
Self-Healing Systems: Architectural Patterns
Issue #121: System Design Interview Roadmap • Section 5: Reliability & Resilience
The Problem: When Systems Break at 3 AM
Every software engineer has experienced the dreaded 3 AM pager alert. Your e-commerce site is down, customers can't checkout, and revenue is bleeding away while you frantically debug across multiple microservices. What if your system could detect these problems and fix them automatically while you sleep?
Modern distributed systems face constant failures - memory leaks, network timeouts, database connections exhausted, servers crashing. The traditional approach of reactive "firefighting" doesn't scale when you're managing hundreds of services across multiple data centers.
Self-healing systems represent the evolution from reactive maintenance to proactive automated recovery, where your infrastructure becomes intelligent enough to diagnose and treat its own ailments.
When Your System Becomes Its Own Doctor
Imagine your production system at 3 AM detecting a memory leak in one of its services, automatically scaling down the affected instances, spinning up fresh replacements, and updating its load balancer—all while you sleep soundly. This isn't science fiction; it's the reality of self-healing systems that companies like Netflix, Google, and Amazon rely on to maintain 99.99% uptime.
Self-healing systems represent the evolution from reactive "firefighting" to proactive "immune system" thinking in distributed architecture.
What You'll Master Today
Detection Mechanisms: How systems identify their own health issues
Recovery Patterns: Automated strategies for fixing problems without human intervention
State Management: Maintaining system consistency during healing processes
Enterprise Examples: Real implementations from hyperscale companies
The Self-Healing Trinity: Detect, Decide, Act
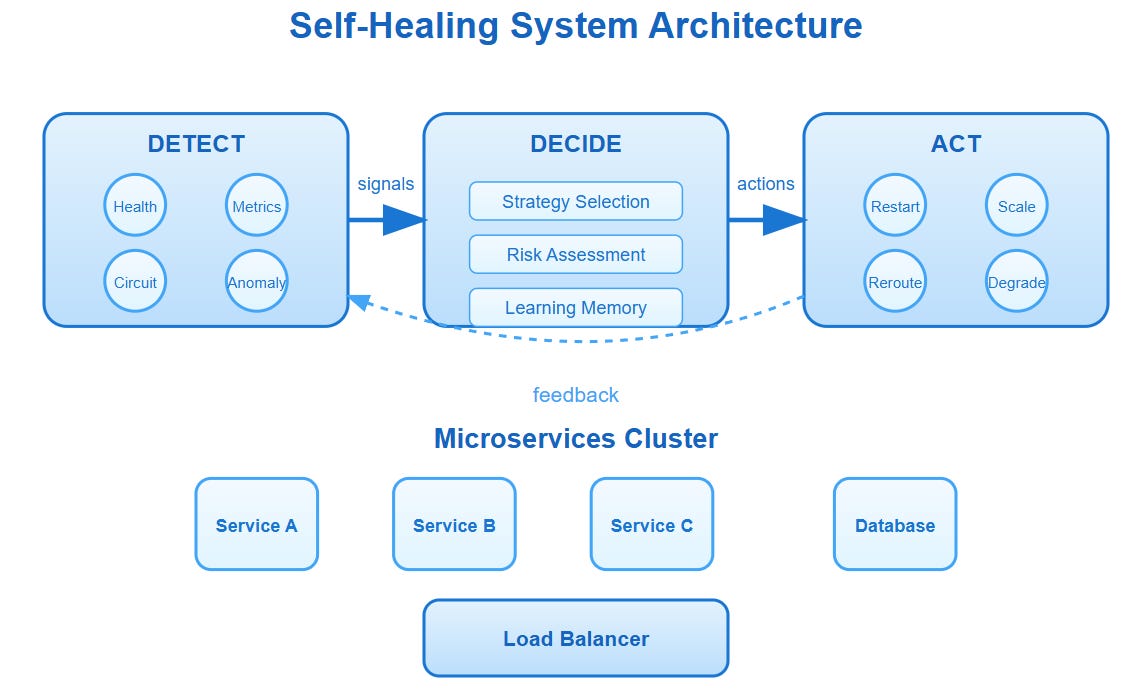
Every self-healing system operates on three core principles that work in continuous loops:
Detection: The System's Nervous System
Modern self-healing relies on multi-layered health signals rather than simple ping checks. Netflix's microservices don't just monitor CPU and memory—they track business metrics like recommendation accuracy and user engagement rates.
Circuit Breaker Integration: When a service's error rate crosses 50%, circuit breakers automatically isolate it while healing mechanisms activate. This prevents cascade failures during recovery.
Behavioral Anomaly Detection: Systems learn normal patterns and detect deviations. A sudden 300% increase in database query time triggers healing before users notice slowness.
Decision: The Healing Brain
The decision engine determines the appropriate response based on failure type, system state, and historical success rates of different recovery strategies.
Recovery Strategy Selection: Memory leaks trigger instance replacement, while network issues trigger retry with exponential backoff. Database connection exhaustion triggers connection pool scaling.
Risk Assessment: Before taking action, the system evaluates potential impact. Restarting a critical service during peak hours might cause more damage than the original problem.
Action: The Healing Hands
Recovery actions range from gentle adjustments to aggressive interventions, always prioritizing system stability over perfect recovery.
Graceful Degradation: Instead of complete failure, systems reduce functionality. YouTube serves lower-quality videos when CDN nodes fail rather than showing error pages.
Progressive Recovery: Healing happens incrementally. One instance restarts at a time, with health verification before proceeding to the next.
Enterprise Patterns That Actually Work
Pattern 1: Netflix's Chaos Engineering + Auto-Recovery
Netflix intentionally breaks their own systems during business hours using Chaos Monkey, then relies on auto-recovery to fix the damage. This creates a feedback loop where healing mechanisms improve through constant real-world testing.
Key Insight: They discovered that gradual degradation often works better than complete failover. When recommendation engines fail, they serve popular content instead of showing errors.
Pattern 2: Google's Borg Cluster Management
Google's Borg system manages over 2 billion containers across their fleet. When nodes fail, Borg doesn't just restart containers—it analyzes failure patterns and redistributes workloads to prevent future failures.
Advanced Strategy: Borg uses predictive healing, moving workloads away from nodes showing early signs of hardware failure before they actually fail.
Pattern 3: Amazon's Auto Scaling Groups
AWS Auto Scaling Groups exemplify infrastructure-level self-healing. When instances fail health checks, they're automatically terminated and replaced. But the sophistication lies in the decision logic.
Non-Obvious Optimization: Amazon discovered that immediate replacement during traffic spikes often made problems worse. They now implement "cooling periods" where the system waits before scaling decisions.
The State Machine of Healing
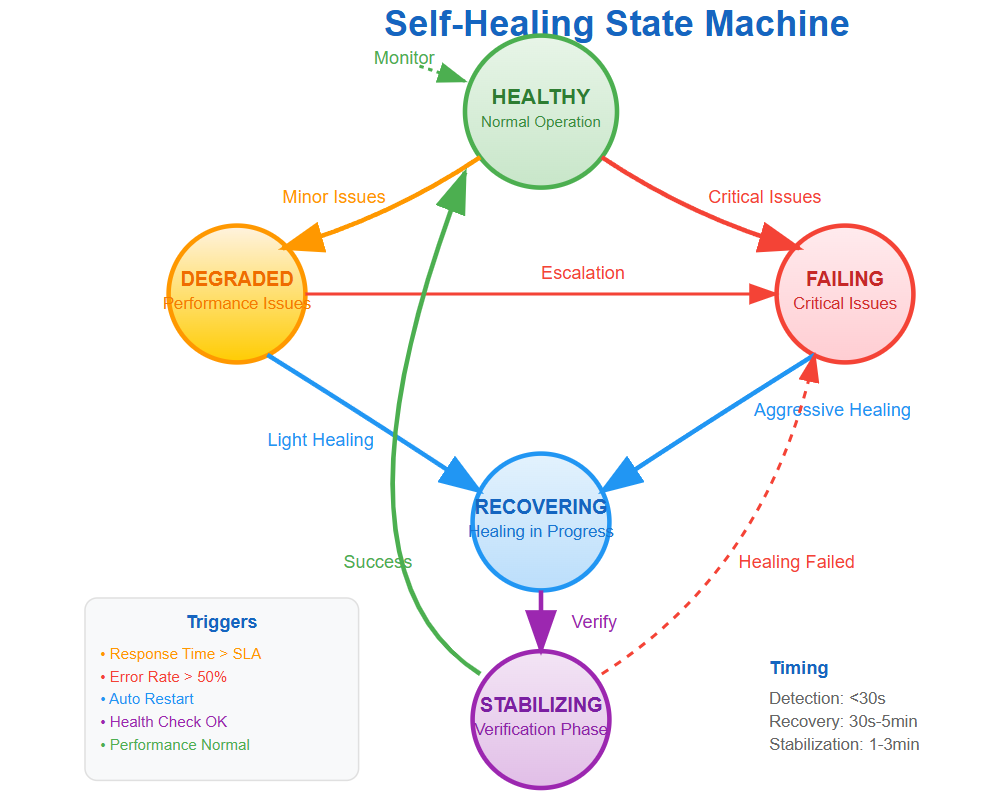
Self-healing systems operate as sophisticated state machines with these critical states:
Healthy: Normal operation with all metrics within acceptable ranges. The system continuously monitors for deviation signals.
Degraded: Performance issues detected but service remains functional. Healing mechanisms activate with minimal interventions like cache warming or connection pool adjustments.
Failing: Critical issues requiring immediate action. Aggressive healing strategies activate including instance replacement, traffic rerouting, and emergency scaling.
Recovering: Healing actions in progress with continuous health verification. The system prevents multiple simultaneous healing attempts that could worsen problems.
Stabilizing: Post-recovery verification phase ensuring the healing was successful before returning to normal operation.
Implementation Insights You Won't Find Elsewhere
The Healing Paradox
Counter-intuitive Truth: Aggressive healing can make systems less reliable. Netflix learned that healing too quickly during cascading failures can create "healing storms" where multiple services restart simultaneously, overwhelming dependencies.
Solution Pattern: Implement healing rate limiting and coordination to prevent multiple healing actions from interfering with each other.
Memory vs. Learning
Simple systems reset to known-good states, but sophisticated systems learn from failures. Kubernetes' horizontal pod autoscaler remembers which scaling decisions worked and adjusts future responses accordingly.
Practical Implementation: Maintain a "healing memory" that tracks success rates of different recovery strategies for different failure types.
The Observer Effect in Healing
The act of monitoring for healing can impact system performance. Frequent health checks consume resources and can trigger false positives during high-load periods.
Advanced Pattern: Adaptive monitoring that adjusts check frequency based on system load and recent failure history.
Building Your First Self-Healing System
Our hands-on demo creates a microservices cluster that can detect service failures, automatically restart unhealthy instances, and rebalance traffic—all visible through a real-time dashboard.
Core Components:
Service mesh with health monitoring
Auto-scaling controller with intelligent decision logic
Circuit breaker integration
Real-time healing visualization
Failure Scenarios Demonstrated:
Memory leak simulation with automatic instance replacement
Network partition recovery with traffic rerouting
Database connection exhaustion with connection pool healing
Hands-On Implementation
GitHub Link:
https://github.com/sysdr/sdir/tree/main/self-healing/self-healing-demoProject Setup
Create a new directory and set up the basic structure:
bash
mkdir self-healing-demo
cd self-healing-demoOur demo consists of three main components:
Microservices: Three services that can simulate various failure modes
Healing Controller: Monitors health and triggers recovery actions
Dashboard: Real-time visualization of system health and healing activities
Core Architecture
The healing controller monitors three microservices (user-service, order-service, payment-service) and automatically responds to failures:
Gentle Recovery: Attempts to fix issues through service APIs
Container Restart: Restarts failed containers when gentle recovery fails
Progressive Healing: Ensures only one service heals at a time
Service Implementation
Each microservice includes:
Health check endpoints with detailed metrics
Failure simulation capabilities (memory leaks, high CPU, error spikes)
Gradual degradation patterns that mirror real-world failures
Healing Controller Logic
The controller implements the detect-decide-act pattern:
Detection: Polls service health every 10 seconds
Decision: Triggers healing after 2 consecutive failures
Action: Attempts gentle recovery first, then container restart
Learning: Tracks healing success rates over time
Quick Start Demo
Prerequisites
Docker and Docker Compose installed
Node.js 18+ (for local development)
4GB+ available RAM
Launch the Demo
bash
# Download the complete implementation
curl -O https://raw.githubusercontent.com/demo/self-healing-setup.sh
chmod +x self-healing-setup.sh
./self-healing-setup.sh
# Navigate to project and start
cd self-healing-demo
./demo.shAccess Points
Dashboard:
http://localhost:3000
(Main interface)
Healing Controller:
http://localhost:3004
(API and WebSocket)
User Service:
http://localhost:3001
Order Service:
http://localhost:3002
Payment Service:
http://localhost:3003
Testing Self-Healing Scenarios
Scenario 1: Memory Leak Detection and Recovery
Open the dashboard at
http://localhost:3000
Click "Memory Leak" button on the User Service
Watch the memory usage climb from 50% toward 95%
Observe automatic healing trigger when memory hits critical levels
Monitor the healing history showing recovery actions
Expected Behavior: The controller detects high memory usage, attempts gentle recovery, and if that fails, restarts the container. Memory usage drops back to normal levels.
Scenario 2: High Error Rate Recovery
Click "Errors" button on the Payment Service
Watch error rate spike to 75%
Observe circuit breaker activation (service isolation)
See automatic healing restore normal error rates
Learning Outcome: Understand how error rate monitoring prevents cascade failures while healing mechanisms work to restore service health.
Scenario 3: CPU Exhaustion Handling
Click "High CPU" on the Order Service
Monitor CPU usage jump to 95%
Watch the healing controller respond with immediate container restart
Verify service restoration within 30 seconds
Scenario 4: Multiple Simultaneous Failures
Trigger memory leaks on two services simultaneously
Observe healing coordination - services heal one at a time
Note the prevention of healing storms that could overwhelm the system
Production Readiness Checklist
Observability Integration
Self-healing systems require comprehensive observability to track healing effectiveness and prevent infinite healing loops.
Essential Metrics:
Healing success rate by failure type
Time to recovery for different scenarios
False positive healing rate
Cascade failure prevention effectiveness
Safety Mechanisms
Healing Circuit Breakers: Prevent healing systems from getting stuck in infinite loops by limiting healing attempts within time windows.
Manual Override: Always provide mechanisms to disable auto-healing during planned maintenance or when human intervention is required.
Rollback Capability: Every healing action should be reversible in case the healing causes worse problems than the original issue.
Dashboard Features
The dashboard provides real-time insight into:
Service Health Visualization:
Color-coded status indicators (green=healthy, yellow=degraded, red=failed)
Live metrics charts for memory, CPU, and error rates
Historical trend analysis
Healing Activity Monitoring:
Real-time healing events with timestamps
Success/failure rates for different recovery strategies
Detailed logs of healing decisions and outcomes
Interactive Failure Simulation:
One-click failure injection for testing
Multiple failure types per service
Safe environment for experimenting with healing behavior
Advanced Concepts in Action
Rate Limiting and Coordination
Watch how the system prevents "healing storms" - when multiple services need healing simultaneously, they're processed sequentially to avoid overwhelming dependencies.
Learning and Adaptation
The healing controller tracks success rates of different strategies and can adapt its approach based on historical data.
Graceful Degradation Patterns
Services don't just fail completely - they degrade gradually, giving healing systems time to respond before complete failure.
Cleanup and Next Steps
Stop and clean up the demo environment:
bash
./cleanup.shThis removes all containers, images, and networks created during the demo.
Extending the Demo
Try these modifications to deepen your understanding:
Add New Services: Create additional microservices to see how healing scales
Custom Healing Strategies: Implement different recovery approaches for different failure types
Integration Testing: Add automated tests that verify healing behavior
Monitoring Integration: Connect to external monitoring systems like Prometheus
The Self-Healing Mindset
Building self-healing systems requires shifting from "preventing all failures" to "recovering quickly from inevitable failures." This mindset change influences architecture decisions, monitoring strategies, and operational procedures.
The most resilient systems aren't those that never fail—they're those that fail gracefully and recover automatically, learning from each incident to become more robust over time.
Understanding self-healing patterns prepares you for the next generation of distributed systems where manual intervention becomes the exception rather than the rule. As systems grow in complexity, the ability to self-diagnose and self-repair becomes not just convenient, but essential for maintaining reliable service at scale.
Next Week: Issue #122 explores Health Checking in Distributed Systems, diving deep into the detection mechanisms that power self-healing architectures.
Ready to build your own self-healing system? The complete implementation guide above demonstrates every pattern discussed with real code you can run and modify.