Optimistic Locking vs. Pessimistic Locking: Handling Concurrency in High-Traffic Systems
The Hidden Cost of Waiting
Imagine 10,000 users clicking “Buy Now” on the last concert ticket simultaneously. Without proper locking, you’d oversell. With pessimistic locking, 9,999 requests wait in line while one completes. With optimistic locking, all 10,000 race to completion, but only one succeeds without blocking others. This fundamental trade-off—blocking vs. retrying—shapes how every high-traffic system handles concurrent writes.
Core Mechanisms
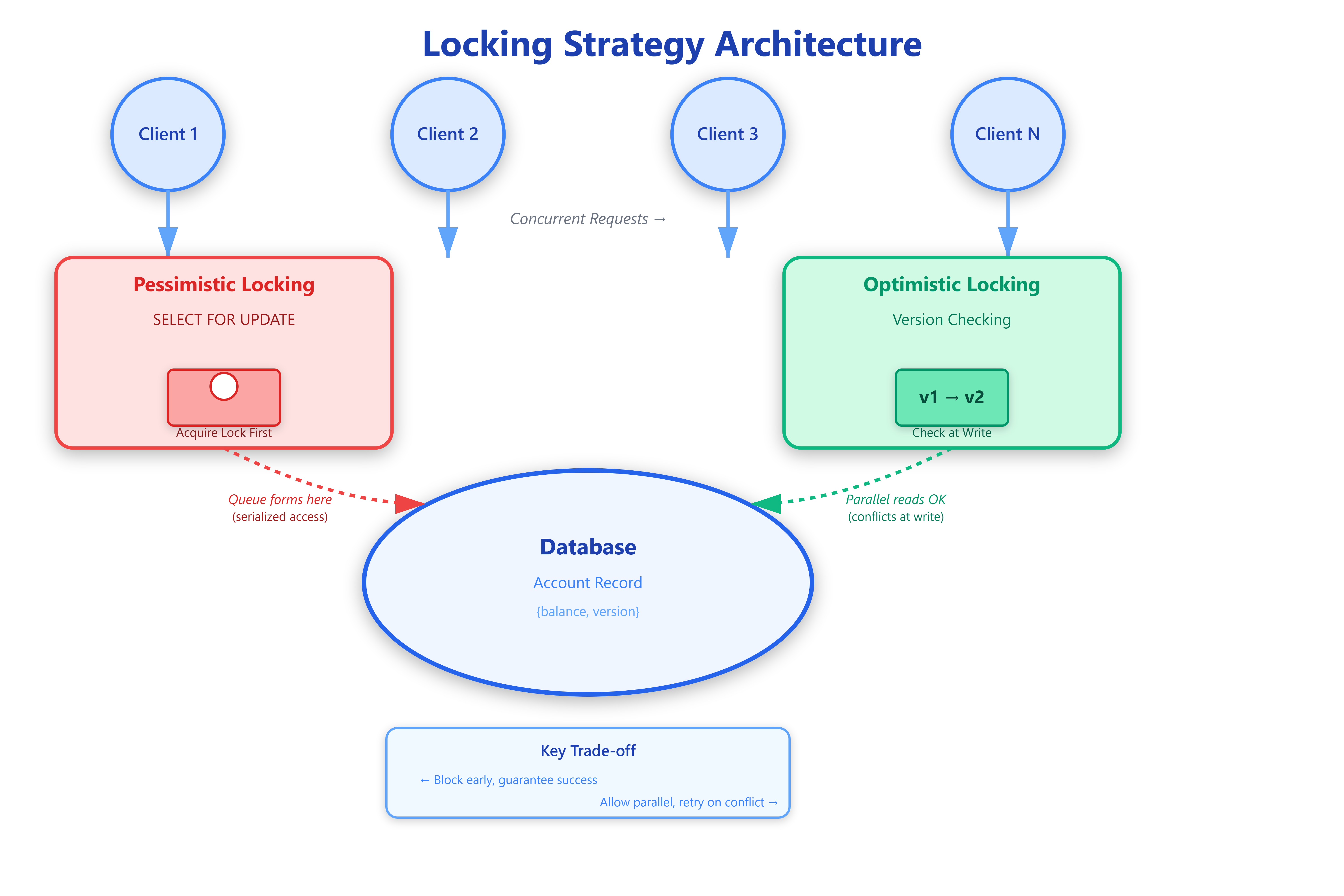
Pessimistic locking assumes conflicts will happen, so it prevents them upfront by acquiring exclusive locks. When a transaction reads data, it blocks all other transactions from accessing that data until the lock releases. Think database row-level locks with SELECT FOR UPDATE or distributed locks with Redis/Zookeeper.
The mechanism is straightforward: Transaction A requests a lock, obtains it, performs read-modify-write operations, then releases the lock. During this window, Transaction B attempting the same operation blocks until A completes. This serializes operations, guaranteeing consistency but sacrificing parallelism.
Optimistic locking assumes conflicts are rare, allowing concurrent reads without blocking. Instead of preventing conflicts, it detects them at write time using version numbers or timestamps. Each record carries a version field incremented on every update. When writing, the transaction checks if the version matches what was originally read—if not, the write fails and the client must retry.
Here’s the critical difference in behavior: pessimistic locking creates contention at read time, while optimistic locking discovers conflicts at write time. Pessimistic systems accumulate blocked threads waiting for locks; optimistic systems accumulate failed attempts and retries.
Non-obvious failure patterns emerge at scale. With pessimistic locks, a crashed transaction holding a lock can deadlock your entire system until timeout expires (typically 30-60 seconds). Lock timeouts become critical tuning parameters—too short and you abort legitimate long-running transactions; too long and crashed processes hold resources hostage.
Optimistic locking fails differently. Under high contention, retry storms can cascade. If 100 transactions collide, 99 fail and retry simultaneously, creating another collision wave. Without exponential backoff and jitter, you transform a concurrency problem into a thundering herd problem.