
Latency vs. Throughput: Understanding the Trade-offs
In the world of system design, two performance metrics consistently dominate discussions: latency and throughput. These concepts are fundamental to understanding how systems perform under various conditions, yet they're often misunderstood or incorrectly used interchangeably. This article will demystify these critical concepts and explore the inherent trade-offs between them that every system designer must consider.
Defining the Fundamentals
Latency is the time delay between initiating an action and seeing its effect. In simpler terms, it's how long it takes for a single piece of data to travel from source to destination. Latency is typically measured in units of time—milliseconds (ms) being the most common.
Throughput is the rate at which a system can process data. It represents the amount of work done per unit of time, often measured in operations per second, requests per second, or bits per second (bandwidth).
To illustrate this difference, consider a highway:
Latency would be how long it takes for a single car to travel from one end to the other.
Throughput would be how many cars can pass through a point on the highway per hour.
Highway Analogy for Latency vs. Throughput

Measuring Performance in Real Systems
Let's translate these concepts to common computing scenarios:
Web Servers
Latency: The time from when a user clicks a link to when the page appears (e.g., 200ms)
Throughput: How many requests the server can handle per second (e.g., 5,000 req/sec)
Databases
Latency: How long it takes to retrieve a single record (e.g., 10ms)
Throughput: How many queries can be processed per second (e.g., 1,000 queries/sec)
Networks
Latency: The time it takes for a packet to travel from source to destination (e.g., 50ms)
Throughput: The amount of data that can be transferred per second (e.g., 100 MB/sec)
The Inherent Trade-offs
The relationship between latency and throughput is complex and often involves trade-offs. While it's technically possible to optimize for both, real-world constraints frequently force designers to prioritize one over the other.
Latency vs. Throughput Trade-off Visualization
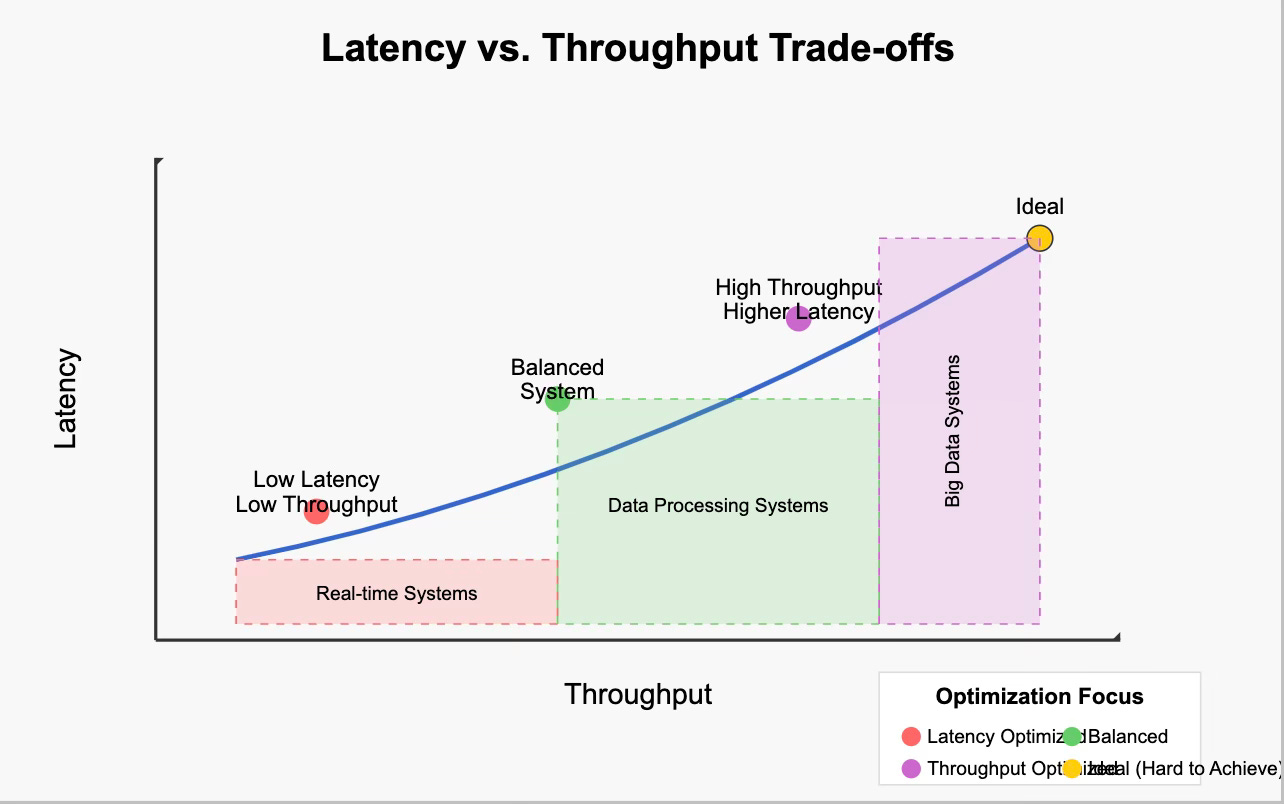
Why Trade-offs Exist
Several factors create these trade-offs:
Resource Constraints: Systems have finite resources (CPU, memory, network bandwidth).
Batching: Processing requests in batches increases throughput but adds latency as requests wait for the batch to fill.
Queuing: High throughput often requires queuing, which adds waiting time (latency).
Parallelization: Breaking down work for parallel processing improves throughput but introduces coordination overhead that can increase latency.
Hardware Limitations: Faster processors reduce latency but may consume more power, making them unsuitable for high-density deployments needed for high throughput.
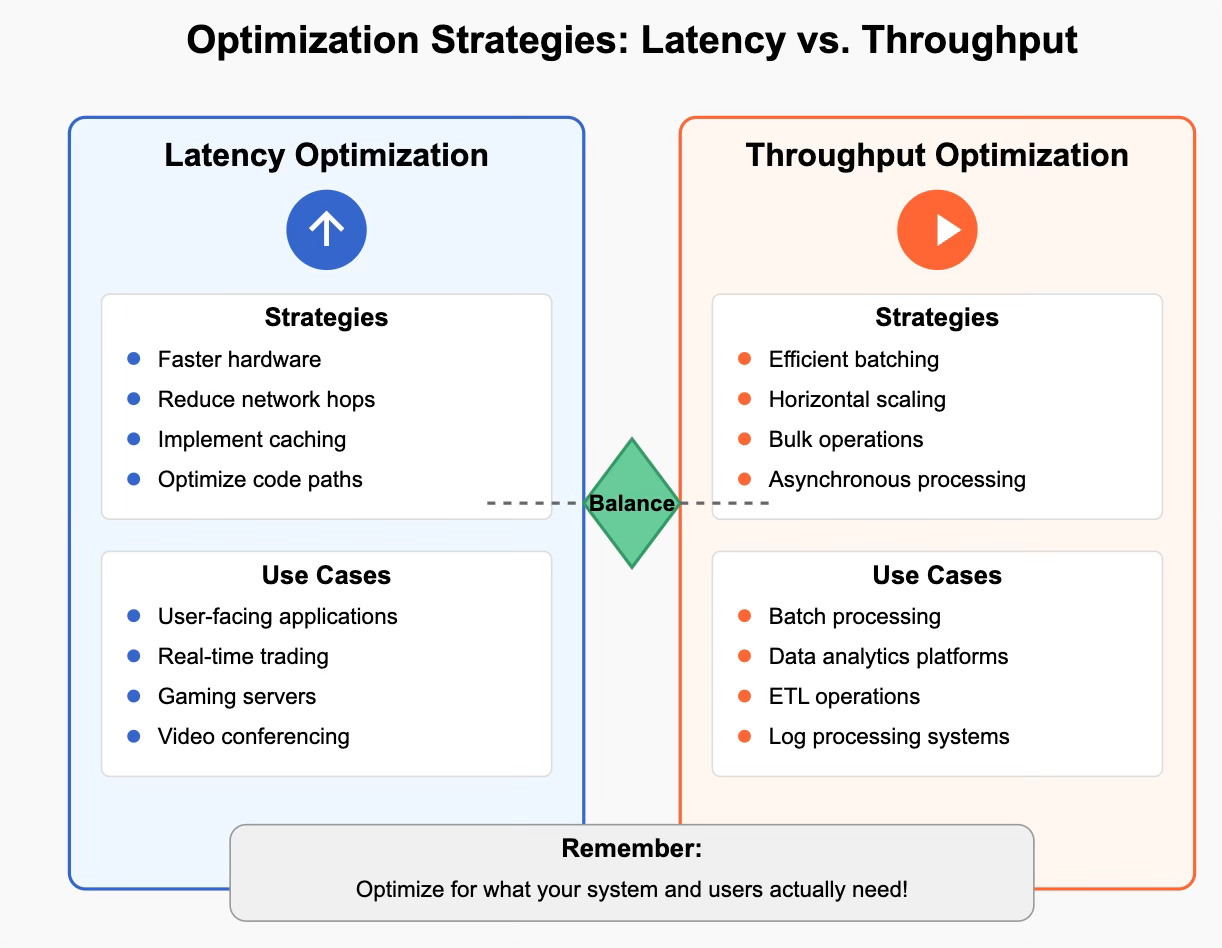
Optimization Strategies
Depending on your system requirements, you might optimize for latency, throughput, or attempt to balance both:
Latency Optimization
When to prioritize latency:
User-facing applications where response time affects user experience
Real-time systems (e.g., trading platforms, gaming, video conferencing)
Critical path operations
Strategies:
Use faster hardware (SSD instead of HDD, more powerful CPUs)
Reduce network hops
Implement caching
Optimize code execution paths
Place resources geographically closer to users
Throughput Optimization
When to prioritize throughput:
Batch processing systems
Data analytics platforms
High-volume transaction systems
Systems where overall work completion time matters more than individual operation speed
Strategies:
Implement efficient batching
Use bulk operations
Scale horizontally (add more nodes)
Optimize for consistent, sustainable performance
Use asynchronous processing
Optimization Strategies for Latency vs. Throughput
Real-World System Profiles
Different systems naturally gravitate toward different points on the latency-throughput spectrum:
Latency-Focused Systems
Stock Trading Platforms: Sub-millisecond latency requirements, relatively low transaction volume
Online Gaming: Low latency critical for user experience (ideally < 100ms)
Autonomous Vehicles: Need real-time processing of sensor data
Throughput-Focused Systems
Big Data Processing: Processing massive datasets where individual record processing time is less critical
Video Streaming Services: Need to deliver petabytes of data efficiently
Payment Processors: Handling millions of transactions per second during peak times
Balanced Systems
E-commerce Platforms: Need reasonable page load times (latency) while handling many simultaneous users (throughput)
Social Media Feeds: Quick loading essential, but must also handle billions of content views
Measurement and Improvement
To effectively optimize your system, follow these steps:
Establish Baselines: Measure current latency and throughput under various conditions.
Identify Bottlenecks: Use profiling tools to find what's limiting performance.
Set Clear Goals: Define acceptable latency percentiles (e.g., 99% of requests under 200ms) and required throughput levels.
Test Incrementally: Make one change at a time and measure its impact.
Monitor in Production: Real-world performance often differs from test environments.
Queuing Theory and Little's Law
One fundamental relationship between latency and throughput is expressed in Little's Law, which states:
L = λW
Where:
L is the average number of items in the system
λ (lambda) is the average arrival rate (throughput)
W is the average time an item spends in the system (latency)
This elegant formula demonstrates that if you keep the system capacity (L) constant, you cannot increase throughput without decreasing latency, and vice versa.
Little's Law Visualization

Conclusion
Understanding the relationship between latency and throughput is essential for effective system design. While both metrics are important, most real-world systems must make intentional trade-offs based on their specific requirements.
For latency-sensitive applications like gaming or financial trading, design decisions should prioritize minimizing response times. For throughput-oriented systems like batch processors or analytics platforms, maximizing work completed per unit time takes precedence.
The most important approach is to clearly understand your specific use case, measure what matters, and optimize accordingly. Remember that premature optimization is the root of many design problems—start with a clear understanding of your actual requirements before diving into optimizations.
As you build and scale systems, constantly revisit these fundamental concepts, measuring and analyzing how changes affect both latency and throughput. This balanced approach will help you create systems that deliver the right performance characteristics for your specific needs.