
Scaling Search Functionality in Applications
Issue #102: System Design Interview Roadmap • Section 4: Scalability
What We'll Learn Today
Today we're constructing a production-grade distributed search system that handles millions of queries per second. You'll implement multiple search strategies, build real-time indexing pipelines, and create a performance comparison dashboard. By the end, you'll understand why Netflix rebuilds their entire search index every few hours and how Google processes 8.5 billion searches daily without breaking a sweat.
The Search Scaling Crisis
When your application grows from thousands to millions of users, search becomes your first major bottleneck. That innocent WHERE title LIKE '%query%' query that worked perfectly in development suddenly consumes 90% of your database CPU in production. The cruel irony? Users expect sub-100ms search responses while your database takes 2 seconds to scan through millions of records.
The fundamental challenge isn't just performance—it's the exponential growth of search complexity. As your data volume doubles, naive search approaches don't just slow down linearly; they degrade exponentially. A database table scan that takes 50ms with 100,000 records will take 5 seconds with 10 million records, assuming your database doesn't crash first.
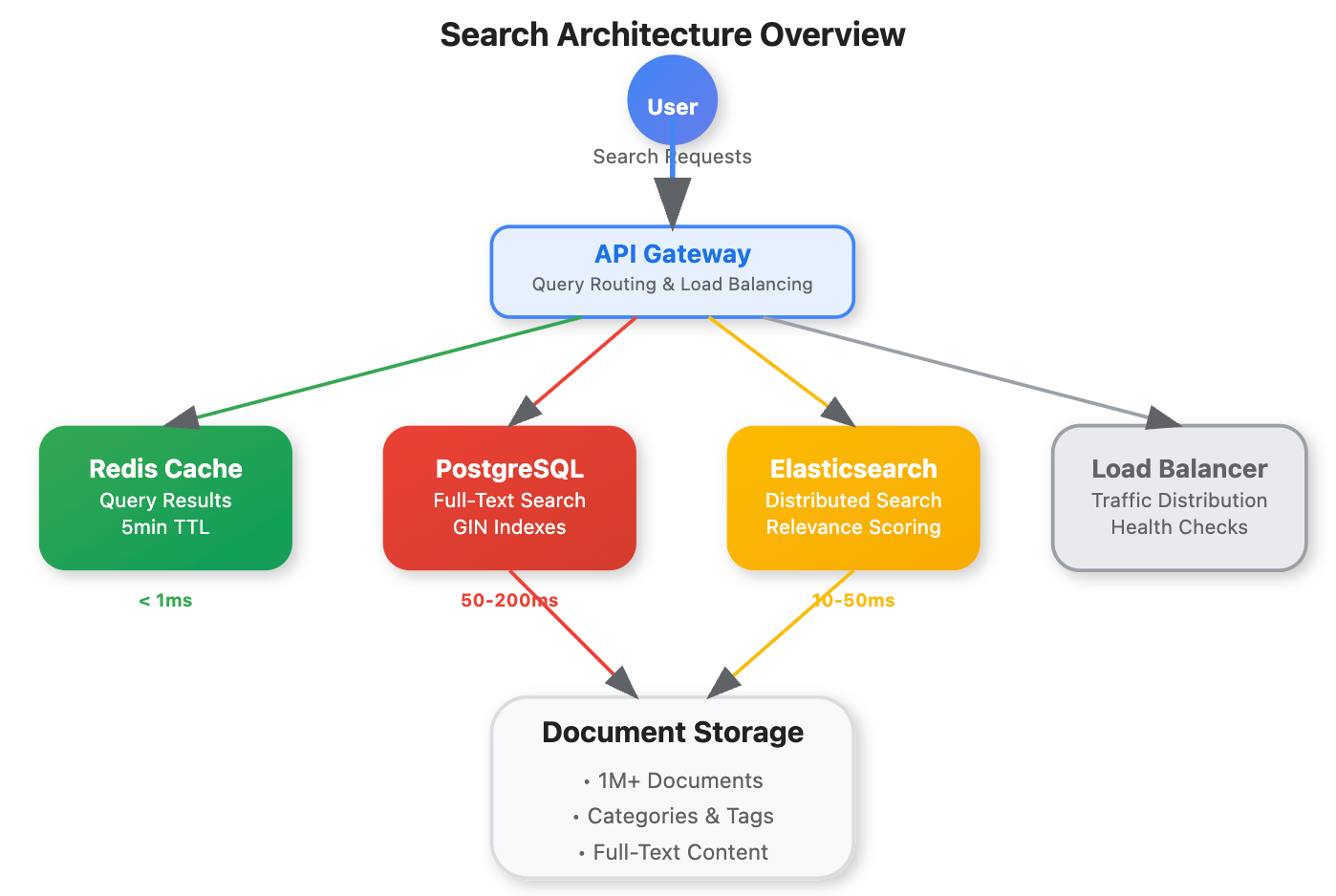
📍 Search Architecture Overview Diagram
The Hidden Layers of Search Scaling
The Indexing Paradox
