
Redundancy Patterns in System Design
Issue #114: System Design Interview Roadmap • Section 5: Reliability & Resilience

When Netflix Stayed Online During the Great AWS Outage
In December 2012, when AWS's entire East Coast region went dark for hours, most companies watched helplessly as their services vanished. Netflix? Their streaming kept running seamlessly for 230 million users. The secret wasn't luck—it was redundancy patterns so sophisticated that losing an entire AWS region was just another Tuesday.
Today, you'll master the redundancy patterns that separate resilient systems from fragile ones, and build a working demonstration that shows exactly how these patterns prevent catastrophic failures.
What You'll Master Today
Core Redundancy Patterns: Active-Active, Active-Passive, and N+1 redundancy strategies
Geographic Distribution: Multi-region deployments that survive datacenter failures
Data Redundancy: Replication strategies that ensure zero data loss
Service Redundancy: Load balancing and failover mechanisms
Implementation: Build a resilient system with automatic failover
The Redundancy Spectrum: Beyond Simple Duplication
Most engineers think redundancy means "run two of everything." This oversimplification leads to expensive systems that still fail catastrophically. True redundancy requires understanding failure correlation and designing around it.
Active-Active: The Performance Multiplier
In Active-Active redundancy, all instances serve traffic simultaneously. This pattern doesn't just provide redundancy—it multiplies your system's capacity while eliminating single points of failure.
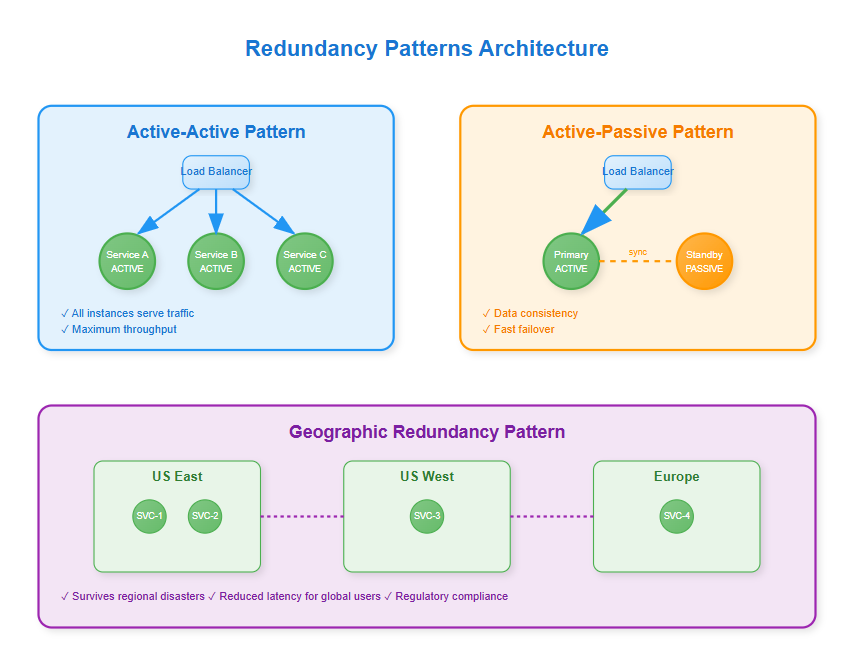
The Hidden Complexity: Maintaining data consistency across active instances. When both instances can write, you need sophisticated conflict resolution or careful data partitioning. Amazon's DynamoDB uses eventual consistency with last-writer-wins, while Google's Spanner uses synchronized clocks for strict consistency.
Production Insight: Netflix runs Active-Active across three AWS regions. Each region can handle 100% of global traffic, but normally serves 33%. When one region fails, the others automatically absorb its load with zero user impact.