
State Management in Stream Processing: How Apache Flink and Kafka Streams Handle State
Learn System Design & Practical AI Systems using Hands on coding Courses with your choice of coding language and domain → Here
- Lifetime Access plan Available
The $50 Million State Problem
Your real-time fraud detection system processes 200,000 transactions per second. Each transaction requires checking against the customer’s last 100 purchases, current spending velocity, and location patterns. That’s 3.2 GB of state per second. A single pod crashes. Do you lose everything and start cold, triggering false positives? Or do you recover instantly with zero data loss? The difference costs $50 million annually in fraud that slips through during cold starts.
Stream processing systems must answer: where does state live, how does it survive failures, and how fast can you recover it?
State: The Hidden Backbone of Stream Processing
State in stream processing is any data that persists across multiple events. When you calculate a running average, track user sessions, or aggregate metrics over time windows, you’re managing state. Unlike stateless REST APIs that handle each request independently, stream processors accumulate context.
Apache Flink treats state as a first-class citizen with dedicated state backends. Every operator can maintain local state stored in RocksDB (disk-based) or heap memory. Flink snapshots this state periodically through distributed checkpoints—consistent snapshots of all operator state across the entire job graph. When a checkpoint completes, Flink stores it in durable storage (S3, HDFS, or distributed filesystems). If any task fails, Flink restarts from the last successful checkpoint, replaying events from that point.
The checkpoint coordinator sends barriers through the data stream. When an operator receives a barrier, it snapshots its current state before processing subsequent events. Barriers flow through the entire topology, creating a globally consistent snapshot without stopping processing. This is Chandy-Lamport algorithm applied to distributed stream processing.
Kafka Streams takes a different approach: state is materialized changelog topics in Kafka itself. Each stateful operation automatically creates a compacted changelog topic. State stores (RocksDB or in-memory) hold current state locally, while the changelog captures every state mutation as a Kafka message. When a Streams instance crashes, a new instance reads the changelog topic from the beginning, rebuilding state before resuming processing.
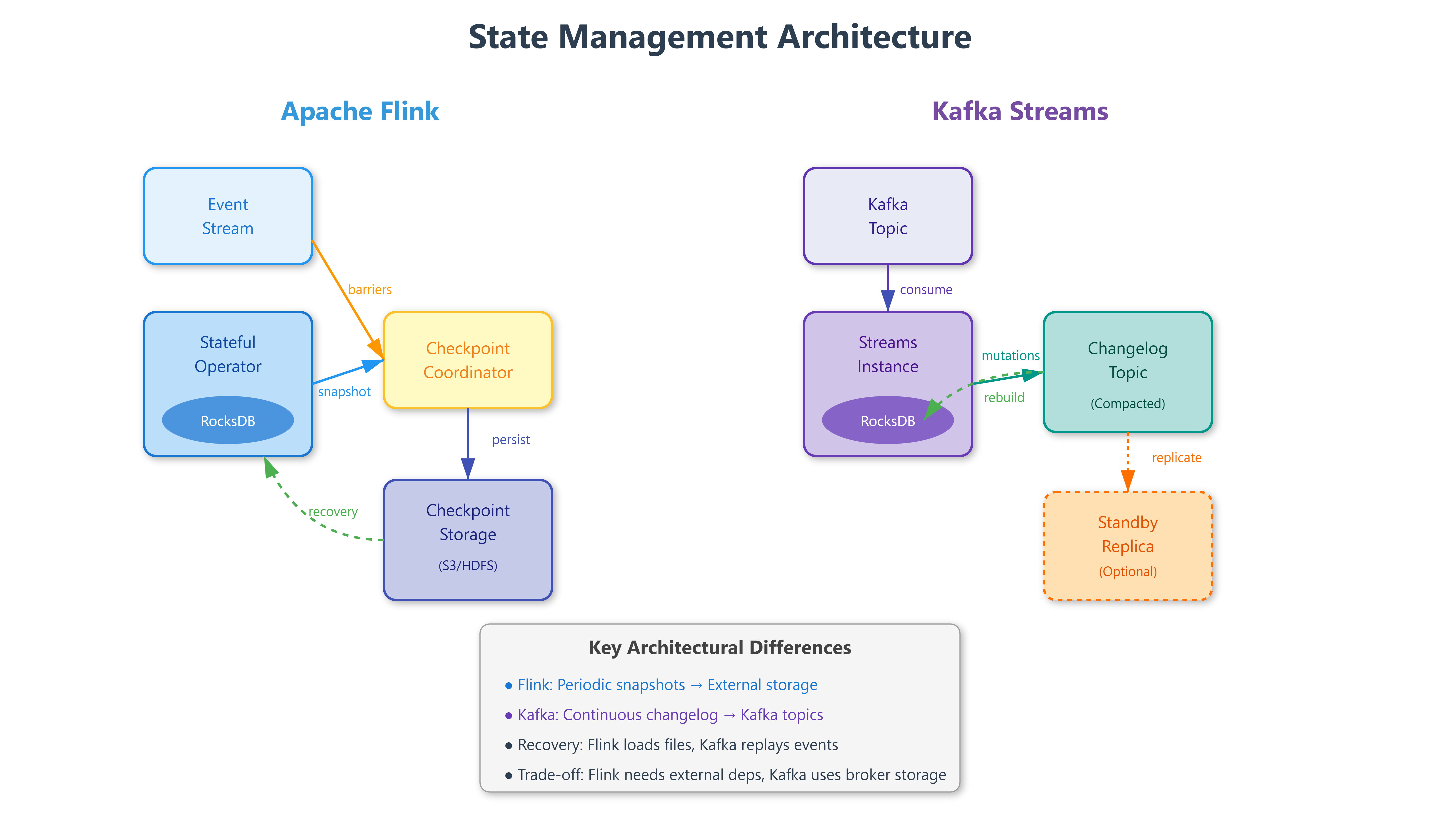
The architectural divergence is fundamental. Flink separates state storage (checkpoints in object storage) from event logs (Kafka topics), requiring external coordination. Kafka Streams unifies them—state changes ARE events in Kafka, eliminating external dependencies. This means Kafka Streams recovery reads from Kafka at partition-level granularity, while Flink recovery loads checkpoint files from S3.
State size dictates backend choice. Flink’s RocksDB backend handles terabytes of state per operator because it stores data off-heap on disk with configurable block caches. Flink’s heap state backend keeps everything in JVM memory—faster but limited by heap size. Kafka Streams uses RocksDB identically but rebuilds state from Kafka topics, making recovery time proportional to changelog size, not checkpoint interval.
