
Mitigating Cascading Failures in Distributed Systems :Architectural Analysis
In high-scale distributed architectures, a marginal increase in latency within a leaf service is rarely an isolated event. Instead, it frequently serves as the catalyst for cascading failures—a systemic collapse where resource exhaustion propagates upstream, transforming localized degradation into a total site outage.
The Mechanism of Resource Exhaustion
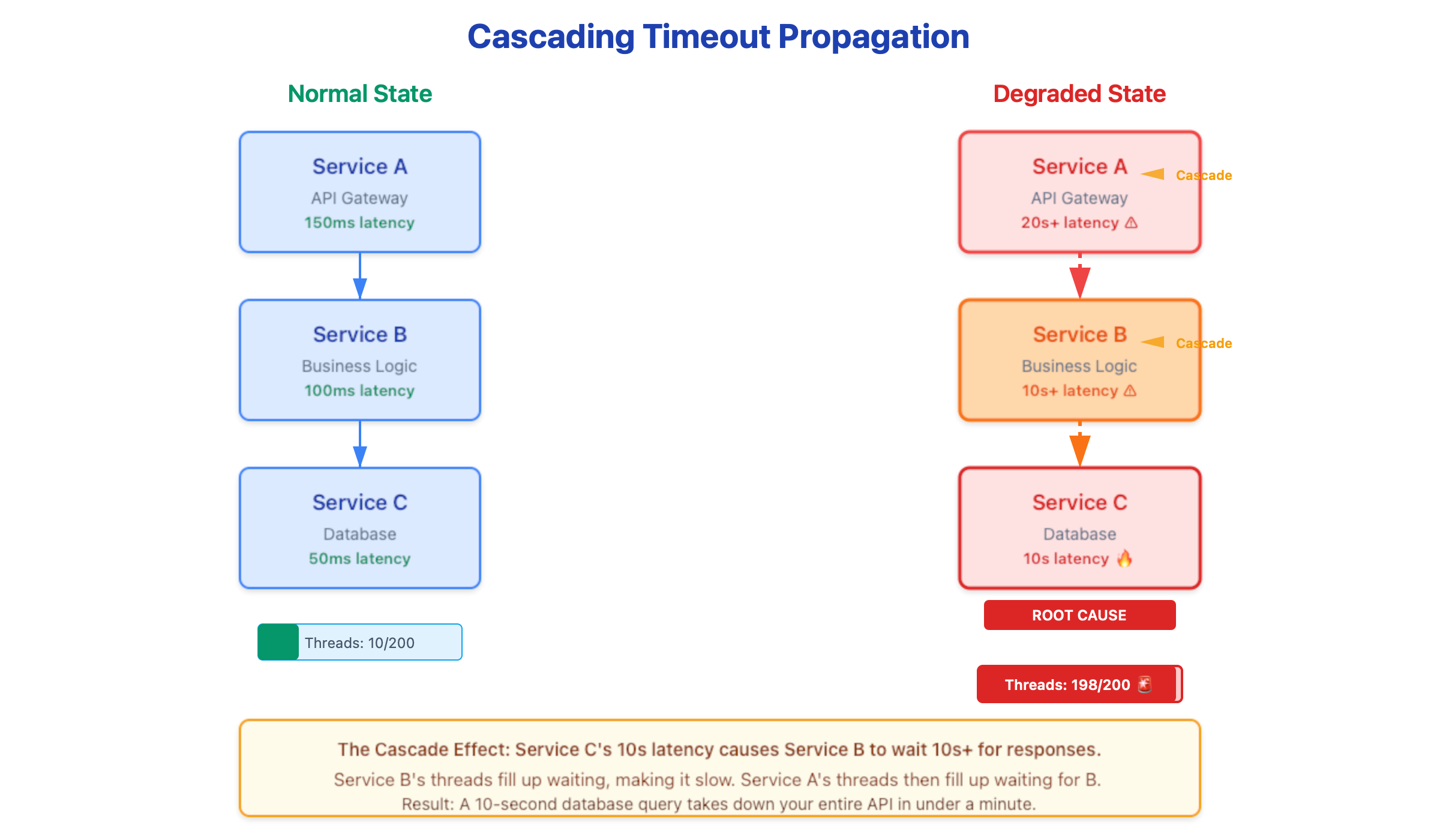
The fundamental vulnerability in many microservices architectures is the reliance on synchronous, blocking I/O within fixed thread pools. When a downstream dependency (e.g., a database or a third-party API) transitions from a 100ms response time to a 10-second latency, the calling service’s worker threads do not vanish; they become blocked.
Consider an API gateway utilizing a pool of 200 worker threads. If a downstream service slows significantly, these threads quickly saturate while waiting for I/O completion. Once the pool is exhausted, the service can no longer accept new connections, effectively rendering the system unavailable despite the process remaining “healthy” from a liveness-probe perspective. This is not a crash; it is thread starvation.
Critical Failure Vectors
1. The Fallacy of Permissive Timeouts
Engineers often default to 30- or 60-second timeouts to “ensure completion.” In a high-throughput environment, this is catastrophic. If your service handles 1,000 Requests Per Second (RPS) with 500 threads, a mere 500ms of additional latency will saturate your capacity in seconds. By the time a 30-second timeout fires, the service has been unresponsive for 29 seconds, likely triggering a secondary failure in the calling service.
2. Retry Amplification (The “Thundering Herd”)
Naive retry logic is a common multiplier for system stress. If Service A, B, and C each implement a “standard” 3-retry policy, a single upstream request can result in 3n calls to the failing leaf service. In a three-tier architecture, one user request generates 27 calls to a struggling backend, creating a self-inflicted Distributed Denial of Service (DDoS) attack that prevents recovery.
3. Latency Compounding
Latency does not merely add up; it compounds through the stack.
Service C (Leaf): 50ms → 10s
Service B: 100ms → 10s + overhead
Service A (Edge): 150ms → 20s (due to nested wait states)
Engineering Resilience: Defense-in-Depth
To prevent a localized hiccup from becoming a global catastrophe, several architectural patterns must be enforced:
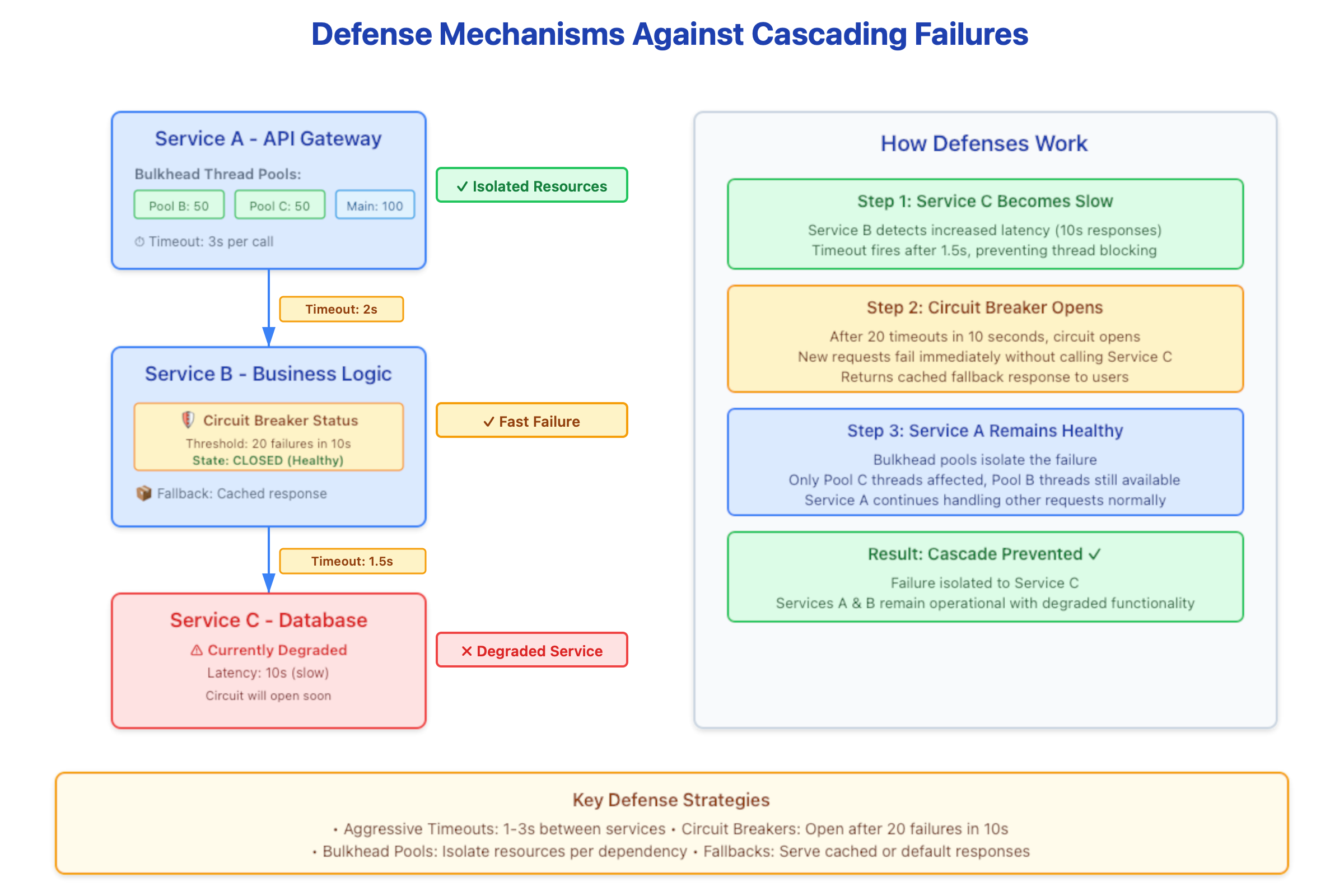
Deadline Propagation and Request Hedging
Rather than static timeouts, sophisticated systems utilize distributed tracing with deadline budgets. If an edge request has a total SLA of 10 seconds, that “budget” is passed in the header. If Service D receives a request with only 100ms of budget remaining, it should immediately reject the request (Fail Fast) rather than processing a call that is guaranteed to time out at the edge.
The Bulkhead Pattern
Borrowing from naval architecture, bulkheads isolate failures to specific pools. By implementing dedicated thread pools or semaphores per dependency, you ensure that a slow database call cannot consume the resources required for cache lookups or health checks.

Operational Monitoring: Leading vs. Lagging Indicators
Monitoring CPU and Error Rates is insufficient for detecting cascading timeouts until the system has already failed. High-performing SRE teams focus on:
Thread Pool Utilization: Alerts should trigger at 70% saturation, not 100%.
P99 Latency Deviations: A sudden shift in the 99th percentile is a leading indicator of downstream saturation.
Wait-Queue Depth: Measuring how long requests sit in the queue before being picked up by a worker thread.
Working Code demo :
https://github.com/sysdr/sdir/tree/main/cascading_failure
Summary
Cascading timeouts represent the “silent killer” of distributed systems because they exploit the gaps between services. Resilience is not achieved by hoping for high availability from every component, but by designing services that aggressively defend their own resources against the inevitable degradation of their neighbors.