
Multi-Region Database Deployments: Mastering Global Data Distribution at Scale
Hands On System Design Coding Course
Stop Drawing Boxes. Start Building Systems. Subscribe Now
The gap between a “system design interview” and a “production system” is massive. This newsletter exists to bridge that gap.
When you join any organisation, no one is going to teach you how system is design or built. Fun part developers rarely document everything. you need to dig through to understand the system. I created this course because I believe the best way to learn distributed systems is by building them. We don’t just talk about the CAP theorem; we look at how it dictates our database choices. We don’t just mention “latency”; we measure it. Subscribe
Keep reading till end to get a free guide with code example - Multi-Region Database Implementation Guide.
You're jolted awake by your phone buzzing relentlessly. Your e-commerce platform, which serves customers across five continents, has gone dark in Asia-Pacific. While your primary database in Virginia is humming along perfectly, 40% of your global user base can't access their shopping carts, order histories, or make purchases. The latency from Singapore to Virginia has spiked to 2.3 seconds per query, and your Asian customers are abandoning their sessions faster than you can count the lost revenue.
This scenario isn't hypothetical—it's the reality that drove companies like Shopify, Netflix, and Discord to architect some of the most sophisticated multi-region database systems ever built. Today, we'll dive deep into the art and science of distributing your data across the globe while maintaining the holy trinity of database systems: consistency, availability, and partition tolerance.
Why Geographic Distribution Isn't Just About Speed
Most engineers think multi-region deployments are simply about reducing latency. While that's important, the real drivers run much deeper and touch every aspect of your business architecture.
Regulatory Compliance Demands Geographic Boundaries Modern data protection laws like GDPR, CCPA, and emerging regulations in Brazil, India, and Southeast Asia mandate that certain types of user data must physically reside within specific geographic boundaries. When WhatsApp processes messages from European users, that data must remain within EU borders—not as a performance optimization, but as a legal requirement. This creates hard constraints that shape your entire data architecture.
Disaster Recovery Beyond Single Points of Failure Traditional disaster recovery focuses on hardware failures or data center outages. Multi-region deployments protect against much larger systemic failures: submarine cable cuts (which happen more often than you'd think), regional natural disasters, or even geopolitical events that can isolate entire regions. When GitHub's primary region experienced extended connectivity issues in 2021, their multi-region architecture kept European and Asian developers productive while US-East recovered.
Economic Optimization at Hyperscale Here's an insight most don't discuss: data gravity creates compound economic effects. When Netflix stores popular content closer to viewers, they don't just reduce CDN costs—they also reduce the load on their recommendation engines, decrease the complexity of their global caching layers, and enable more sophisticated regional personalization without cross-region API calls. The savings cascade through every layer of their architecture.
The Hidden Complexity Matrix
Multi-region database deployments introduce a complexity matrix that grows exponentially, not linearly, with each region you add. Understanding this matrix is crucial for making informed architectural decisions.
Data Consistency Across Time Zones
When your database spans regions, you're not just dealing with network partitions—you're dealing with time itself. Consider a financial trading application where a user in Tokyo places an order at 9:00 AM JST, which gets replicated to your New York region where it's processed at 8:00 PM EST the previous day. Your application logic must handle not just eventual consistency, but temporal consistency across regions where clocks may be slightly skewed and business rules may vary by jurisdiction.
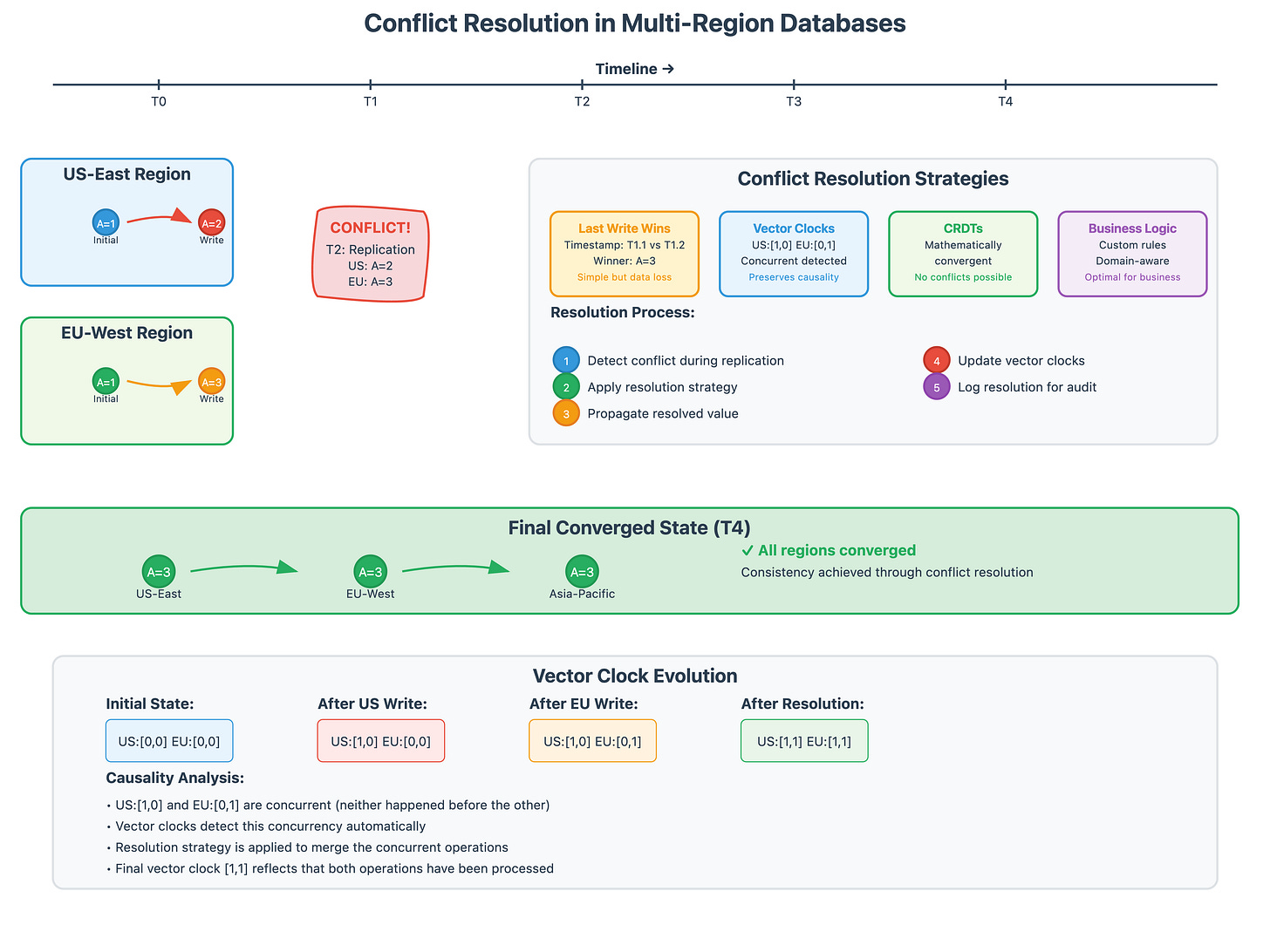
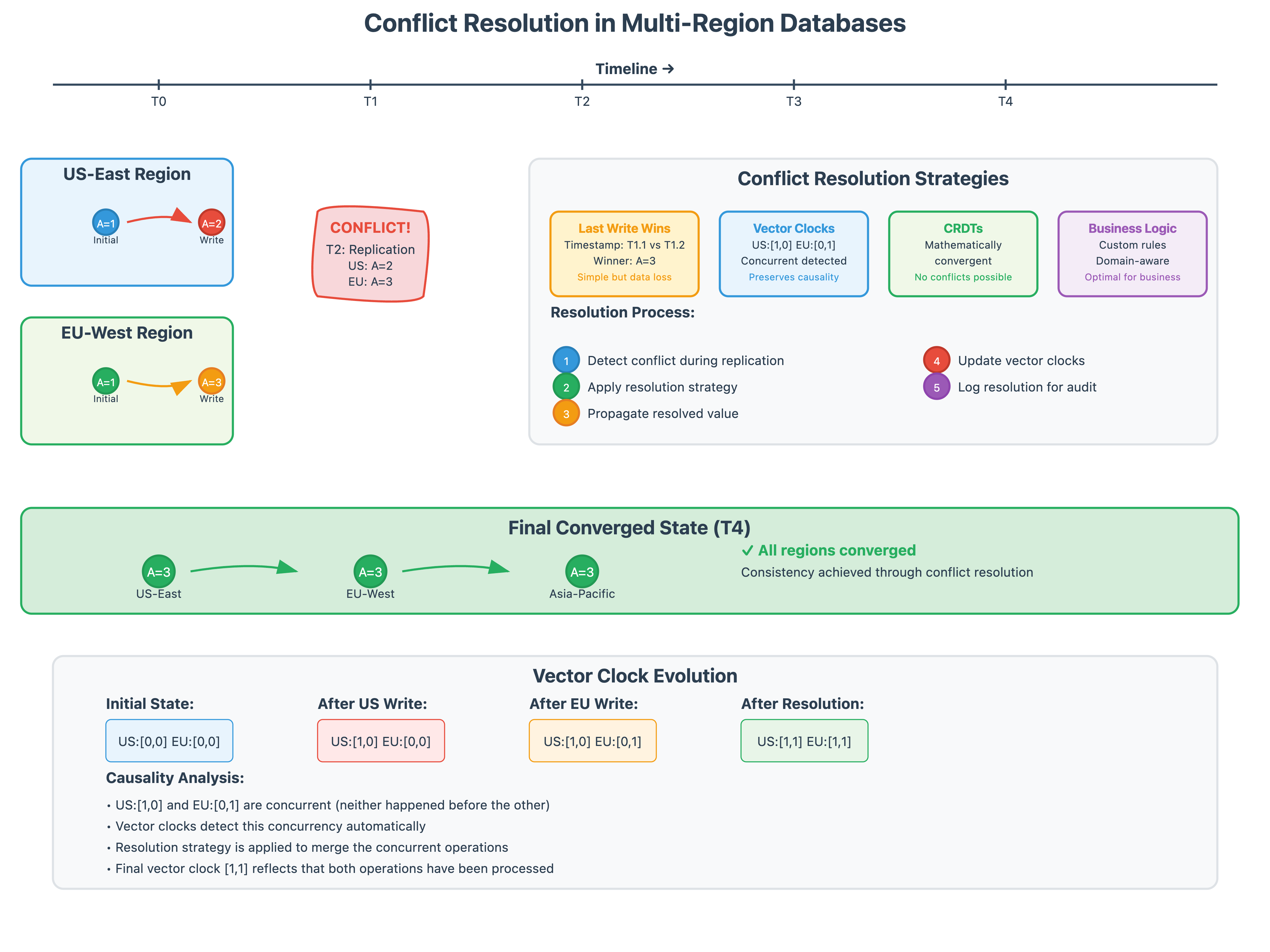
The Lamport Timestamp Solution Systems like CockroachDB and Spanner solve this using logical clocks (Lamport timestamps) combined with atomic clocks. Every transaction gets a globally unique timestamp that respects causality, even when physical clocks are skewed. This isn't just theoretical—it's essential for maintaining audit trails and preventing race conditions in global financial systems.
Network Partition Handling
Regional networks fail in ways that are fundamentally different from single-datacenter failures. A partition between US-East and EU-West might last 30 minutes due to a cable cut, during which both regions need to continue serving traffic. Your consistency model must account for these "split-brain" scenarios where each region believes it's the authoritative source of truth.
Conflict-Free Replicated Data Types (CRDTs) Discord uses CRDTs extensively for their chat system. When a user sends a message, it needs to appear immediately in their regional UI while eventually propagating globally. CRDTs ensure that regardless of the order in which operations are applied across regions, the final state converges to the same result. This mathematical guarantee is what allows Discord to maintain real-time chat performance globally without sacrificing consistency.
Core Architecture Patterns for Multi-Region Success
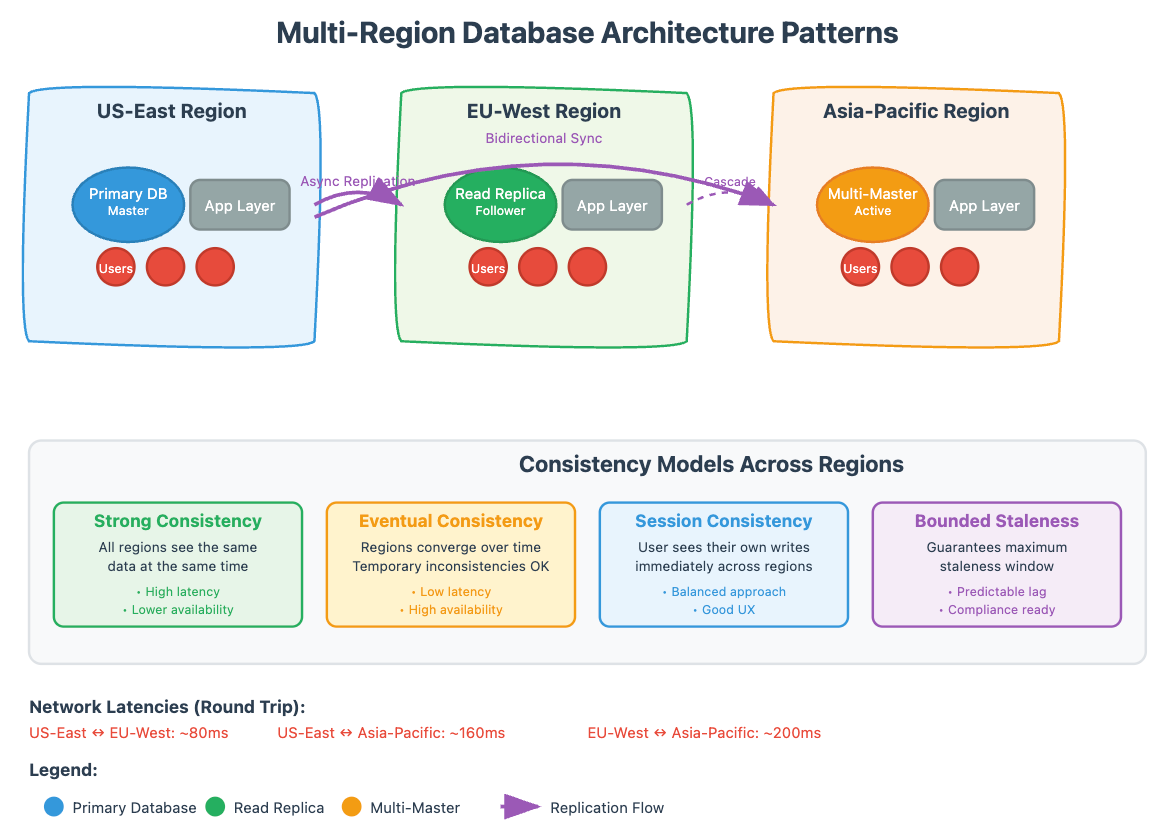
Pattern 1: Regional Read Replicas with Global Primary
This is often the first step for companies scaling globally, but it's more nuanced than most implementations suggest.
Smart Replica Placement Don't just place replicas based on user geography. Consider data access patterns, regulatory requirements, and failure correlation. Stripe places their read replicas not just in regions with high transaction volume, but also in regions that are geographically and politically independent from their primary regions. This protects against correlated failures that could affect multiple regions simultaneously.
Dynamic Read Routing Advanced implementations use intelligent routing that considers not just geographic proximity, but current replica lag, regional load, and even predictive analytics about likely data access patterns. When a user logs in, the system can predict which data they're likely to access and pre-warm the appropriate regional caches.
Pattern 2: Multi-Master Active-Active Configuration
This pattern provides the highest availability but introduces the most complex consistency challenges.
Conflict Resolution Strategies Real-world systems use sophisticated conflict resolution beyond simple "last-write-wins." Airbnb's booking system uses business-logic-aware conflict resolution where booking conflicts are resolved based on payment timestamp, user tier, and even historical booking behavior. The system doesn't just resolve conflicts—it does so in a way that maximizes business value while maintaining user trust.
Vector Clocks and Causal Ordering Vector clocks track the causal relationships between operations across regions. When a user updates their profile in one region and then immediately makes a purchase in another region, the vector clock ensures the purchase operation sees the updated profile, even if the regions are temporarily partitioned.
Pattern 3: Federated Database Architecture
This emerging pattern treats each region as an autonomous database federation member, with sophisticated inter-region protocols for data synchronization and query federation.
Cross-Region Query Optimization Modern federated systems can execute queries that span multiple regions by analyzing the query plan and determining the optimal data movement strategy. Instead of bringing all data to a single region, they can push computations to where the data lives and only transfer the minimal result set.
Real-World Implementation Deep Dive: How Netflix Architected Global Data Distribution
Netflix's multi-region database architecture represents one of the most sophisticated implementations in production today. Their approach offers several non-obvious insights that apply beyond video streaming.
The Microservice Data Federation Model
Netflix doesn't use a single global database. Instead, they architect around hundreds of microservices, each with its own multi-region data strategy optimized for that service's specific access patterns and consistency requirements.
User Profile Service: Uses a global primary in US-West with read replicas in each region where Netflix operates. Profile updates are rare but reads are frequent, making this pattern optimal.
Viewing History Service: Uses a multi-master setup where each region can independently record viewing events. Conflicts are resolved using a custom CRDT that merges viewing histories while preserving the temporal order of viewing events.
Recommendation Engine: Uses a hybrid approach where user preferences are globally replicated, but recommendation computations are performed regionally using locally optimized models. This reduces cross-region bandwidth while improving recommendation relevance for regional content.
The Cascade Replication Strategy
Netflix developed a unique replication topology called "cascade replication" where data flows through strategically placed intermediate regions before reaching its final destinations. This reduces the load on source regions and provides natural disaster recovery waypoints.
For example, user data might flow: US-West → US-East → EU-West → Asia-Pacific. Each intermediate region can serve as a failover point and reduces the replication load on the primary region.
Advanced Consistency Models: Beyond Eventual Consistency
Session Consistency in Multi-Region Systems
Session consistency ensures that within a single user session, reads reflect the effects of previous writes by that same user, even across regions. This is crucial for user experience but challenging to implement efficiently.
Implementation Strategy: Use session tokens that encode the timestamp of the user's last write operation. When the user makes a request to any region, that region waits until its local replica has caught up to at least that timestamp before serving the request.
Discord's Implementation: Discord uses a variation where they encode both timestamp and region information in session tokens. This allows them to route users to regions that are most likely to have their recent data while falling back gracefully when that's not possible.
Bounded Staleness Guarantees
Bounded staleness provides guarantees about how "old" data might be in any given region. This is particularly important for financial applications where regulatory requirements may specify maximum staleness windows.
Implementation Techniques: Use hybrid logical clocks combined with region-specific staleness monitoring. Each region maintains metrics about its replication lag and can dynamically route queries to regions that meet the required staleness bounds for specific operations.
The Economics of Multi-Region Data: Cost Optimization Strategies
Data Tiering Across Regions
Not all data needs to be hot in all regions. Implement intelligent data tiering where frequently accessed data is kept hot in multiple regions, while less frequently accessed data is stored in cheaper, higher-latency storage in fewer regions.
Spotify's Approach: They keep the last 30 days of listening data hot in all regions, the last year warm in three regions, and historical data beyond that in cold storage in a single region. Their application layer transparently handles the different access patterns and latencies.
Bandwidth Optimization Through Compression and Delta Sync
Cross-region bandwidth is expensive and often the largest cost component of multi-region deployments.
Advanced Compression Strategies: Use application-aware compression that understands your data patterns. JSON can often be compressed by 80-90% using schema-aware compression techniques that are much more efficient than generic compression.
Delta Synchronization: Instead of replicating entire records, implement delta sync that only transfers the changed fields. This is particularly effective for user profiles and configuration data where updates typically affect only a small subset of fields.
Operational Excellence: Monitoring and Observability
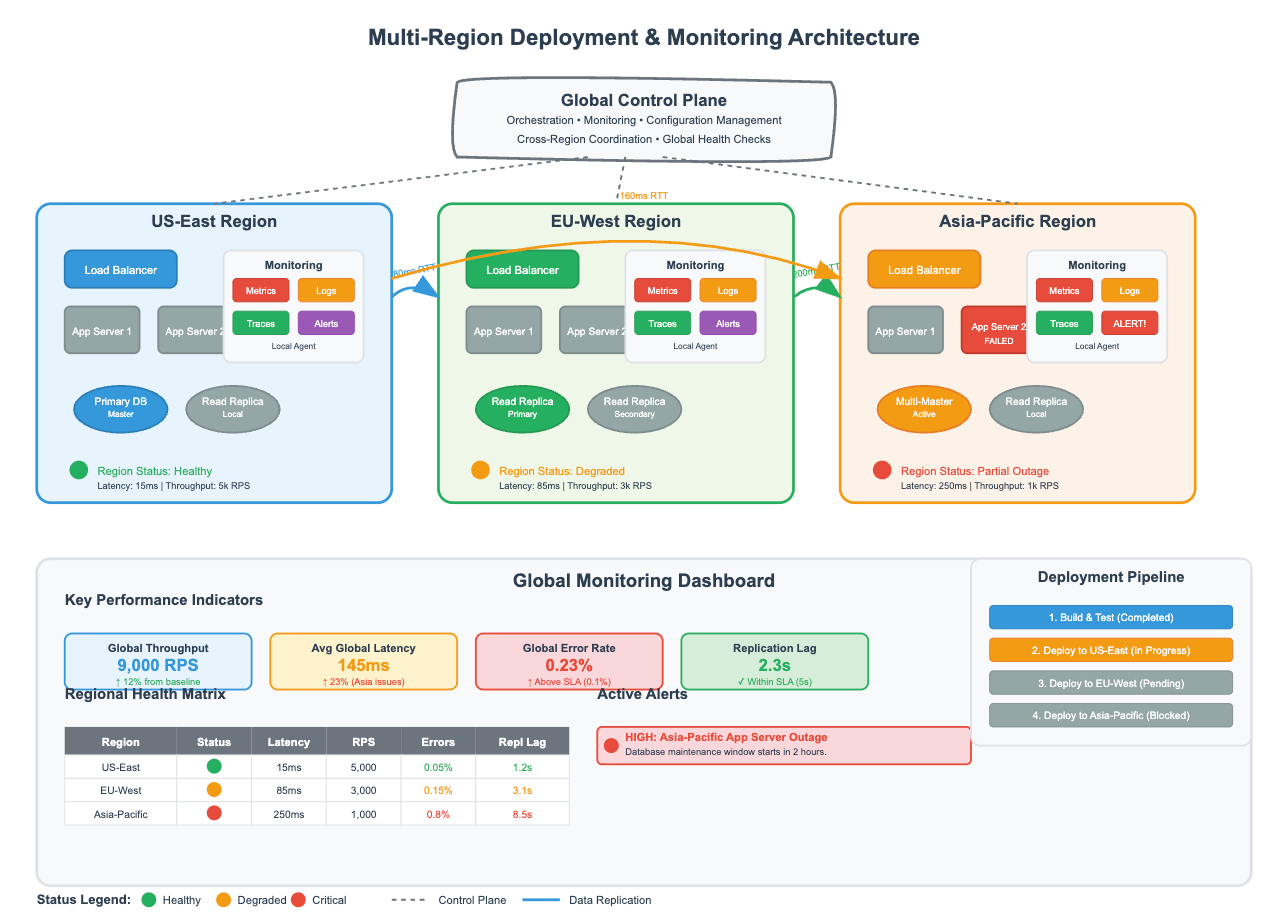
Cross-Region Distributed Tracing
Traditional APM tools struggle with multi-region distributed tracing. Implement trace correlation that can follow a single user request as it fans out across multiple regions and aggregate the results.
Key Metrics to Track:
Cross-region replication lag by data type and region pair
Conflict resolution frequency and resolution latency
Regional failover frequency and recovery time
Data freshness percentiles by region
Cross-region query success rates and latencies
Automated Consistency Validation
Implement automated consistency checking that continuously validates data integrity across regions. This should include not just data checksums, but also business-logic consistency validation.
Example Implementation: Run daily jobs that select random data samples from each region and validate that they converge to the same values within expected timeframes. Alert on anomalies and maintain historical consistency metrics.
Common Pitfalls and How to Avoid Them
The "Read Your Writes" Assumption
Many applications assume that a write operation will be immediately visible to subsequent read operations by the same user. In multi-region deployments, this assumption can break in subtle ways.
Solution: Implement read-after-write consistency through session affinity or by including write timestamps in client responses and waiting for replication to catch up before serving reads.
Underestimating Operational Complexity
Multi-region deployments don't just multiply your operational complexity by the number of regions—they create exponential complexity in monitoring, debugging, and incident response.
Mitigation Strategy: Invest heavily in automation and standardization. Every region should be deployed using identical automation, with regional variations handled through configuration, not custom deployment processes.
Ignoring Regulatory Fragmentation
Data residency requirements are becoming increasingly complex and fragmented. What's legal in one jurisdiction may be prohibited in another, and these requirements change frequently.
Approach: Design your data architecture with fine-grained geographic controls from day one. Build the capability to migrate specific data types or user cohorts between regions without application downtime.
Building Your Multi-Region Strategy: A Practical Implementation Path
Phase 1: Regional Read Replicas (Months 1-3)
Start with read replicas in your primary geographic markets. This provides immediate latency benefits with minimal consistency complexity.
Implementation Steps:
Set up read replicas in 2-3 strategic regions
Implement intelligent read routing based on user geography
Monitor replication lag and establish SLAs
Build operational runbooks for replica failure scenarios
Phase 2: Regional Write Capabilities (Months 4-9)
Introduce the ability to accept writes in multiple regions for specific data types that can tolerate eventual consistency.
Implementation Steps:
Identify data types suitable for multi-master replication
Implement conflict resolution strategies
Build monitoring for cross-region consistency
Test failover scenarios extensively
Phase 3: Full Multi-Region Architecture (Months 10-18)
Evolve to a complete multi-region architecture with sophisticated consistency guarantees and operational excellence.
Implementation Steps:
Implement session consistency guarantees
Build cross-region distributed tracing
Develop automated consistency validation
Create region-specific disaster recovery procedures
The Future of Multi-Region Databases
Edge Database Deployments
The next evolution is pushing database capabilities to the edge, closer to users than traditional regional deployments. Companies like Cloudflare and Fastly are pioneering edge databases that can serve queries with sub-10ms latency globally.
AI-Driven Consistency Management
Machine learning is beginning to play a role in predicting optimal consistency models based on application behavior patterns. Future systems will dynamically adjust consistency levels based on real-time analysis of access patterns and business requirements.
Quantum-Safe Security Across Regions
As quantum computing advances, multi-region systems will need to implement quantum-safe encryption for cross-region communications. This will require rethinking how we secure data in transit between regions.
Your Next Steps: From Theory to Production
The journey from single-region to multi-region isn't just a technical challenge—it's a organizational transformation that touches every aspect of how you build, deploy, and operate software.
Start Small, Think Big: Begin with read replicas in one additional region, but architect your data models and application logic from day one to support eventual multi-region writes. The refactoring required to retrofit multi-region capabilities into a single-region application is often more expensive than rebuilding from scratch.
Invest in Operational Maturity: Multi-region deployments will expose every weakness in your operational practices. Use this as an opportunity to level up your monitoring, alerting, deployment automation, and incident response capabilities.
Build Cross-Functional Expertise: Multi-region success requires close collaboration between engineers, product managers, legal teams, and business stakeholders. The technical architecture decisions you make will have direct impacts on product capabilities, regulatory compliance, and business operations.
The companies that master multi-region database deployments don't just gain a technical advantage—they gain the ability to serve global markets with the same reliability and performance that their competitors can only provide locally. In an increasingly connected world, this capability isn't just a competitive advantage; it's becoming a prerequisite for global scale.
Remember: every millisecond of latency you eliminate, every nine of availability you add, and every consistency guarantee you provide translates directly into user satisfaction, revenue growth, and market expansion opportunities. The investment in multi-region expertise pays dividends not just in technical capabilities, but in business outcomes that compound over time.
Free Gift - > Multi-Region Database Implementation Guide.pdf
In our next article, we'll explore Database Caching Layers, where we'll dive into the sophisticated caching strategies that make multi-region deployments performant and cost-effective. We'll cover everything from regional cache warming to cross-region cache invalidation strategies that keep your global data access patterns optimal.