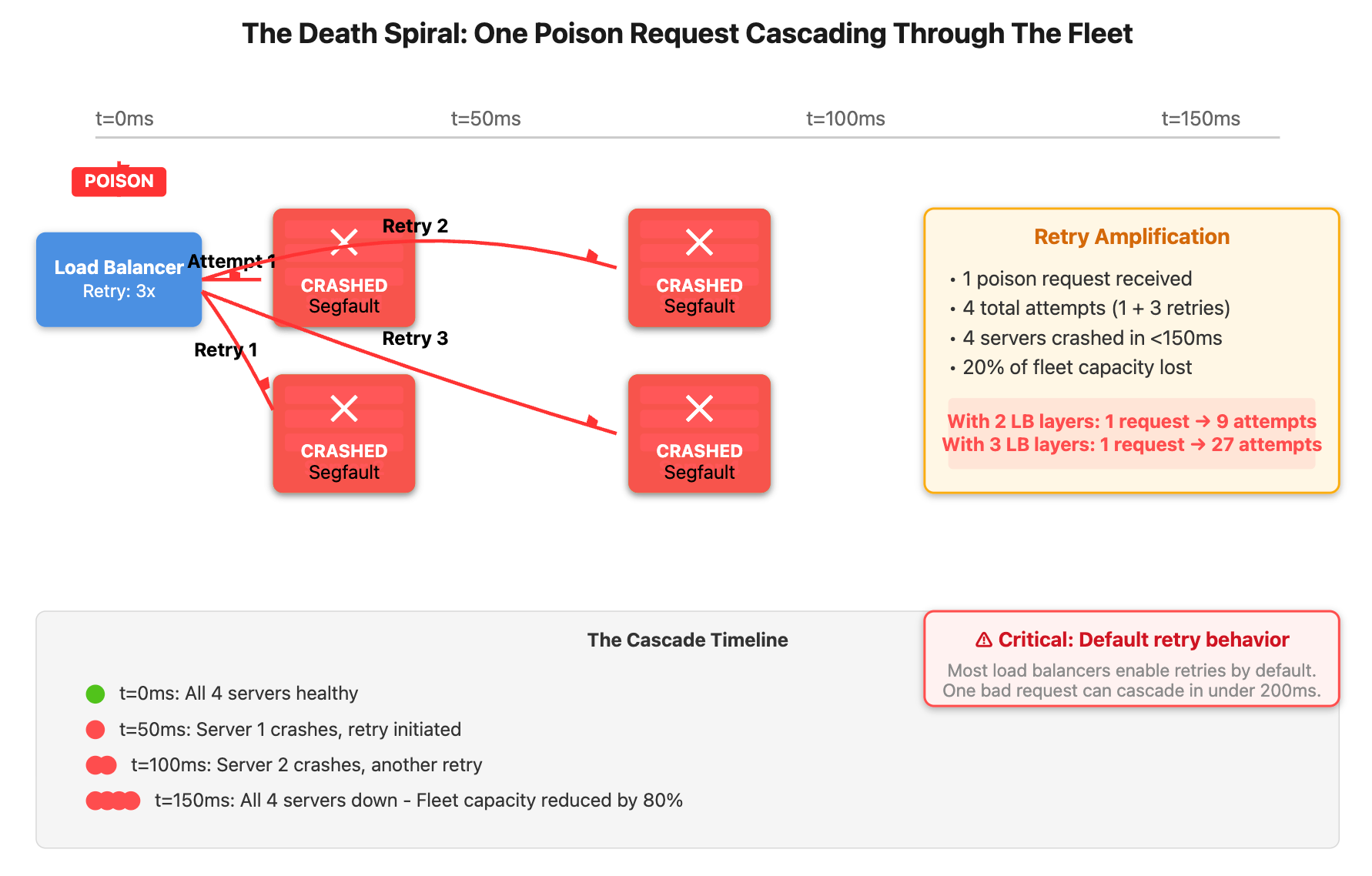
All servers in production just went down within 90 seconds. One malformed request from a user triggered a segfault in your application code. Your load balancer marked that server unhealthy and retried the same request on the next server. Then the next. Then the next.
You just watched a single HTTP request execute your entire fleet.
System Design Interview Roadmap is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
[The Death Spiral Cascade]
The Math Nobody Talks About
Most load balancers retry failed requests three times by default. AWS ALB does this. HAProxy does this. Nginx does this. That means one poison request becomes four total attempts before giving up. But here’s what kills you: each retry happens on a different server.
Server 1 crashes in 50ms. The load balancer retries on Server 2, which crashes in 50ms. Now Server 3. The cascade takes less than a second to propagate through a cluster of 20 servers. During a production incident at a major e-commerce platform in 2024, we watched 200 servers die in 11 seconds from a single malformed JSON payload containing deeply nested arrays.
The amplification gets worse with multiple load balancer layers. Edge proxy retries three times, sending requests to your internal load balancer. That load balancer retries three times to your application servers. One request becomes nine attempts. Add another layer and you hit 27 attempts per poison request.
What Actually Causes This in Production
Segfaults are the obvious case, but the insidious ones are different. Regex catastrophic backtracking will tie up a thread for 30+ seconds without triggering any timeout. We’ve seen specific UTF-8 byte sequences crash string processing libraries that have been in production for years. GraphQL queries with circular references can wedge your parser indefinitely.
The worst incident I dealt with involved a legacy XML parser that would allocate unbounded memory when processing entity expansion attacks. One request consumed 16GB of RAM before the OOM killer stepped in. By then, the damage was done across the fleet.
These patterns don’t show up in staging because you need production-scale traffic diversity to hit them. That one user with the weird emoji sequence in their profile name. The automated script sending malformed headers. The ancient mobile app version still in use by 0.01% of users.
Why Circuit Breakers Aren’t Enough
Everyone reaches for circuit breakers first. They help, but they react after the damage starts. A circuit breaker trips after N failures, which means N servers must crash before it opens. By the time your circuit breaker trips, you’ve already lost 20-30% of your fleet capacity.
Circuit breakers also don’t stop the initial retry attempts. The load balancer’s retry logic executes faster than most circuit breaker implementations can react. You need to prevent the poison request from reaching your application code in the first place.
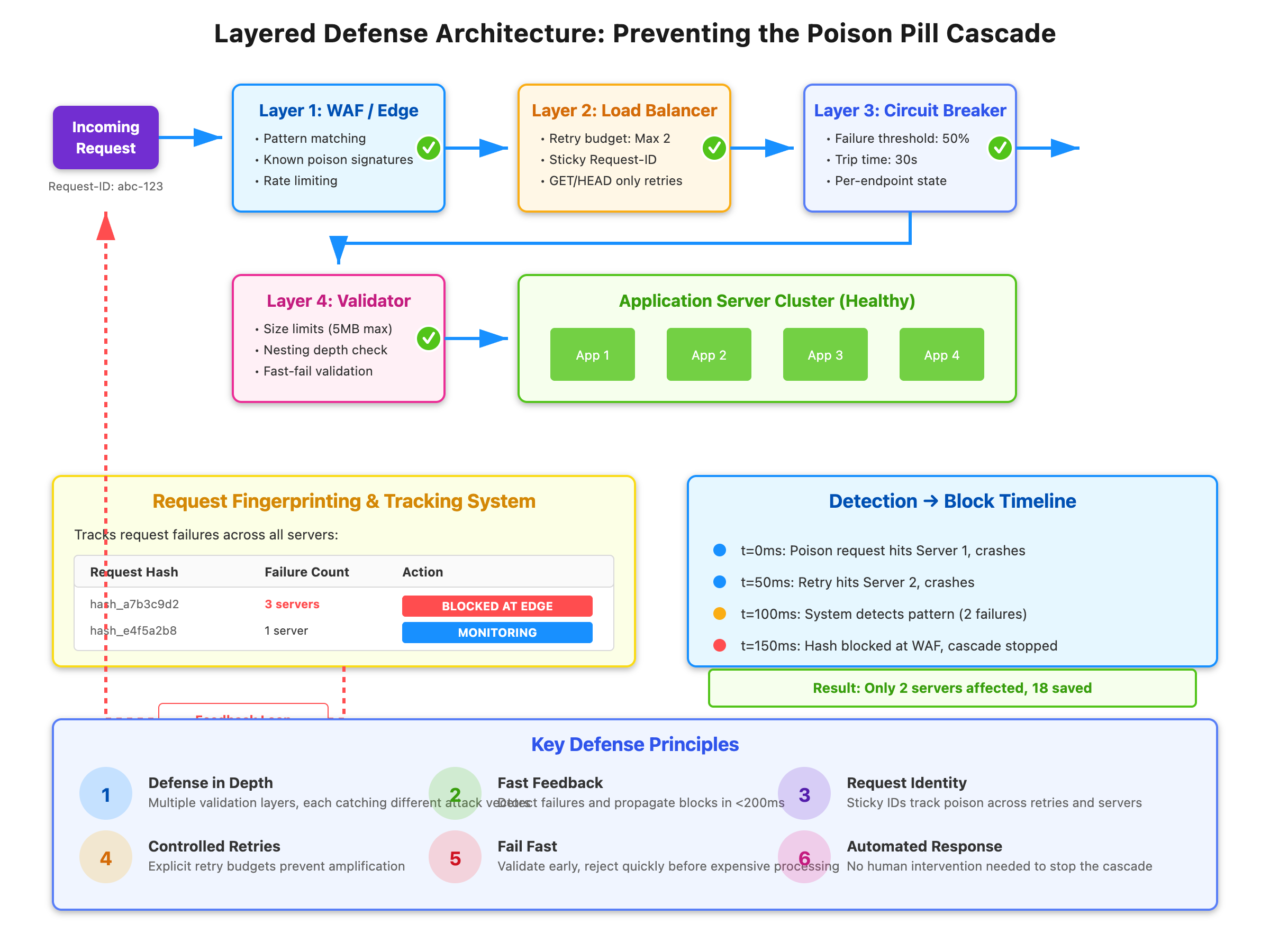
[ Layered Defense Architecture]
The Production-Grade Solution
Layer your defenses starting at the edge. Deploy request validation before traffic reaches your load balancer. Use WAF rules to block patterns that match known poison payloads. This requires a feedback mechanism from your application back to the edge.
Implement request fingerprinting with sticky IDs that persist across retries. Hash the request payload and track which fingerprints are causing failures across your fleet. When a fingerprint fails on three different servers, block it at the edge automatically. This pattern stopped a cascading failure at a major payment processor in under 400ms once the system detected the pattern.
Configure explicit retry budgets at each layer. Allow a maximum of 2 retries per request ID, not per attempt. Use exponential backoff with jitter between retries. Most importantly, disable automatic retries for non-idempotent operations completely. POST, PUT, and DELETE requests should never auto-retry without explicit idempotency keys.
Add pre-request validation that fails fast. Validate JSON structure before parsing. Set hard limits on request size, nesting depth, and processing time at the framework level. A 100ms validation step is cheaper than a 30-second CPU burn or a crashed process.
What You Can Implement This Week
Start with request logging that includes unique request IDs. Aggregate your logs and track which request IDs are appearing in crash reports across multiple servers. This visibility alone will save you during the next incident.
Add health check endpoints that verify critical path functionality, not just “is the process running.” Include checks for database connectivity, downstream service health, and available thread pool capacity. A server that’s technically alive but wedged on poison requests should fail health checks.
Configure your load balancer with explicit retry policies. Set maximum retry attempts to 2, enable retry only for GET and HEAD methods, and use a 503 response code to signal non-retriable failures. Modern load balancers like Envoy support sophisticated retry policies including retry budgets and precedence-based routing.
Build a kill switch. Deploy a feature flag system that can instantly disable problematic endpoints or request patterns without requiring a deployment. We’ve used this to stop ongoing cascades in under 60 seconds by disabling a specific API route while we patched the underlying issue.
The Reality Check
You’ll discover this vulnerability in production, not in testing. Your staging environment doesn’t have the traffic diversity or edge cases that trigger poison pills. Build the detection and response mechanisms before you need them. The difference between a 30-second outage and a 30-minute outage is having these systems in place when the 3 AM call comes.
The poison pill isn’t a theoretical problem. It’s happening in production systems right now, and the only question is whether you have the defenses deployed before it hits your fleet.
System Design Interview Roadmap is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.