
Site Reliability Engineering: Core Principles
Issue #141: System Design Interview Roadmap • Section 5: Reliability & Resilience
What You’ll Master Today
Error Budget Mathematics: How Google calculates acceptable failure rates
SLO/SLI Design: Building measurable reliability contracts
Automation Strategies: Eliminating toil that kills team velocity
Incident Response Patterns: From detection to blameless postmortems
The Reliability Revolution
When Google’s site went down for 5 minutes in 2013, the internet traffic dropped by 40%. This wasn’t just a tech company problem—it became a global economic event. That incident crystallized why Site Reliability Engineering (SRE) emerged as the discipline that treats operations as a software problem.
SRE isn’t traditional ops with a new name. It’s a fundamental shift: instead of keeping systems running at all costs, SREs optimize for the right amount of reliability while maximizing feature velocity.
Core Principle 1: Error Budgets - The Reliability Currency
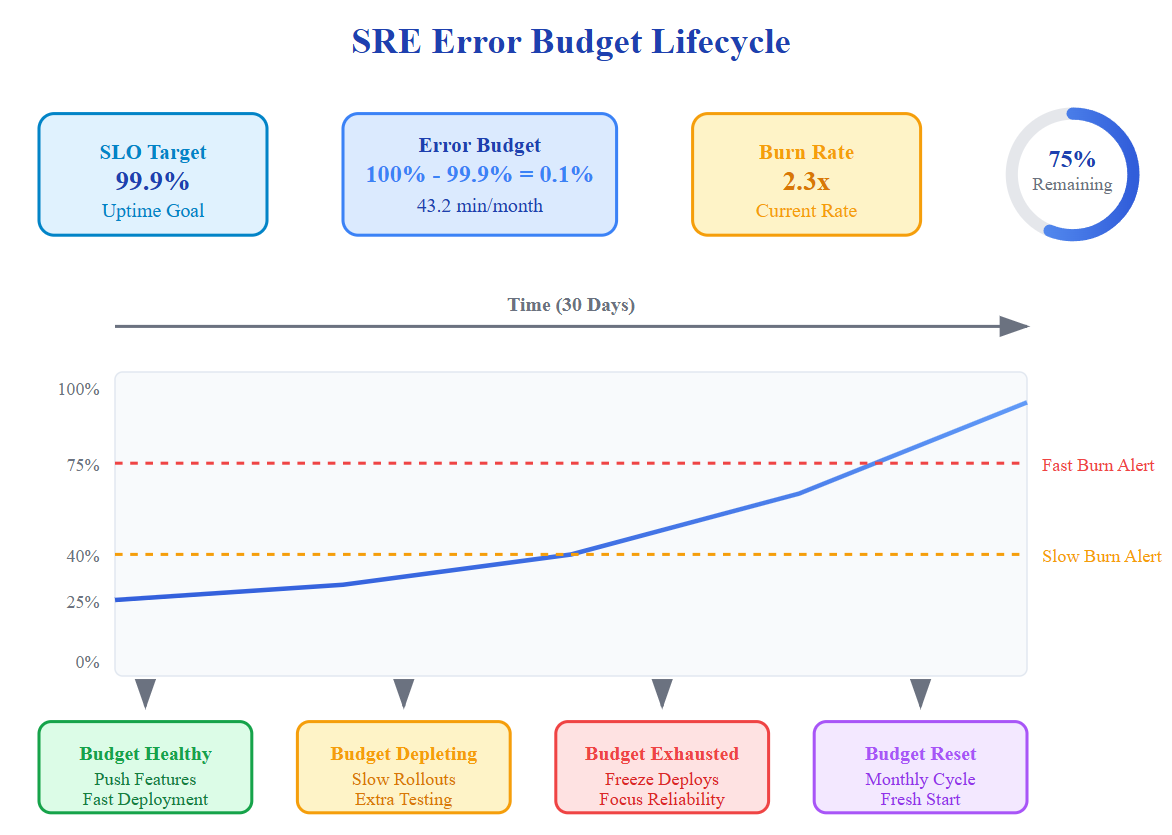
Error budgets solve the eternal conflict between reliability and feature velocity. If your SLO promises 99.9% uptime, you have a 0.1% error budget—roughly 43 minutes of downtime per month.
