
Load Balancing: The "Zombie Server" Problem
System Design Interview Roadmap • Section 5: Reliability & Resilience
Working Code Demo:
When Your Servers Lie to You
You're monitoring your e-commerce platform during Black Friday when disaster strikes. Your load balancer shows all servers healthy with green checkmarks, but user complaints flood in about timeouts and failed purchases. Traffic is being routed to servers that appear fine but are secretly broken—welcome to the zombie server nightmare.
Netflix discovered this exact scenario during a major outage in 2019. Their load balancers happily sent traffic to servers that passed basic health checks but had exhausted database connections. Users saw the dreaded spinning wheel while perfectly healthy servers sat idle.
Today we'll dissect the zombie server problem, understand why traditional health checks fail, and build advanced detection mechanisms that prevent these silent killers from destroying user experience.
What We'll Master Today
Zombie Server Anatomy: Understanding servers that lie about their health
Health Check Evolution: From basic pings to intelligent application-level checks
Detection Strategies: Multi-layered approaches for catching zombie behaviors
Real-World Patterns: How Netflix, Uber, and Amazon solve this problem
Hands-On Implementation: Build a complete zombie detection system
The Zombie Server Phenomenon
A zombie server looks alive to your load balancer but cannot serve real user requests. Unlike completely dead servers that fail health checks, zombies pass basic connectivity tests while silently corrupting user experiences.
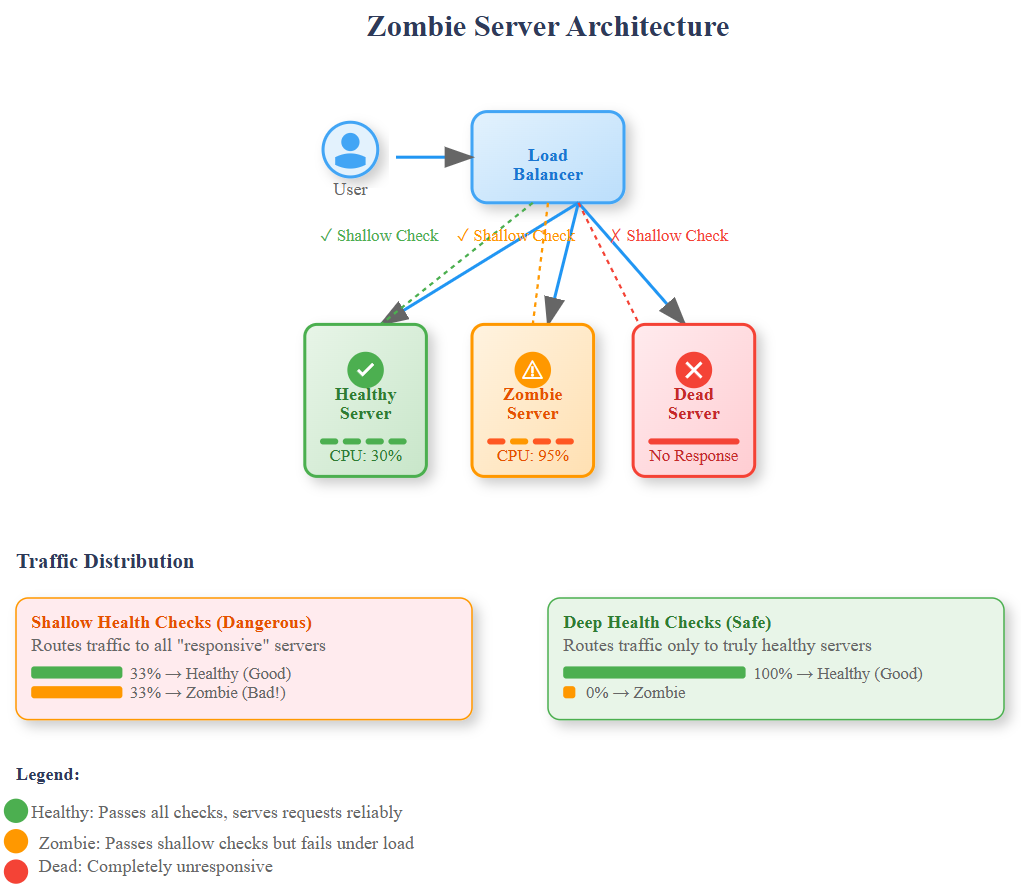
Common zombie conditions include:
Thread Pool Exhaustion: Server responds to health checks but has no threads for user requests
Memory Pressure: Basic endpoints work, but complex operations fail due to garbage collection storms
Database Connection Starvation: Health checks use dedicated connections while user requests timeout waiting for database access
Dependency Cascade Failures: External service failures make the server functionally useless despite appearing healthy
The insidious nature of zombie servers makes them more dangerous than complete failures. Dead servers get removed from rotation immediately, but zombies continue receiving traffic, creating a slow bleed of user experience degradation.
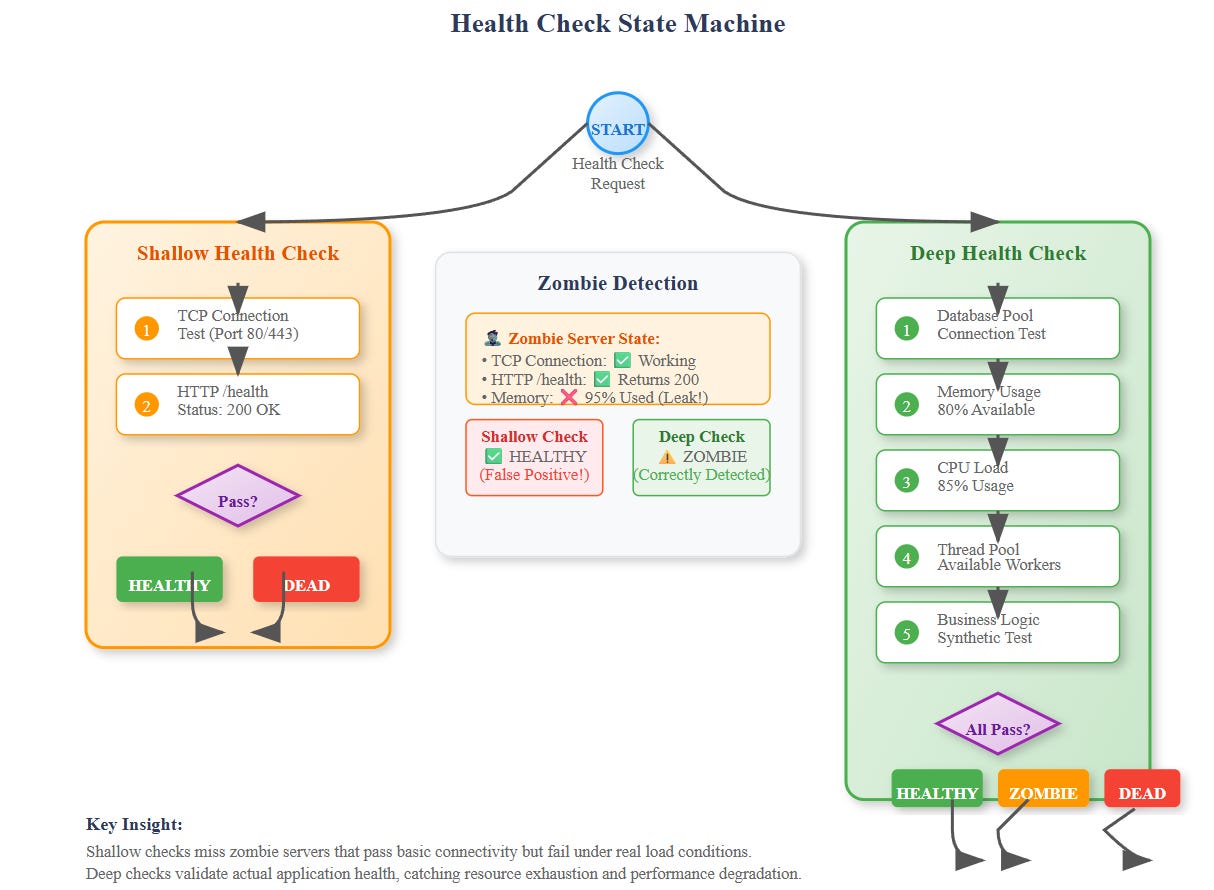
Why Traditional Health Checks Fail
Most load balancers use simple TCP connections or basic HTTP endpoints for health checks. A typical health check might look like:
curl -f http://server:8080/health
# Returns 200 OK, server marked healthy
This approach fails because it only validates that the web server process is running and can return a response. It doesn't verify that the server can actually handle real application logic.
Critical Insight: Health checks operate in a different resource pool than user requests. A server might have reserved resources for health check responses while user-facing resources are completely exhausted.
Spotify learned this lesson when their recommendation service started failing. Health checks used a lightweight endpoint that bypassed their recommendation engine, so load balancers kept routing traffic to servers that couldn't generate music recommendations.
Advanced Detection Strategies
Deep Health Checks
Instead of shallow connectivity tests, deep health checks validate actual application capabilities:
# Shallow health check (dangerous)
@app.route('/health')
def shallow_health():
return {'status': 'ok'}
# Deep health check (better)
@app.route('/health/deep')
def deep_health():
# Test database connectivity
db_healthy = test_database_connection()
# Test critical dependencies
cache_healthy = test_redis_connection()
# Test resource availability
threads_available = get_available_thread_count() > 5
if not all([db_healthy, cache_healthy, threads_available]):
return {'status': 'unhealthy'}, 503
return {'status': 'healthy'}
Synthetic Transaction Testing
The gold standard involves running actual business logic during health checks. Amazon's recommendation service performs mini-recommendation requests during health checks, ensuring the entire pipeline works correctly.
Gradual Health Assessment
Rather than binary healthy/unhealthy states, modern systems use graduated health scoring:
def calculate_health_score():
scores = {
'cpu_usage': (100 - cpu_percent()) / 100,
'memory_available': available_memory() / total_memory(),
'response_time': max(0, (1000 - avg_response_time()) / 1000),
'error_rate': max(0, (1 - error_rate()) * 100)
}
return sum(scores.values()) / len(scores)
Load balancers can then distribute traffic proportionally based on health scores rather than simple on/off routing.
Enterprise Implementation Patterns
Netflix's Multi-Layer Approach
Netflix combines multiple detection mechanisms:
Level 1: Basic connectivity (30-second intervals)
Level 2: Application health endpoints (60-second intervals)
Level 3: Synthetic user journey tests (5-minute intervals)
Level 4: Real user monitoring and automatic traffic shifting
Uber's Adaptive Health Checking
Uber's load balancers adjust health check frequency based on observed failure rates. During stable periods, checks happen every 60 seconds. When failures increase, frequency ramps up to every 10 seconds, enabling faster zombie detection.
Amazon's Circuit Breaker Integration
Amazon integrates health checking with circuit breaker patterns. When a server's circuit breaker trips due to downstream failures, the health check automatically returns unhealthy, preventing traffic routing to functionally broken servers.
Production Implementation Insights
Health Check Resource Isolation
Dedicate separate resource pools for health checks to prevent zombie scenarios where health checks succeed but user requests fail:
# Separate thread pools
health_check_executor = ThreadPoolExecutor(max_workers=2)
user_request_executor = ThreadPoolExecutor(max_workers=50)
@app.route('/health')
def health_check():
future = health_check_executor.submit(perform_health_validation)
return future.result(timeout=5)
Timeout Configuration Strategy
Set health check timeouts shorter than user request timeouts to detect performance degradation:
Health check timeout: 1 second
User request timeout: 10 seconds
If health checks start timing out, the server is becoming zombie-like
Monitoring and Alerting
Track these zombie-detection metrics:
Health check success rate vs. user request success rate divergence
Response time correlation between health checks and real traffic
Resource utilization patterns during zombie states
Interview Deep Dive
Q: How would you detect a zombie server that passes health checks but has a memory leak?
A: Implement resource-aware health checks:
def memory_health_check():
memory_usage = psutil.virtual_memory().percent
if memory_usage > 85: # Approaching danger zone
return False
# Test garbage collection pressure
gc_count_before = gc.get_count()
time.sleep(0.1)
gc_count_after = gc.get_count()
if sum(gc_count_after) - sum(gc_count_before) > threshold:
return False # High GC pressure indicates memory issues
return True
Q: Design a health check system for a microservices architecture with 50+ services.
A: Implement hierarchical health checking:
Service-level health (individual service status)
Dependency health (critical downstream services)
Business capability health (end-to-end user journey validation)
Use health check aggregation patterns and weighted scoring
Your Next Challenge
Build the zombie server detection system using our hands-on demo. You'll create multiple server types—healthy, zombie, and dead—then implement intelligent health checking that catches zombie behaviors traditional systems miss.
The demo includes:
Load balancer with configurable health check strategies
Backend servers with controllable zombie conditions
Real-time dashboard showing the problem and solution
Performance testing tools to validate effectiveness
Understanding zombie server detection isn't just about load balancing—it's about building reliable systems that maintain user trust even when individual components degrade. Master these patterns, and you'll architect systems that gracefully handle the inevitable complexity of distributed failure modes.
GitHub Link:
https://github.com/sysdr/sdir/tree/main/Zombie_Server/zombie-server-demo