Monitoring and Alerting Architectures
Issue #128: System Design Interview Roadmap • Section 5: Reliability & Resilience

Working Code Demo:
When Silence Becomes Your Enemy
At 3 AM, your payment service starts rejecting 40% of transactions. Customer complaints flood in, but your monitoring dashboard shows everything is "green." The culprit? Your alerts were optimized for infrastructure metrics while completely missing business-critical failures. By the time someone manually discovered the issue, you'd lost $2M in revenue.
This scenario haunts engineering teams because traditional monitoring focuses on what's easy to measure rather than what matters. Today, we'll architect monitoring systems that catch failures before they become incidents, eliminate alert fatigue, and provide actionable insights when things go wrong.
What You'll Master Today
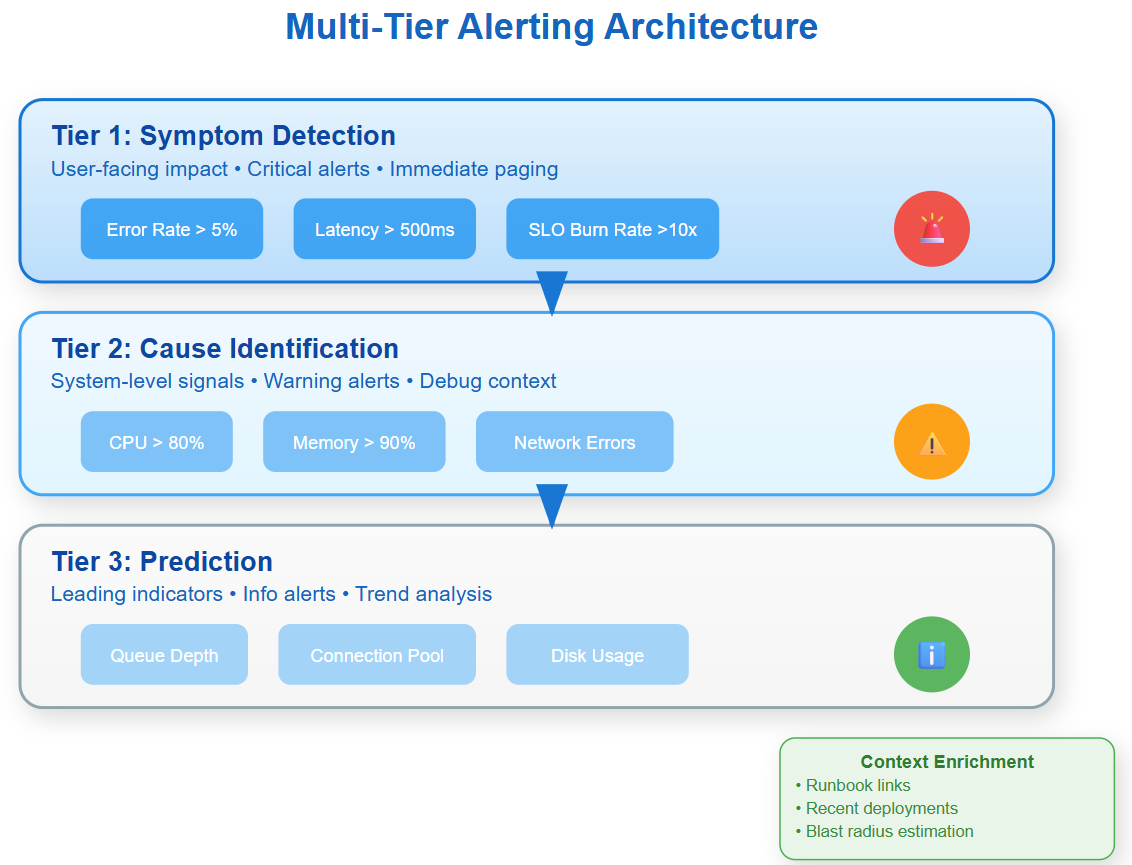
Multi-tier alerting that prevents both false positives and missed incidents
SLO-based monitoring that aligns technical metrics with business impact
Alert correlation patterns that reduce noise by 90%
Escalation strategies that get the right people involved at the right time
The Hidden Architecture of Effective Alerts
Most monitoring systems fail because they treat alerts as an afterthought. The insight that separates reliable systems from fragile ones: alerting is a user interface for your system's health, and like any interface, it requires intentional design.
Multi-Dimensional Alert Strategies