
Microservice Decomposition Strategies
When Your Monolith Becomes a Liability
Your startup’s monolith handled 1,000 users beautifully. At 100,000 users, deployment takes 45 minutes and requires all-hands coordination. Your product team can’t ship checkout improvements without waiting for the authentication team to finish their sprint. A memory leak in the analytics module crashes the entire application. This isn’t technical debt—it’s an architectural straitjacket. Breaking apart a monolith isn’t about following microservices hype; it’s about unlocking independent evolution of business capabilities.
The Art of Strategic Decomposition
Microservice decomposition is the practice of identifying boundaries within a monolithic system and extracting cohesive, independently deployable services. Unlike simple code modularization, decomposition requires understanding domain boundaries, data ownership, and transaction patterns.
The most effective decomposition follows Domain-Driven Design (DDD) bounded contexts—natural divisions where business logic, language, and rules form coherent units. An e-commerce platform naturally splits into bounded contexts: Product Catalog (SKUs, inventory, pricing), Order Management (cart, checkout, fulfillment), and Customer Identity (authentication, profiles, preferences). Each context owns its data, exposes well-defined APIs, and can evolve independently.
Three primary strategies drive decomposition decisions:
Decomposition by Business Capability identifies what the organization does (not how). A payment processing system decomposes into Payment Authorization, Fraud Detection, Settlement Processing, and Chargeback Management—each representing distinct business functions with different scaling needs and regulatory requirements.
Decomposition by Subdomain follows DDD principles, distinguishing core domain (competitive advantage), supporting subdomains (necessary but not differentiating), and generic subdomains (commodity functionality). Amazon’s core domain is recommendations and logistics optimization; payment processing is supporting; email delivery is generic. This guides where to invest engineering effort and what to buy vs. build.
The Strangler Fig Pattern enables incremental migration by routing new features to microservices while legacy code gradually atrophies. You don’t rewrite the entire system—you identify high-value, well-bounded capabilities and extract them iteratively. Stripe migrated from Ruby monolith to services over five years, starting with the API gateway, then payment processing, then merchant onboarding—each extraction validated before the next.
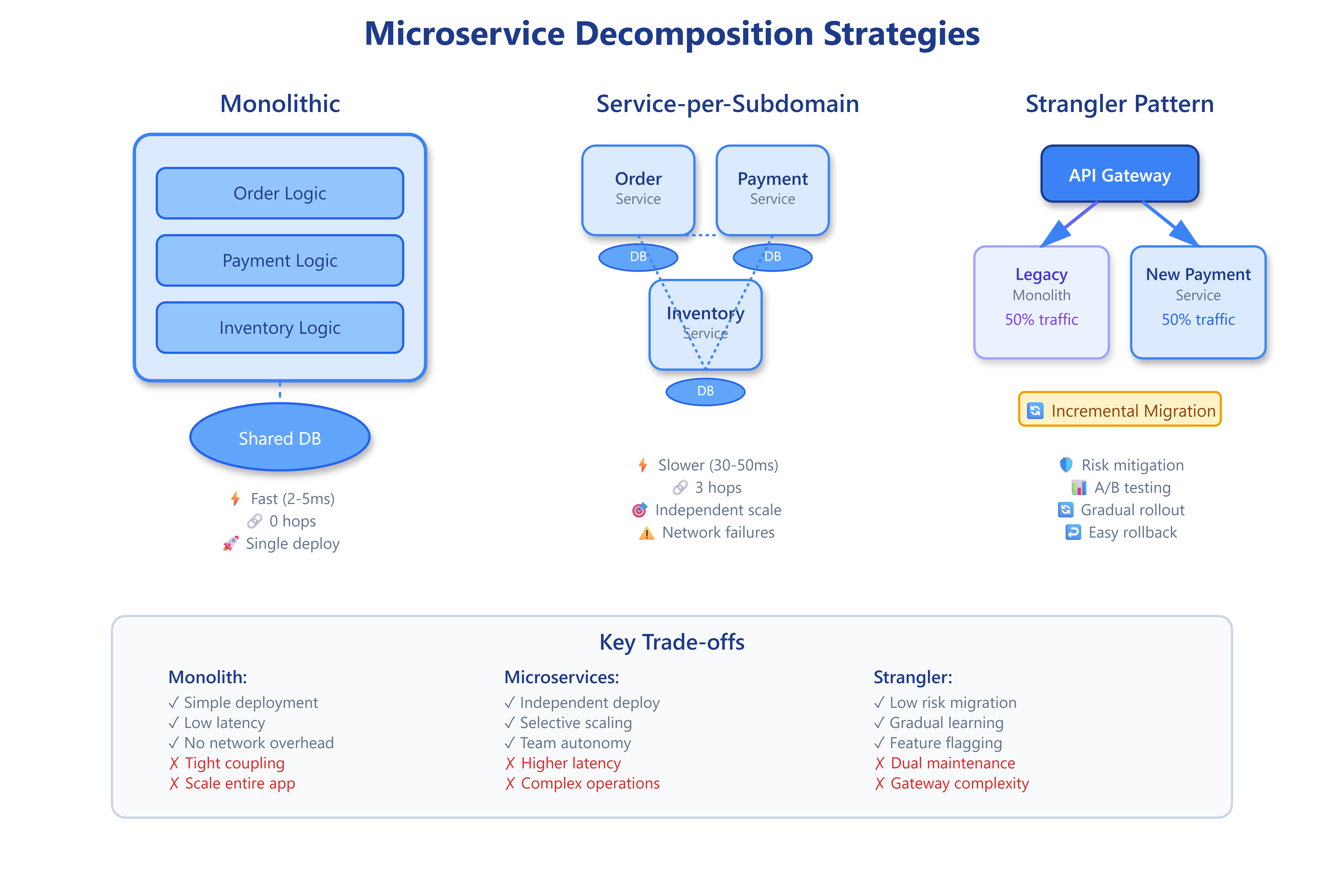
This diagram shows three architectural approaches side-by-side: monolithic (single deployment), service-per-subdomain (independent services), and strangler pattern (hybrid migration).
Critical Insights From the Trenches
Common Knowledge:
Start with the biggest pain points. If deployments block teams, extract the most frequently changing component first. If one module consumes 80% of resources, that’s your scaling bottleneck—decompose it.
The Database Trap:
Most decomposition failures stem from shared databases. Services must own their data completely. When OrderService and InventoryService share the products table, you haven’t created microservices—you’ve created a distributed monolith. True decomposition requires data duplication via events (eventual consistency) or synchronous APIs (tight coupling trade-off).
Transaction Boundaries Reveal True Boundaries:
If you need distributed transactions (saga patterns, two-phase commit) across services, your boundaries are wrong. Real bounded contexts have natural transaction boundaries. Uber’s trip lifecycle (request → match → ride → payment) crosses services, but each step completes atomically within one service before triggering the next.
The Pace-Layered Decomposition Insight:
Not all services need microservices architecture. Netflix identified three layers: highly volatile services (A/B testing, recommendations) deploy 50+ times daily; moderate change services (user profiles, billing) deploy weekly; stable core (DRM, encoding) changes quarterly. The volatile layer got aggressive decomposition; stable components stayed monolithic longer.
Cascading Failure Amplification:
Decomposition introduces network calls where none existed. Each call adds latency, failure modes, and retry logic. A monolith’s method call (microseconds, deterministic) becomes a network request (milliseconds, probabilistic). Ten service hops multiply failure probabilities exponentially—one 99.9% reliable service becomes 99% reliable when called ten times. This demands circuit breakers, timeouts, and fallback strategies.
The Organizational Conway’s Law:
Your architecture will mirror your team structure. If you have one backend team, you’ll build a backend monolith. Microservices require autonomous teams owning end-to-end service lifecycles—development, deployment, on-call rotation, and support. Decompose services to match team boundaries, not the other way around.
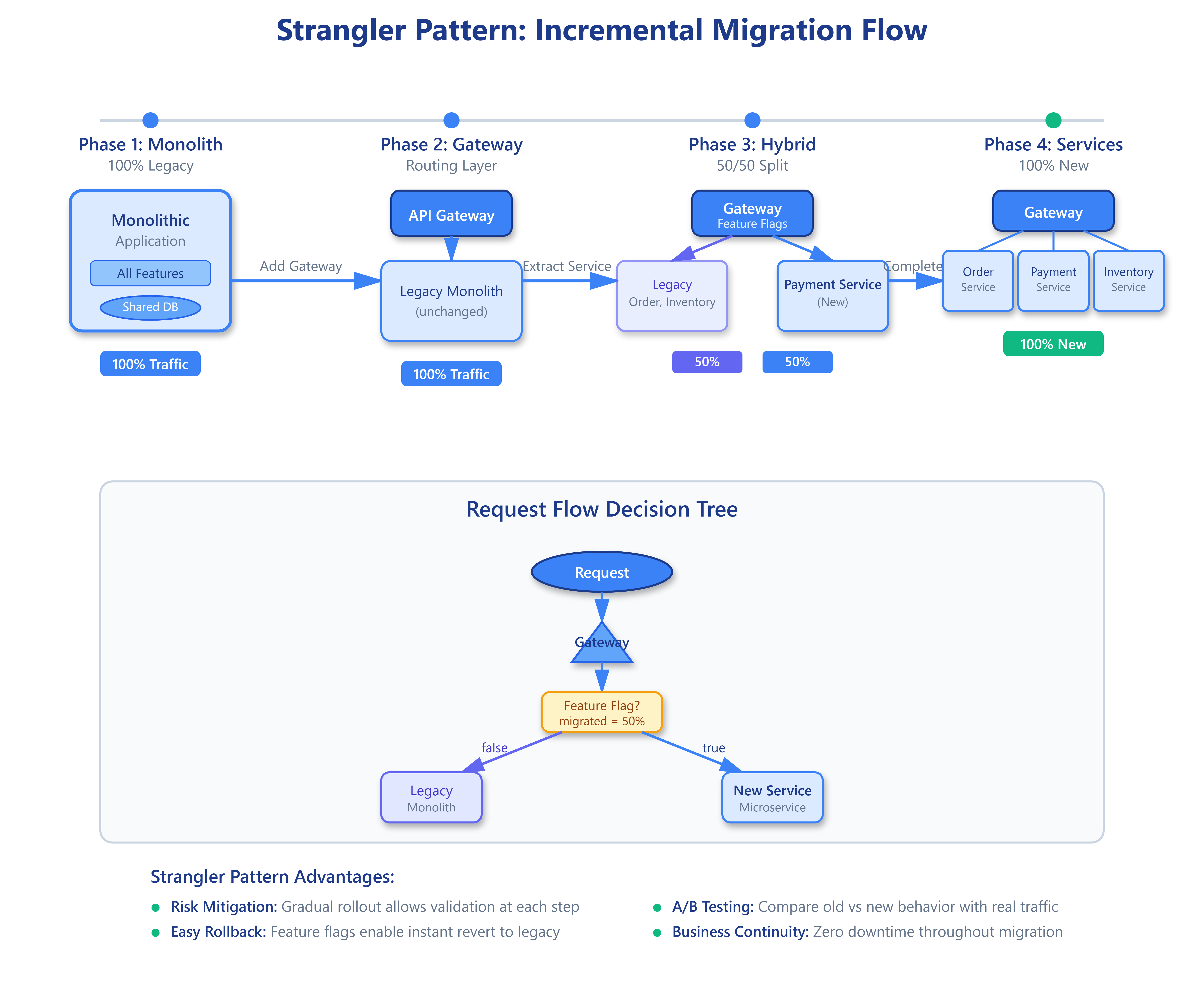
This diagram illustrates the strangler pattern migration flow across four phases, showing how traffic gradually shifts from legacy monolith to new microservices through a gateway layer.
Battle-Tested Patterns From Industry
Shopify’s Modular Monolith Approach:
Rather than full microservices, Shopify decomposed their Ruby monolith into enforced modules with strict dependency rules. Each module (Products, Orders, Customers) operates independently within a shared runtime, deployable together but logically isolated. This achieved 80% of microservices benefits (team autonomy, clear boundaries) without operational complexity.
Amazon’s Service-Oriented Architecture Evolution:
Starting in 2002, Amazon mandated all teams expose functionality only through service interfaces. They decomposed by business capability: each service handles one customer-facing function (recommendations, cart, checkout). Services communicate solely via APIs—no shared databases, no direct RPC calls. This enabled their famous “you build it, you run it” culture.
Uber’s Domain Gateway Pattern:
During decomposition, Uber created domain gateways sitting between mobile clients and microservices. The gateway aggregates multiple service calls, handles authentication, and provides backward compatibility as services evolve. This prevented client apps from needing updates with every service boundary change—crucial when millions of drivers can’t force-update their apps.
Architectural Considerations for Production
Decomposition introduces operational complexity that must be solved systematically. Distributed tracing (Jaeger, Zipkin) becomes mandatory—you can’t debug request flows spanning twelve services without correlation IDs threading through every call. Service mesh (Istio, Linkerd) handles cross-cutting concerns like retries, circuit breakers, and mTLS without polluting business logic.
Data consistency strategies fundamentally change. Synchronous consistency (immediate reads reflect writes) often becomes eventual consistency (events propagate within seconds). This breaks assumptions—an order confirmation might display before inventory decrements. Product teams must design UX accommodating eventual consistency (confirmation messages, async status updates).
Cost implications shift from CPU/memory optimization to network and coordination overhead. A monolith serves requests with single-digit millisecond latency; decomposed systems add 50-100ms per service hop. You’re trading raw performance for deployment velocity and scaling flexibility. Monitor cost per request carefully—some teams discover microservices cost 3x more to operate.
When to avoid decomposition: Early-stage startups, prototypes, and systems with unclear domain boundaries benefit from monoliths. Premature decomposition creates distributed complexity before business value justifies it. Wait until pain points emerge—slow deployments, scaling bottlenecks, team blocking—then decompose strategically.
Your Next Steps: See Decomposition in Action
The following hands-on demonstration lets you compare three decomposition strategies running side-by-side. You’ll see a simulated e-commerce system decomposed three ways: monolithic baseline, service-per-subdomain (Order, Payment, Inventory), and strangler pattern migration. The dashboard visualizes request flows, latency impacts, and failure propagation across architectures.
Experiment by triggering failures (kill services, inject latency) and observing how each architecture responds. Notice how the strangler pattern maintains monolith stability while incrementally routing traffic to services. Try modifying decomposition boundaries—split Payment into Authorization + Settlement—and see how transaction complexity changes.
For deeper learning, analyze your own system’s bounded contexts. Map data dependencies, identify transaction boundaries, and pinpoint team pain points. Start with one well-bounded, high-value component—authentication, reporting, or notifications. Extract it using the strangler pattern, validate the approach, then continue iteratively. Decomposition isn’t a big-bang rewrite; it’s strategic, incremental evolution guided by business needs.
Hands-On Implementation Guide
GitHub Link
https://github.com/sysdr/sdir/tree/main/Microservice_Decomposition_StrategiesThis section walks you through building a working demonstration of all three decomposition strategies. You’ll create real systems with actual order processing, payment authorization, and inventory management—no mock data or fake behavior.
What You’ll Build
Three complete e-commerce architectures running simultaneously:
Monolithic System - Single application handling all features (Order + Payment + Inventory)
Microservices System - Three independent services communicating over HTTP
Strangler Pattern System - Gateway routing 50% traffic to new services, 50% to legacy monolith
Each system includes a live dashboard showing real-time metrics, request latency, and architecture-specific behavior.
Prerequisites
Before starting, make sure you have these installed:
Docker and Docker Compose (for running containers)
A terminal or command prompt
A web browser
10 minutes of your time
That’s it. The setup script handles everything else automatically.
System Architecture Overview
Monolithic Architecture runs on port 3001. All business logic lives in one application. When you create an order, the code checks inventory, processes payment, and updates records with simple function calls—no network requests. Fast and simple, but the entire application must deploy together.
Microservices Architecture runs on ports 3002-3004. The Order Service (3002) coordinates requests by calling the Payment Service (3003) and Inventory Service (3004) over HTTP. Each service owns its database and can deploy independently. Slower due to network calls, but highly scalable.
Strangler Pattern runs on ports 3005-3007. A gateway (3005) receives all requests and randomly routes them: 50% go to the legacy monolith (3006), 50% go to the new Payment Service (3007). This simulates a gradual migration where new features route to microservices while legacy code continues serving traffic.
Step 1: Initial Setup
Make the setup script executable and run it:
bash
chmod +x setup.sh
bash setup.shThe script automatically:
Creates all required directories and files
Generates Node.js applications for each service
Builds Docker containers with optimized images
Starts all services with health checks
Launches the dashboard on port 8080
You’ll see output showing each service starting:
Building Docker containers...
Starting services...
Waiting for services to be healthy...
Setup Complete!
Access the dashboard: http://localhost:8080
Architecture endpoints:
Monolith: http://localhost:3001
Order Service: http://localhost:3002
Payment Service: http://localhost:3003
Inventory Service: http://localhost:3004
Strangler Gateway: http://localhost:3005Step 2: Explore the Dashboard
Open your browser and navigate to
http://localhost:8080
. You’ll see three architecture cards, each displaying:
Request count - Total orders processed
Error count - Failed requests
Average latency - Response time in milliseconds
Service hops - Number of network calls per request
Below the cards, a live log stream shows each request flowing through the systems with timestamps, architecture type, order IDs, and latency measurements.
Step 3: Test Each Architecture
Click the buttons to create orders through different architectures:
“Create Order (Monolith)” - Watch the monolith process orders in 2-5 milliseconds with zero service hops. All logic executes as function calls within a single process.
“Create Order (Microservices)” - Observe the increased latency (30-50ms) as the Order Service calls Payment and Inventory services over the network. Each request makes 3 service hops.
“Create Order (Strangler)” - Notice traffic splitting between legacy and new services. About half the requests show “route: legacy” and half show “route: new-payment”. This demonstrates gradual migration.
Create 10-20 orders through each architecture and compare the metrics. The monolith will show consistently low latency. Microservices will show higher but more variable latency. The strangler pattern will show mixed results based on routing.
Step 4: Run Automated Tests
Validate that all services work correctly:
bash
chmod +x test.sh
bash test.shThe test script checks:
Health endpoints on all seven services
Order creation in monolith architecture
Order creation in microservices architecture
Traffic splitting in strangler pattern (creates 5 orders)
Error handling for invalid products and excessive quantities
You should see output like:
Testing Health Endpoints
----------------------------
Testing Monolith Health... ✓ PASSED
Testing Order Service Health... ✓ PASSED
Testing Payment Service Health... ✓ PASSED
Testing Monolithic Architecture
-----------------------------------
Testing Monolith Order Creation... ✓ PASSED
Testing Monolith Metrics... ✓ PASSED
Test Summary
Passed: 18
Failed: 0
✓ All tests passed!Step 5: Interactive Demo
Run the interactive demo for guided exploration:
bash
chmod +x demo.sh
bash demo.shYou’ll see a menu with options:
Choose a demo scenario:
1) Create 10 orders (Monolith)
2) Create 10 orders (Microservices)
3) Create 10 orders (Strangler Pattern)
4) Load test all architectures (30 orders each)
5) Show metrics comparison
6) ExitSelect option 4 to run a load test. This creates 30 orders simultaneously through each architecture. Watch the dashboard update in real-time as requests flow through all three systems.
After the load test, select option 5 to see detailed metrics:
Monolith:
{
"architecture": "monolith",
"requests": 30,
"errors": 0,
"errorRate": "0%",
"orders": 30,
"avgLatency": "2-5ms"
}
Microservices (Order Service):
{
"service": "order",
"requests": 30,
"errors": 0,
"errorRate": "0%",
"orders": 30
}
Strangler Pattern:
{
"architecture": "strangler",
"totalRequests": 30,
"newServiceRequests": 14,
"legacyRequests": 16,
"migrationProgress": {
"payment": "50%",
"inventory": "0%"
}
}Notice the strangler pattern splits traffic roughly 50/50 between new and legacy services.
Understanding the Code
Each architecture implements the same e-commerce workflow differently.
Monolith Implementation: One Express.js server handles everything. When you POST to /api/monolith/order, the code:
Checks inventory with a simple object lookup (no network call)
Creates an order object and adds it to an in-memory array
Processes payment by creating a payment object
Updates inventory by decrementing the stock count
Returns the completed order
All operations execute in a single process with function calls. Total latency: 2-5 milliseconds.
Microservices Implementation: Three separate Express.js servers. When you POST to /api/orders, the Order Service:
Makes HTTP POST to Inventory Service to check stock (network call)
Creates an order object if inventory is available
Makes HTTP POST to Payment Service to process payment (network call)
Makes HTTP POST to Inventory Service to reserve items (network call)
Returns the completed order
Each network call adds latency and potential failure points. Total latency: 30-50 milliseconds.
Strangler Pattern Implementation: A gateway server decides where to route each request. When you POST to /api/strangler/order, the gateway:
Generates a random number between 0 and 1
If number < 0.5, routes to the new Payment Service (plus legacy for inventory)
If number >= 0.5, routes entirely to the legacy monolith
Returns the result with routing information
This simulates a gradual migration where you control the percentage of traffic going to new services through feature flags.
Observing Real Behavior
Try these experiments to see how architectures behave:
Experiment 1: Latency Comparison Create 50 orders through the monolith, then 50 through microservices. Compare average latency in the dashboard. The monolith should be 10-20x faster because it avoids network calls.
Experiment 2: Error Handling Create an order with productId: "INVALID". The monolith returns an error immediately. The microservices architecture might fail at different points (inventory check, payment processing) depending on service availability.
Experiment 3: Traffic Distribution Create 100 orders through the strangler pattern. Check the metrics to see the traffic split. It should be close to 50% new service, 50% legacy, demonstrating controlled migration.
Experiment 4: Service Independence Stop the Payment Service while keeping others running:
bash
docker stop $(docker ps -q --filter "name=payment-service")Now try creating microservices orders. They’ll fail because the Order Service can’t reach the Payment Service. But the monolith still works fine because it doesn’t depend on external services. Restart the service:
bash
docker-compose up -d payment-serviceCleanup
When you’re done exploring, clean up all resources:
bash
chmod +x cleanup.sh
bash cleanup.shThis script:
Stops all Docker containers
Removes Docker images
Deletes generated files and directories
Stops the dashboard server
You can run bash setup.sh again anytime to start fresh.
Key Takeaways
After completing this demonstration, you should understand:
Monoliths are fast and simple - No network overhead means low latency. Everything deploys together, which simplifies operations but limits independent scaling.
Microservices enable independence - Each service can deploy, scale, and evolve separately. This comes at the cost of higher latency, operational complexity, and potential failure modes.
Strangler pattern reduces risk - Gradual migration lets you validate each extraction before proceeding. Feature flags enable instant rollback if problems arise.
Architecture decisions have trade-offs - There’s no universally “best” architecture. Choose based on your team size, deployment frequency, scaling needs, and risk tolerance.
Start simple, evolve strategically - Begin with a monolith until pain points emerge. When deployments block teams or scaling becomes difficult, extract the highest-value services first using the strangler pattern.
The demonstration shows these concepts with real working code, not theory. You can modify the services, change routing logic, or add new features to explore further. The best way to learn system design is by building, breaking, and fixing real systems.
Further Exploration
Want to extend this demonstration? Try these challenges:
Add a new service:
Extract the Inventory logic from the legacy monolith into a new microservice. Update the strangler gateway to route inventory requests to the new service.
Implement circuit breakers:
Add timeout and retry logic to the Order Service. When the Payment Service fails, the circuit breaker should open and reject requests immediately instead of waiting.
Add database persistence:
Replace the in-memory arrays with PostgreSQL databases for each service. Observe how data ownership works in microservices versus shared databases in monoliths.
Build a saga pattern:
Implement compensating transactions. If payment succeeds but inventory reservation fails, automatically refund the payment to maintain consistency.
Create monitoring dashboards:
Add Prometheus metrics and Grafana dashboards to visualize request rates, error rates, and latency percentiles across all services.
Each challenge teaches important concepts in distributed systems design and helps you understand the real-world complexity of microservices architectures.