Post-Mortem Process: Learning from Failures
Issue #134: System Design Interview Roadmap • Section 5: Reliability & Resilience
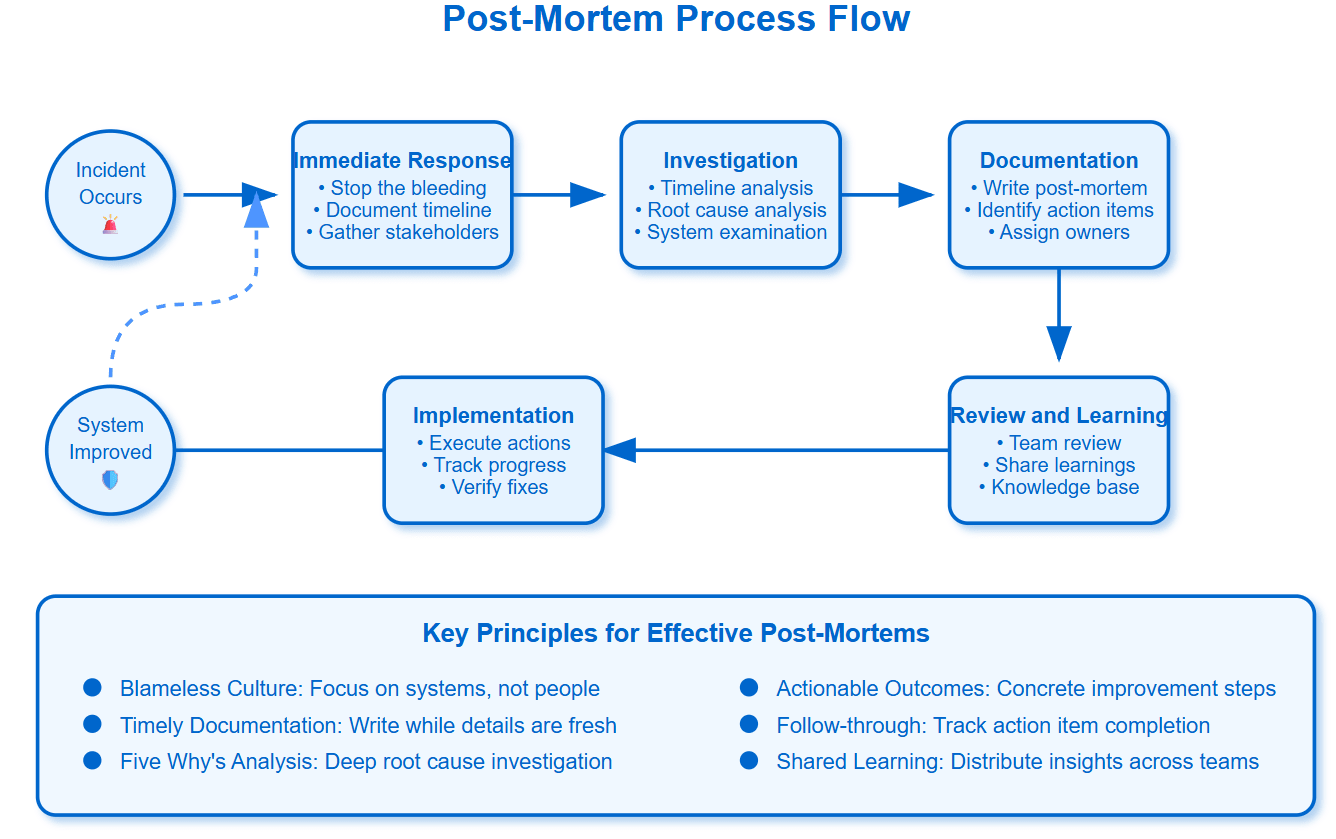
What We'll Learn Today
Why post-mortems are your system's learning superpower
The anatomy of blameless post-mortems that actually prevent future incidents
Real-world post-mortem processes from Netflix, Google, and Amazon
Building a culture where failures become competitive advantages
Youtube Video:
The $100 Million Lesson
When AWS S3 went down in February 2017, it took half the internet with it. Slack, Trello, GitHub—all dark. But here's what most people missed: AWS didn't just fix the bug and move on. They published a detailed post-mortem that became a masterclass in transparency and systematic learning.
That post-mortem didn't just prevent future S3 outages—it influenced how the entire industry thinks about operational resilience. This is the power of treating failures as learning opportunities rather than blame assignments.
The Blameless Revolution
Traditional incident responses focus on who broke something. Effective post-mortems focus on how the system allowed something to break. This shift from person-focused to system-focused analysis unlocks genuine learning.