
Kappa vs. Lambda Architecture: Evolution of Big Data Processing Pipelines
When Your Data Pipeline Becomes Your Biggest Problem
You’re processing millions of events per second—click streams, sensor data, financial transactions. Your Lambda architecture is running smoothly: batch jobs recompute historical views every few hours while a speed layer handles real-time updates. Then at 2 AM, you discover the batch and speed layers are calculating different results for the same metric. Your CEO is staring at conflicting revenue numbers. This isn’t a bug—it’s an architectural inevitability.
The Evolution: From Lambda to Kappa
Lambda Architecture emerged in the early 2010s to solve a fundamental problem: how do you process both historical data (batch) and real-time data (streaming) in the same system? The solution was elegant in theory—maintain two separate code paths.
The Lambda pipeline has three layers:
Batch Layer: Processes complete historical dataset, produces accurate but delayed views (hours to days old)
Speed Layer: Processes recent data in real-time, compensates for batch layer lag (seconds to minutes fresh)
Serving Layer: Merges results from both layers, serves queries
Here’s why it seemed brilliant: you get the accuracy of batch processing combined with the freshness of stream processing. Batch jobs handle complex analytics that are hard in streaming. The speed layer fills the gap until the next batch run incorporates new data.
The reality?
You’re maintaining two completely separate codebases implementing the same business logic. When you change how “active users” is calculated, you update it in both Spark (batch) and Storm/Flink (streaming). They inevitably drift. Your batch layer says 1.2M active users while your speed layer reports 1.18M. Which is right? Both. Neither. It depends on subtle timing and state management differences.
Kappa Architecture was proposed by Jay Kreps (LinkedIn, Kafka creator) as a radical simplification: what if we only had a stream processing layer? The key insight: with log-based storage (like Kafka), you can replay the entire historical dataset through your stream processor. Batch processing becomes “streaming over old data.”
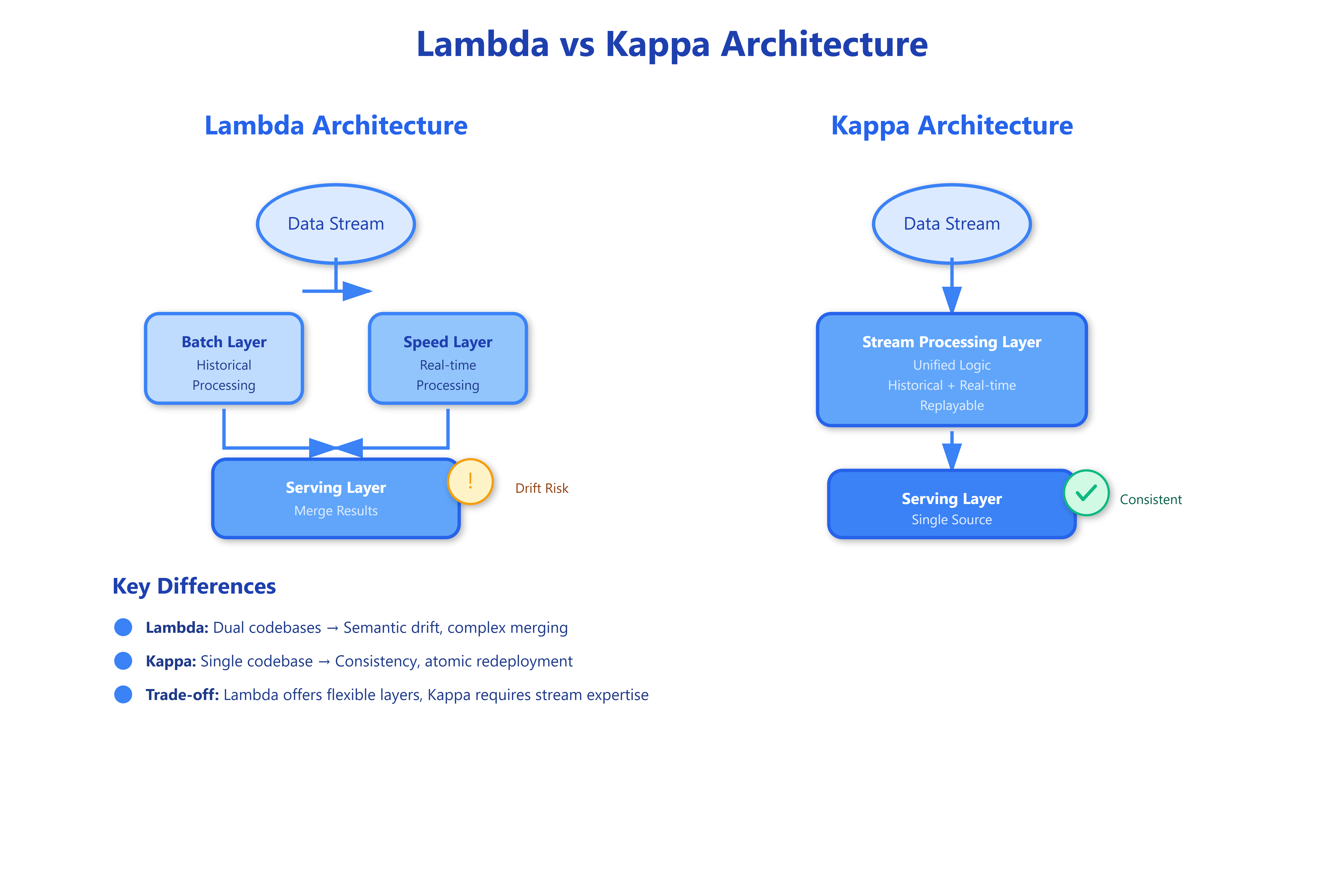
The Kappa pipeline collapses to:
Stream Processing Layer: Single codebase processes all data (historical and real-time)
Serving Layer: Stores and serves the computed views
When you need to recompute from scratch (code change, bug fix), you spin up a new stream processor, replay from the beginning of your Kafka topic, and swap to the new view atomically. One codebase. One source of truth. No synchronization headaches.
