
Live Streaming Architecture: Ingest, Transcoding, and Delivery at Scale
The 3-Second Rule That Costs Millions
When a viewer clicks play on a live stream, the platform has roughly 3 seconds before they bounce. That constraint drives every architectural decision in live streaming systems. Unlike VOD (video on demand), you can’t pre-transcode everything. The stream doesn’t exist until someone starts broadcasting, and you need to simultaneously ingest, process, and deliver to potentially millions of viewers with sub-second coordination across continents. A single bottleneck in this pipeline causes buffering, and buffering kills engagement.
The Three-Stage Pipeline
Live streaming architecture breaks into three distinct stages, each with different scaling characteristics and failure modes.
Ingest receives the raw video stream from broadcasters. The dominant protocol is RTMP (Real-Time Messaging Protocol), pushed to origin servers typically over TCP. RTMP provides reliable delivery with built-in handshake and acknowledgment, but adds latency. Modern alternatives include SRT (Secure Reliable Transport), which uses UDP with custom retransmission logic for lower latency, and WebRTC for browser-based broadcasting. The ingest layer must handle connection drops gracefully—if a broadcaster’s network hiccups for 2 seconds, you don’t want to terminate their stream and force reconnection. Buffer the gap, attempt reconnection, and only fail after a timeout threshold (typically 10-15 seconds).
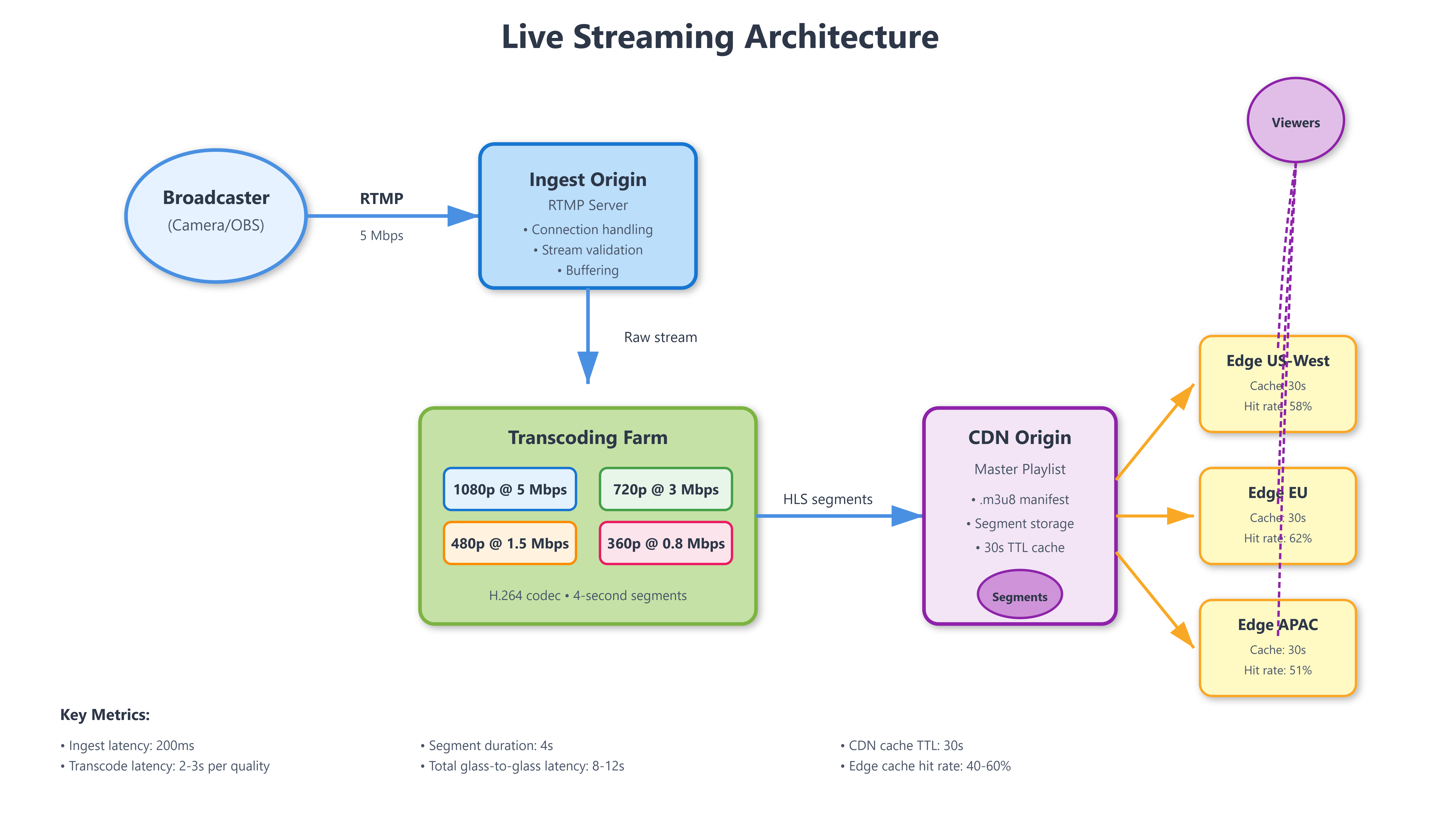
Transcoding converts the single high-quality ingest stream into multiple bitrate renditions. This is where the CPU cost explodes. A 1080p60 stream requires roughly 4-6 CPU cores to transcode into a typical ABR ladder: 1080p, 720p, 480p, 360p, 240p. At scale, this becomes the dominant operational cost. Twitch processes millions of concurrent streams, each requiring dedicated transcoding resources. The optimization isn’t just technical—it’s economic. You can’t transcode every stream to 5 renditions; you prioritize based on viewer count. Streams with <10 viewers might get only 2 renditions (source + 480p), while streams with 10K+ viewers get the full ladder.
The transcoding ladder itself requires careful design. Bitrate steps should be roughly 50% apart (1080p@6Mbps, 720p@3Mbps, 480p@1.5Mbps). Too close, and you waste bandwidth without quality improvement. Too far, and viewers experience jarring quality jumps when their connection fluctuates. The codec choice matters: H.264 remains dominant for compatibility, but AV1 provides 30% better compression at the cost of 3x encoding CPU time. YouTube Live uses VP9 as a middle ground.
Delivery distributes the transcoded segments to viewers via CDN. The protocol is typically HLS (HTTP Live Streaming) or DASH (Dynamic Adaptive Streaming over HTTP). Both work identically: chop the stream into 2-6 second segments, generate a manifest file listing available renditions, and let the client download segments over HTTP. The player measures throughput after each segment and switches renditions dynamically.
The CDN layer must handle thundering herd problems. When a popular stream starts, thousands of viewers hit the origin simultaneously requesting the first segment. This is where origin-edge architecture matters. The origin transcodes and generates segments, but only edge servers (close to viewers) serve them. Edge servers cache segments for 30-60 seconds—long enough to serve multiple viewers, short enough to prevent serving stale data if the stream ends.
Critical Insights
Common Knowledge: HLS introduces 6-18 seconds of latency (3-6 segments buffered). For near-real-time interaction, use Low-Latency HLS (LHLS) or DASH with chunked transfer encoding, reducing latency to 2-4 seconds.
Rare Knowledge: Transcoding isn’t stateless. Encoders maintain reference frames across segments for compression efficiency. If you kill and restart a transcoder mid-stream (e.g., during autoscaling), the first few segments after restart will be keyframes only, causing a 2-3x bitrate spike and potential buffering for viewers.
Advanced Insights: The manifest file is a single point of failure. If origin can’t update the manifest for 10 seconds, all viewers freeze—they won’t request new segments without manifest updates. Facebook Live solved this by generating manifests at the edge, with each edge server independently predicting segment availability based on timing patterns. If origin is slow, edge serves a slightly stale but syntactically valid manifest.
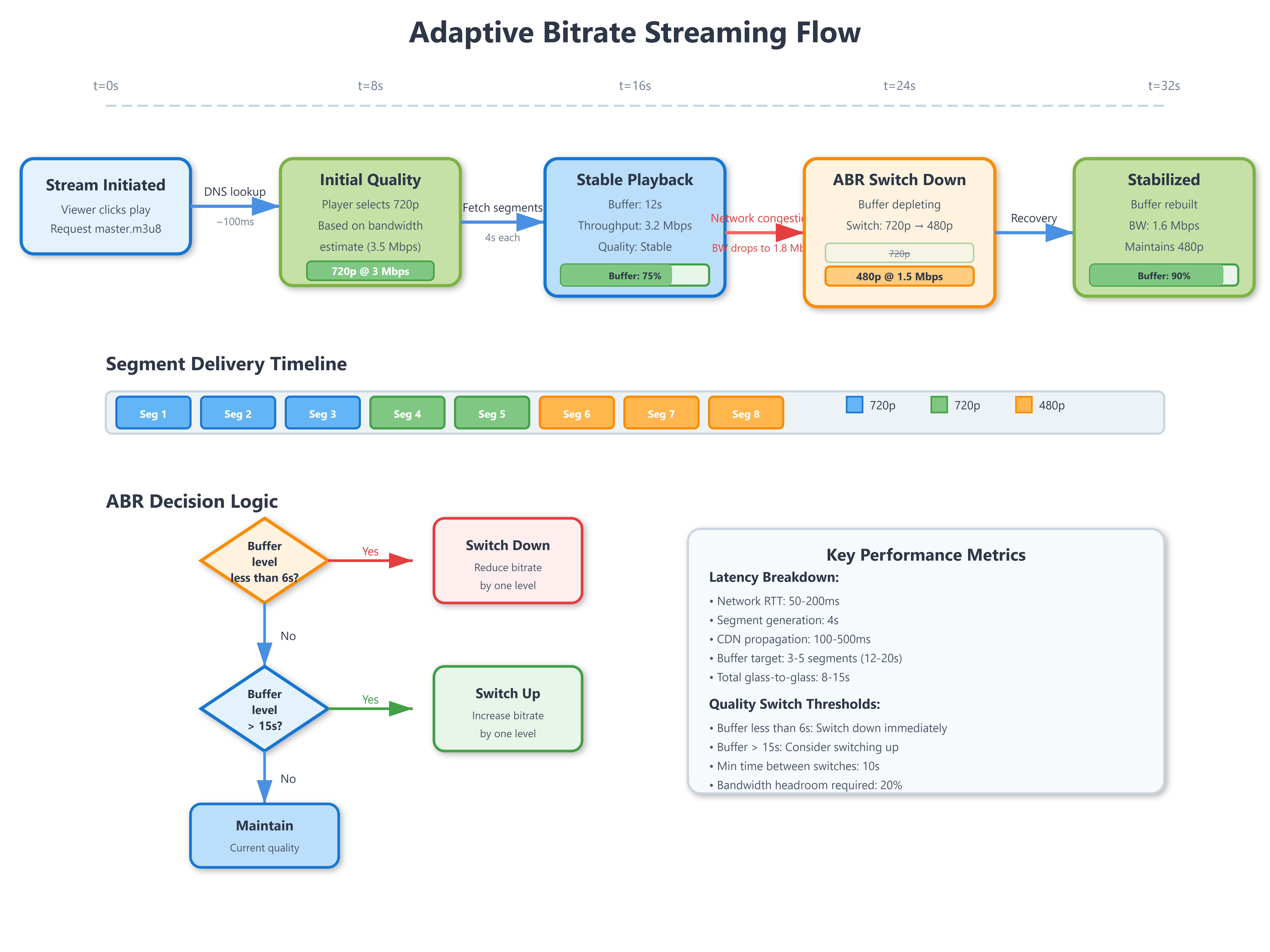
Strategic Impact: ABR switching creates visible quality changes. Users perceive downward switches (HD→SD) as buffering failures, even if playback never stops. Netflix research shows users prefer occasional buffering over frequent quality fluctuations. Live platforms often limit downward switches to once per 30 seconds.
Implementation Nuances: RTMP ingest uses a handshake sequence (C0, S0, C1, S1, C2, S2) before stream data flows. If you naively implement reconnection, you can create a state where the broadcaster thinks they’re connected (handshake complete) but the origin hasn’t allocated transcoding resources yet, resulting in silent stream failure. Always tie resource allocation to handshake completion.
Failure Pattern: When a CDN edge server fails, viewers get redirected to the next-closest edge. If many edges fail simultaneously (e.g., network partition), you create a cascade where all traffic hits fewer edges, overloading them. Twitch mitigated this by implementing probabilistic edge selection—viewers randomly choose from 3-5 nearest edges instead of always using the closest.
Real-World Examples
Twitch processes 6+ million concurrent viewers across 70,000+ live streams (peak hours). Their ingest layer uses RTMP with custom extensions for metadata (viewer count, chat integration). Transcoding is prioritized: Partner channels get instant transcoding, Affiliates get transcoding when capacity is available, and non-affiliated streams transcode only if viewer count exceeds thresholds. This economic optimization reduced transcoding costs by 60% while maintaining experience for 95% of viewing hours.
YouTube Live handles streams ranging from mobile phone broadcasts to professional 4K productions. Their transcoding infrastructure uses a mix of H.264 (for compatibility) and VP9 (for bandwidth efficiency). The platform automatically detects broadcaster upload bandwidth and adjusts ingest quality—if you’re streaming at 10Mbps but your uplink can only sustain 6Mbps, YouTube’s ingest server signals the broadcaster to reduce bitrate, preventing stream instability.
Facebook Live serves 2+ billion potential viewers across widely varying network conditions. Their innovation was edge-based ABR decision making: instead of clients choosing renditions, the edge server monitors downstream bandwidth and server-side switches renditions before sending segments. This reduces client-side complexity and enables better switching decisions using aggregate data from thousands of viewers.
Architectural Considerations
GitHub Link
https://github.com/sysdr/sdir/tree/main/Live_Streaming/streaming-demoMonitoring live streaming systems requires different metrics than VOD. Track time-to-first-frame (TTFF) per viewer—this reveals ingest or transcoding delays. Monitor segment generation lag: segments should appear 1-2 seconds after real time; delays indicate transcoding bottlenecks. Watch CDN cache hit ratios; live content typically sees 40-60% hit rates (lower than VOD) because segments are short-lived.
Cost models differ drastically: ingest is cheap (network bandwidth), transcoding is expensive (CPU time), and delivery is moderate (CDN bandwidth). For a 1M viewer stream, transcoding costs ~$200/hour, while delivery costs ~$800/hour at typical CDN rates. Origin infrastructure (ingest + transcoding) must overprovision for spiky traffic, but CDN scales automatically.
Debugging requires distributed tracing across stages. Implement correlation IDs that flow from ingest through transcoding to delivery. When viewers report buffering, you need to determine: Was ingest dropping packets? Did transcoding lag? Did the edge serve stale manifests? Without end-to-end visibility, troubleshooting becomes guesswork.
Practical Takeaway
Start with the economics: transcoding is your largest cost center at scale. Implement tiered transcoding based on viewer count to optimize spend. Design your ABR ladder carefully—too many renditions waste bandwidth, too few create quality gaps.
For ingest reliability, implement connection pooling where broadcasters can rapidly switch between multiple origin servers without stream interruption. Use SRT for lower latency if your use case requires real-time interaction (gaming streams, live auctions), but stick with RTMP for broader compatibility.
Run
bash setup.shto see a complete live streaming pipeline in action. The demo implements RTMP ingest, multi-bitrate transcoding, HLS delivery, and a real-time dashboard showing viewer connections, bitrate adaptation, and buffer states. Extend it by implementing your own ABR algorithm or experimenting with different segment durations to observe latency vs. stability trade-offs. The hands-on experience of watching segments generate, cache, and expire will solidify your understanding of why milliseconds matter in this architecture.