process, making post-incident reviews more effective.
Amazon: Scale-Driven Automation Necessity
At Amazon's scale, manual incident response is physically impossible. Their automation handles thousands of concurrent incidents across AWS services worldwide. Their approach focuses on blast radius containment—automated actions are scoped to minimize potential damage.
When EC2 instances fail health checks, automation doesn't just restart them. It analyzes failure patterns across availability zones, considers recent AWS service announcements, and makes intelligent decisions about whether to replace instances or declare broader infrastructure issues.
Working Code Demo:
Implementation Patterns That Actually Work
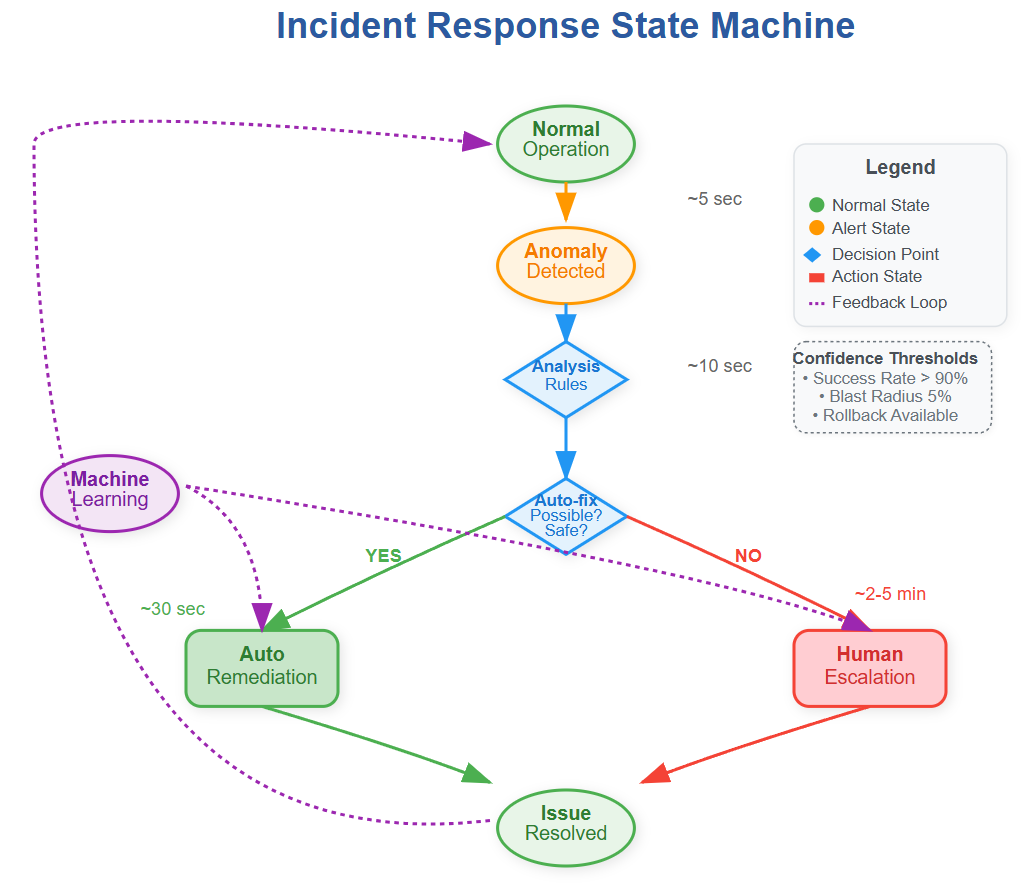
The Graduated Response Pattern
Effective automation uses escalating response levels rather than binary actions. Level 1 might restart application processes. Level 2 could restart entire instances. Level 3 might trigger traffic failover to other regions.
This graduated approach prevents over-reaction while ensuring coverage for various failure modes. Each level includes specific timeout and retry logic—automation doesn't wait forever for actions to succeed.
The Human-in-the-Loop Pattern
Critical systems require human oversight even with automation. The pattern involves automated diagnosis and recommended actions, but humans approve high-impact changes. This maintains safety while eliminating the time spent on root cause analysis.
During incident escalation, engineers receive context-rich summaries: what failed, what automation already tried, and specific remediation options with predicted success rates based on historical data.
The Hidden Complexities
Automation Bias and Over-Reliance
Teams often develop blind trust in automation, leading to skill atrophy in manual incident response. When automation fails during novel scenarios, engineers may lack the troubleshooting skills needed for manual recovery.
Mitigation Strategy: Regular "automation-free" incident response drills ensure teams maintain manual debugging capabilities while testing automation coverage gaps.
State Management Across Failures
Automation systems must maintain their own state consistently. If the automation engine crashes during incident response, it should resume safely without duplicating actions or losing context.
Production systems use distributed state machines with checkpoint-based recovery, ensuring automation can continue even if its control plane experiences failures.
Building Your Automation Strategy
Start with High-Confidence, Low-Risk Actions
Begin automation with scenarios where the correct action is obvious and the failure modes are well-understood. Restarting crashed processes, scaling up during traffic spikes, or clearing temporary files are excellent starting points.
Avoid automating complex business logic or actions with significant user impact until you've built confidence in your automation framework's reliability and observability.
Measure Everything, Automate Incrementally
Track automation effectiveness: successful resolutions, false positives, and incidents where automation helped vs. hindered. This data drives decisions about which scenarios to automate next and which require human judgment.
Design for Transparency
Every automated action should be observable and explainable. Engineers must understand why automation made specific decisions, especially when debugging incidents where automation was involved.
Your Next Production Challenge
Implement graduated incident response for a critical service in your system. Start with automated detection of a common failure pattern, add context-aware decision making, and implement a safe remediation action with proper rollback procedures.
Focus on observability first—ensure you can track automation decisions and outcomes before expanding to more complex scenarios. The goal is building confidence in automated decision-making while maintaining human oversight for critical situations.
Success Criteria: Your automation should handle 70% of routine incidents while providing rich context for the remaining 30% that require human intervention. Engineers should trust your automation enough to sleep soundly, knowing it will wake them only when truly necessary.
GitHub Link:
https://github.com/sysdr/sdir/tree/main/Incident_Response/incident-response-demoNext week in Issue #131, we'll explore Runbooks: Standardizing Operational Procedures, where we'll learn how to document incident response procedures that both humans and automation systems can follow consistently.