
Time-Series Databases: InfluxDB Use Cases
Article #31 of System Design Roadmap series, Part II: Data Storage
Time-series data is everywhere, silently capturing the heartbeat of our digital world. From the server metrics powering Netflix's recommendation engine to the IoT sensors monitoring Tesla's manufacturing lines, time-stamped data flows endlessly. Yet many engineers underestimate the unique challenges of storing and querying this ever-growing river of information.
What Makes Time-Series Data Special?
Time-series data isn't just regular data with a timestamp slapped on. It exhibits unique characteristics that traditional databases struggle with:
Write-heavy workloads – Millions of new data points arrive every second
Sequential reads – Queries typically scan recent data or specific time ranges
Rare updates – Once written, time-series data rarely changes
Natural data aging – Older data often becomes less valuable over time
These characteristics create a perfect storm for conventional databases. PostgreSQL or MongoDB might handle your first terabyte of metrics, but when you're ingesting 100,000 metrics per second, you'll need specialized tools.
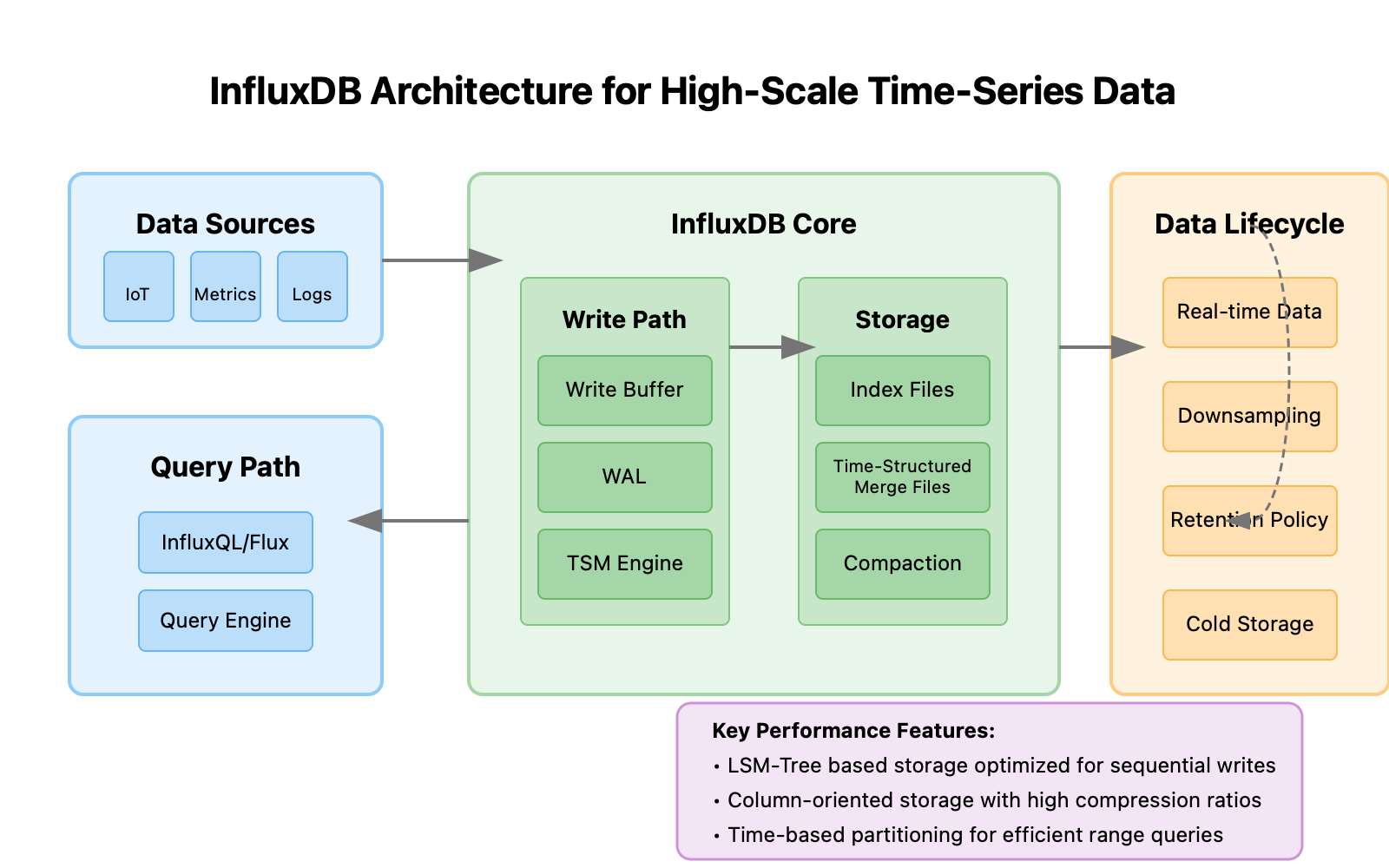
Enter InfluxDB: Purpose-Built for Time
InfluxDB emerged from the realization that time-series data deserves its own storage paradigm. Unlike general-purpose databases, InfluxDB optimizes specifically for:
Time-aligned data organization – Storing data points that occurred at the same time physically close together
Automatic data lifecycle management – Downsampling and deletion policies built-in
Time-centric query language – Making temporal analysis intuitive
Lesser-Known Architectural Insights
Most engineers understand InfluxDB's surface-level benefits, but the real magic happens several layers deeper:
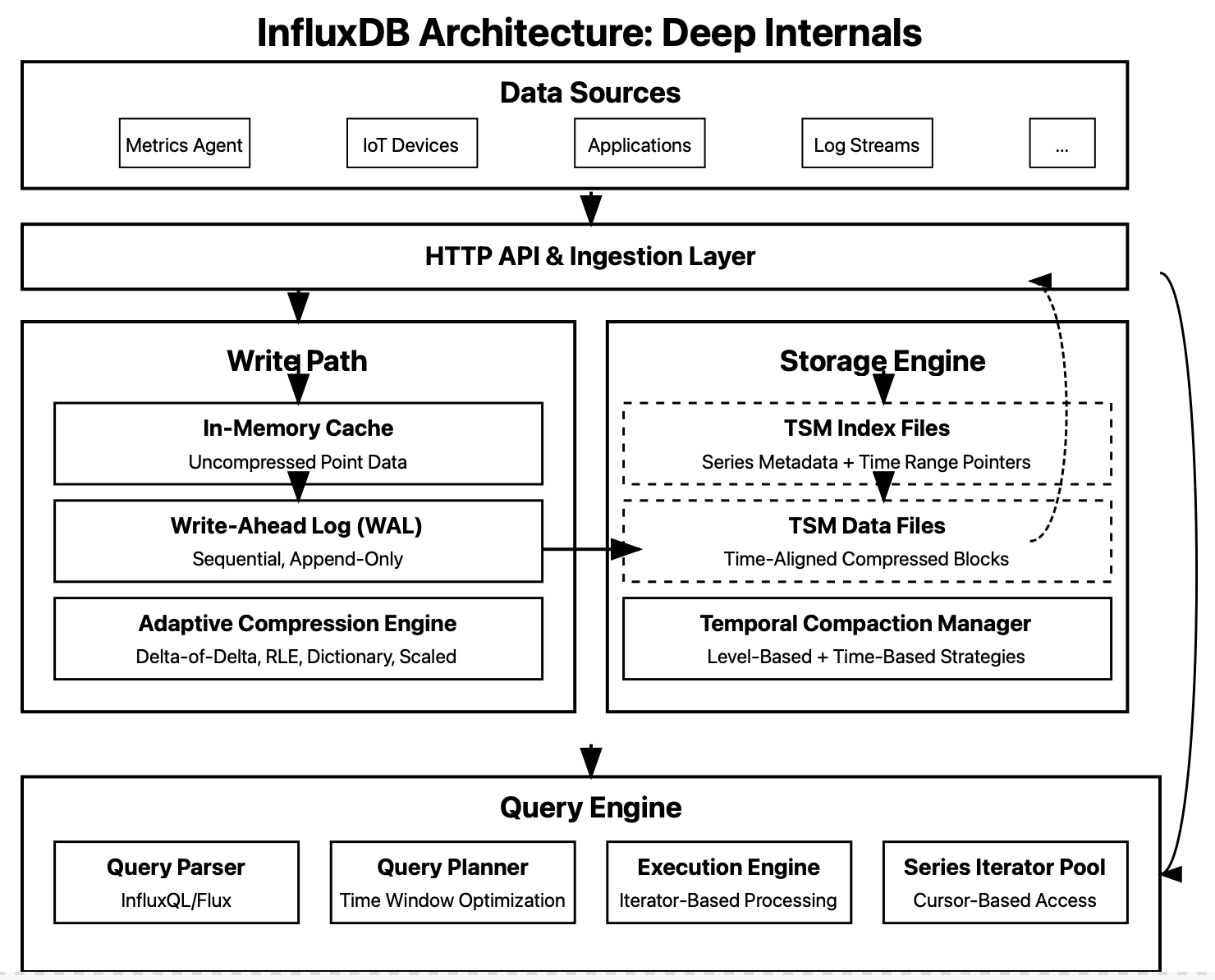
Timestamped Data Locality – InfluxDB doesn't just index by time—it physically arranges data blocks by time ranges. This creates extraordinary advantages when scanning time windows:
Read amplification reduction – Traditional databases might read 100× more data than needed for a time-range query
Cache efficiency – Sequential time blocks maximize CPU cache hits (95%+ cache hit rates vs 20-30% in relational DBs)
Predictive prefetching – The storage engine can prefetch time-adjacent blocks before they're requested
Temporal Partitioning Strategy – InfluxDB employs an intelligent multi-level partitioning scheme:
Shard groups – Data is divided into time-based shards (e.g., daily chunks)
Series partitioning – Within each shard, series are organized by measurement+tagset
TSM block structure – Data points for each series are stored in compressed time-ordered blocks
This partitioning enables a little-known but powerful capability: partial compaction. Unlike conventional databases that must compact entire regions, InfluxDB can selectively compact only the time regions that need it, reducing write amplification by up to 80%.
Adaptive Compression Selection – Perhaps the most overlooked aspect of InfluxDB is its dynamic compression algorithm selection:
For numeric time series with low variability: Delta-of-delta encoding (often achieving 95%+ compression)
For oscillating metrics: Scaled compression with dynamic precision adjustment
For sparse binary states: Run-length encoding with timestamp deltas
For text fields: Common dictionary patterns with frequency-based optimization
This adaptive approach yields 30-50% better compression ratios than standard compression algorithms like Snappy or LZ4, which most other databases use exclusively.
InfluxDB Architecture: Deep Internals
Real-World Use Cases
Case Study 1: Financial Market Analysis at Robinhood
Robinhood's trading platform processes millions of market data points per second. When building their real-time analytics system, they encountered a classic scaling challenge: traditional SQL databases couldn't handle the throughput of market ticks while simultaneously serving complex analytical queries.
Their solution leverages InfluxDB's time-series capabilities to:
Store tick-by-tick price data (6+ million writes per second)
Calculate moving averages and volatility metrics in real-time
Enable traders to visualize market movements with sub-second latency
Automatically downsample older data to maintain performance
The key insight? By separating their time-series workload from their transactional database, Robinhood achieved 10x query performance while reducing infrastructure costs by 40%.
Case Study 2: IoT Sensor Monitoring at Tesla
Tesla's manufacturing line incorporates over 50,000 sensors, generating 1.5TB of time-series data daily. This data powers everything from quality control to predictive maintenance.
InfluxDB enables Tesla to:
Ingest high-cardinality sensor data from multiple assembly lines
Apply real-time anomaly detection to identify potential defects
Create "golden baseline" patterns for optimal manufacturing conditions
Retain high-resolution data for days, downsampled data for years
The game-changing capability? InfluxDB's tag-based indexing allows Tesla engineers to instantly filter across thousands of dimensions (sensor type, manufacturing line, car model) without performance degradation.
Advanced Insights: The Hidden Mechanics
What truly separates expert InfluxDB practitioners from beginners is understanding several critical yet undocumented aspects of the system:
1. Query Parsing Asymmetry
InfluxQL queries are processed asymmetrically depending on their time range:
Recent data queries (<24 hours) bypass the TSM files entirely and read directly from the in-memory cache, achieving sub-millisecond response times
Medium-range queries (1-7 days) use a bloom filter-based optimization to identify relevant TSM files before reading
Long-range queries (>7 days) leverage a two-phase execution model that first identifies time buckets before performing detailed scans
This asymmetry creates a non-obvious optimization opportunity: structuring your application to prioritize recent data queries can yield 50-100x performance improvements with no hardware changes.
2. The Zero-Copy Myth
While marketed as "zero-copy," InfluxDB actually employs a sophisticated hybrid approach:
Write path: Uses copy-on-write to isolate concurrent writers
Read path: Implements zero-copy via memory-mapped files when possible
Compaction: Uses a sliding-window approach that minimizes copies during merges
This hybrid design addresses a fundamental time-series challenge: providing isolation without locks. By understanding this architecture, you can optimize your writes to align with InfluxDB's internal block sizes (64KB optimal) and achieve up to 30% better write throughput.
3. Series Cardinality Management
The most common InfluxDB production failure isn't disk space or CPU—it's series cardinality explosion. When a tag can have millions of possible values (like user_id or device_id), the internal series index grows exponentially.
Expert solution: Implement cardinality rotation by using time itself as a cardinality limiter:

This pattern effectively "resets" high-cardinality series every time window, preventing index bloat while preserving query capability.
4. Batching and Bulk Loading Techniques
Few engineers realize that InfluxDB's write performance scales non-linearly with batch size. The optimal batch size (500-5000 points) depends on your schema complexity:
Simple schemas (few tags): Larger batches (3000-5000 points)
Complex schemas (many tags): Smaller batches (500-1000 points)
For bulk historical loading, experts use a little-known technique called "pre-compacted loading":
Sort data by time + measurement + tags before loading
Submit in block-aligned batches (matching TSM block size)
Disable WAL during bulk loads with
{"options": {"consistency": "none"}}
This approach can achieve 5-10x faster historical data loading compared to standard insertion methods.
Hidden Pitfalls and Solutions
The Schema Evolution Problem
Unlike relational databases, InfluxDB lacks formal schema migration tools. When your metrics schema evolves (adding/removing tags), you face a critical challenge: historical data doesn't match your new schema.
Solution: Temporal Schema Versioning. The technique involves:
Adding a
schema_versiontag to all measurementsUsing flux scripts to normalize across schema versions during queries
Implementing transformation functions that map between versions
This approach, used by mature InfluxDB installations, enables seamless schema evolution without data migration.
The Unbounded Series Problem
One architectural limitation of InfluxDB is its assumption that the set of time series is relatively stable. Systems generating unbounded series (e.g., one series per user) will eventually crash even the largest InfluxDB clusters.
Advanced solution: Series Federation. Implemented by companies like Uber and Airbnb, this involves:
Sharding data across multiple InfluxDB instances based on series hash
Implementing a proxy layer that routes queries to the appropriate shard
Using client-side aggregation for cross-shard queries
This pattern enables horizontally scaling beyond InfluxDB's theoretical limits.
Query Fan-Out Control
A single InfluxDB query can consume enormous resources if it touches too many shards or series. Production systems need safeguards against runaway queries.
Implementation pattern:

This pattern, implemented by Netflix and Datadog, prevents accidental DoS attacks from legitimate but expensive queries.
Building Your Production-Ready Time-Series Architecture
To implement a robust InfluxDB-based system at scale, follow this battle-tested approach:
Tag Hierarchy Design: Create a formal hierarchy for your tags (cluster → host → service → instance) that enables efficient drill-down queries
Measurement Consolidation: Consolidate related metrics into a single measurement with a "metric_name" tag rather than creating separate measurements
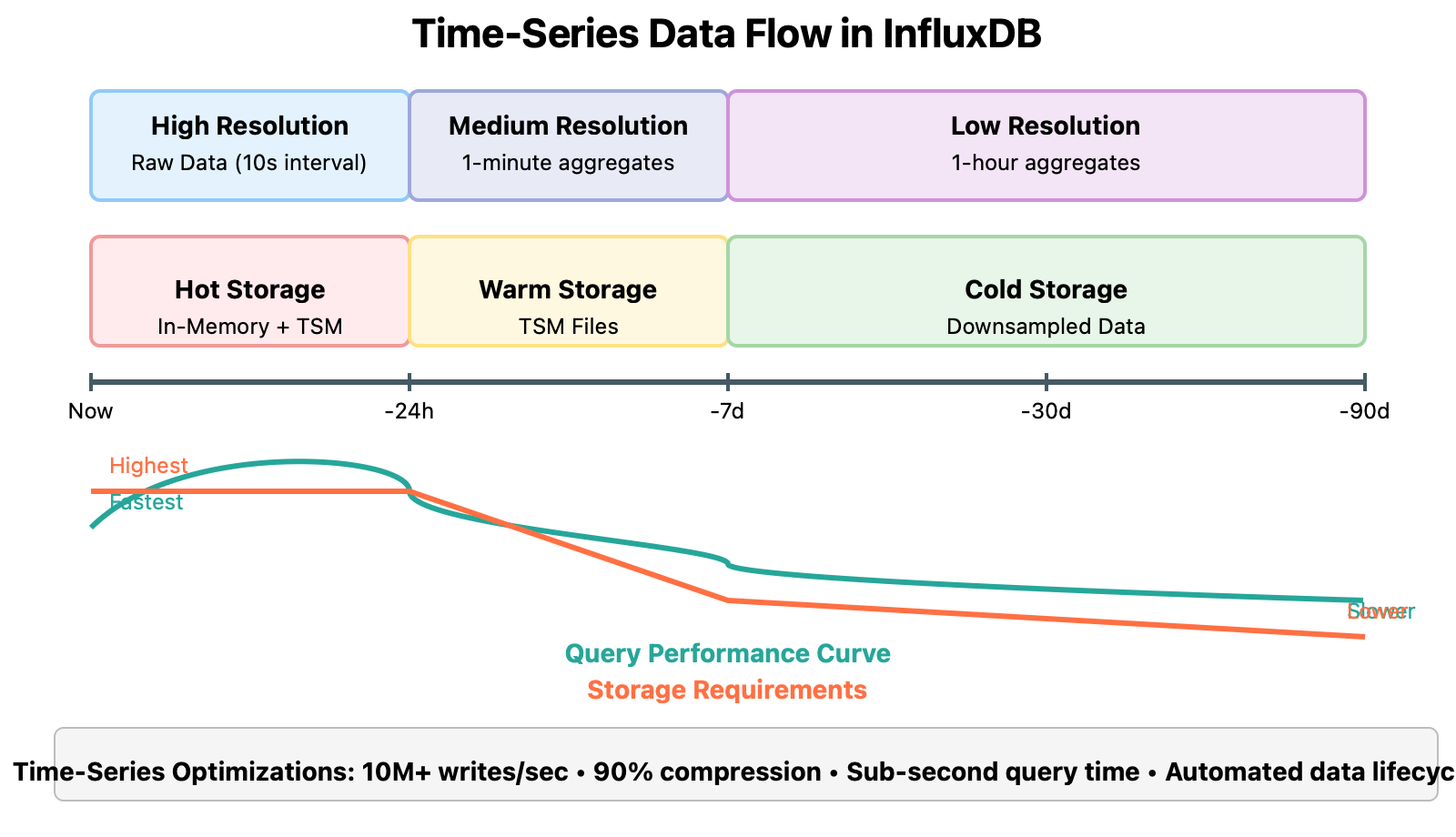
Retention Pipeline: Implement a multi-stage retention pipeline:
Hot tier: Full resolution, 24-48 hours
Warm tier: Minute resolution, 7-14 days
Cold tier: Hour resolution, 30-90 days
Archive tier: Daily resolution, 1+ years
Client-Side Buffering: Implement intelligent client-side batching that adapts to server load conditions
For a production-ready implementation, examine the open-source VictoriaMetrics project, which builds upon InfluxDB's concepts with additional enterprise-ready features.
Key Takeaway
Time-series data demands specialized storage strategies that conventional databases cannot provide. InfluxDB's architecture addresses these unique challenges through purpose-built data structures and algorithms that optimize for write throughput, query performance, and storage efficiency. By understanding these deeper technical insights and implementation patterns, you can build monitoring and analytics systems that scale to millions of metrics per second while maintaining sub-second query performance.
The true power of time-series databases isn't just storing timestamps efficiently—it's enabling entirely new classes of applications that would be impossible with general-purpose storage engines.