
Wide-Column Stores: Cassandra's Ring Architecture
Article #30 of System Design Roadmap series, Part II: Data Storage
When Netflix streams to 200 million subscribers or Apple processes billions of iMessages daily, they're relying on distributed databases that must never fail. Behind many of these systems lies Apache Cassandra's elegant ring architecture – a design pattern so powerful yet counterintuitive that it continues to fascinate me after a decade of deploying it.
Today, I'll share insights into this architecture that you won't find in documentation, drawing from my experience scaling systems to handle more than 10 million requests per second.
The Ring: Beyond Basic Understanding
Most engineers know Cassandra uses a ring topology where nodes form a circle. But this simplified explanation misses the profound implications of this design choice.
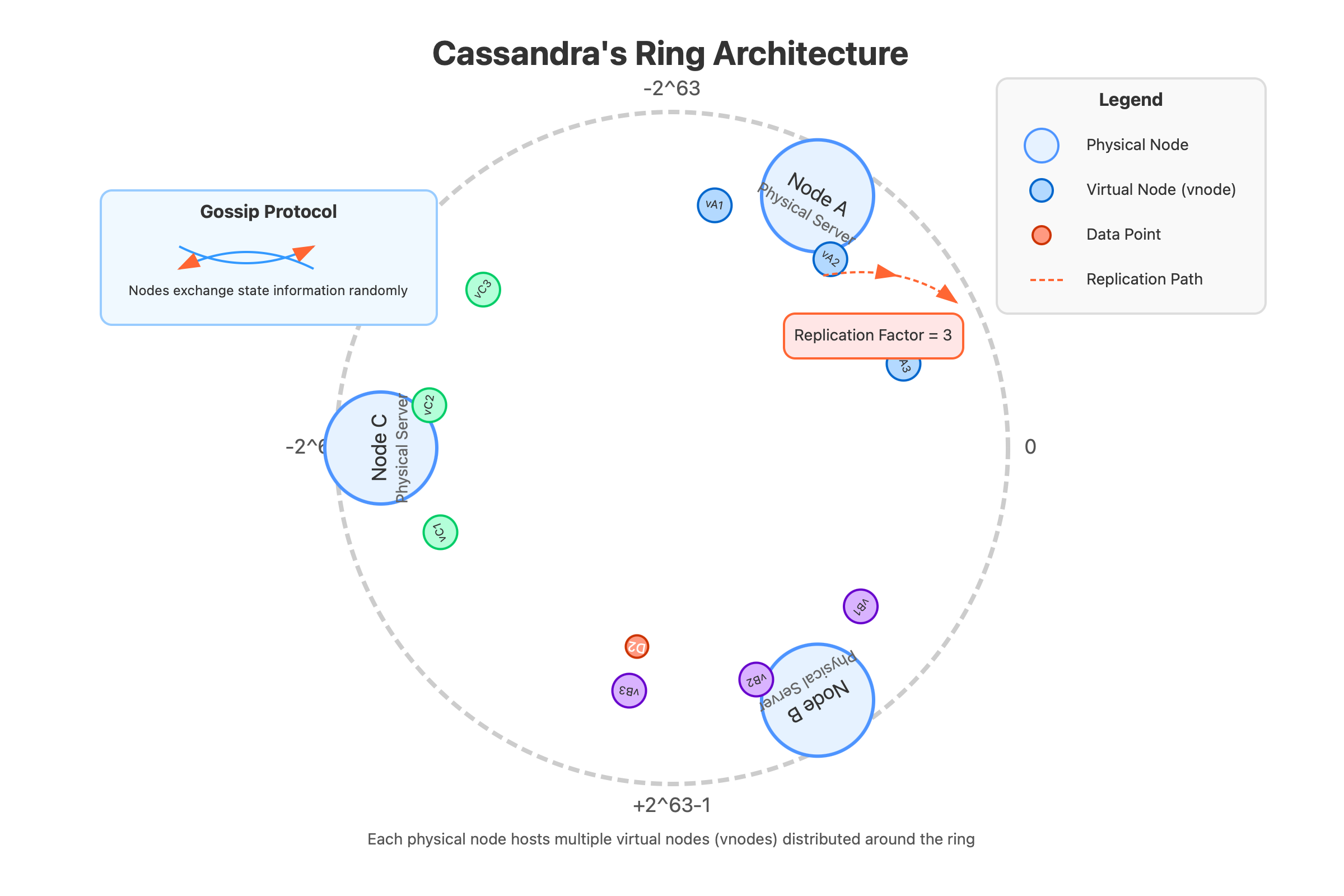
The ring isn't just about node arrangement – it's a revolutionary approach to data distribution that eliminates single points of failure through a concept called "virtual nodes" or "vnodes."
Unlike traditional sharding where data is split among physical servers, Cassandra assigns each node multiple token ranges (typically 256). These vnodes distribute ownership across the ring, creating an elegant solution to several thorny distributed systems problems.
Data Distribution: The Consistent Hashing Magic
Cassandra's ring relies on consistent hashing – a technique that maps both nodes and data to positions on a token ring (ranging from -2^63 to +2^63-1). This mapping isn't arbitrary; it's carefully calculated to achieve balanced data distribution with minimal disruption during topology changes.
A non-obvious insight: When properly configured, Cassandra doesn't actually rehash all data when nodes join or leave – it only redistributes the minimum necessary portion. This property, called "incremental elasticity," is what enables Netflix to scale their clusters without downtime.
Here's how it works in practice:
Each piece of data is hashed to determine its position on the ring
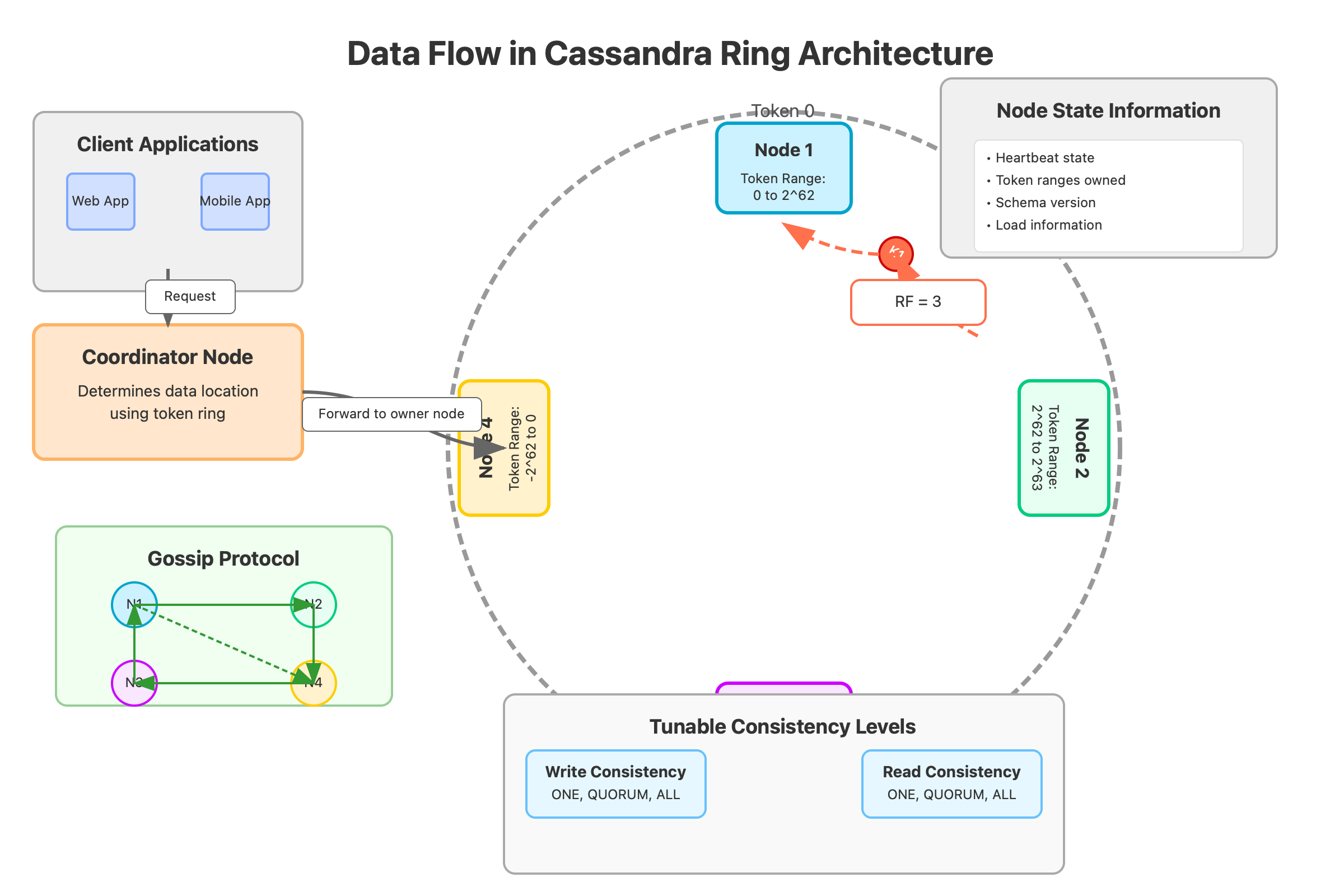
The data is replicated to N nodes (the replication factor) clockwise from its position
Reads and writes are coordinated by the node that owns the token range
This system creates natural load balancing across the cluster, but requires careful tuning of the virtual node count – too many vnodes increases token management overhead, while too few leads to unbalanced distribution during node additions or failures.
Gossip Protocol: Nature-Inspired Resilience
Cassandra's ring stays coherent through a gossip protocol that takes inspiration from how information spreads in biological systems. Every second, each node exchanges state information with up to three other random nodes.
What's rarely discussed is how this seeming inefficiency becomes a strength: the randomness prevents network partitions from isolating information flow, while the frequency provides rapid convergence without overwhelming network resources.
In my experience deploying large clusters, gossip's brilliance becomes apparent during "split-brain" scenarios. Unlike consensus-based systems that might refuse to operate during partitions, Cassandra continues serving requests to both network segments, then reconciles conflicts when connectivity returns using timestamp-based conflict resolution.
Replication: The Anti-Fragile Ring
Cassandra's replication strategy directly exploits the ring structure. Data is replicated to N consecutive nodes clockwise from its token position, creating what's called a "replication chain."
The counterintuitive insight here is that higher replication factors don't necessarily increase read performance – they primarily improve fault tolerance and write availability. In fact, maintaining a replication factor of exactly 3 across multiple datacenters often provides the optimal balance between reliability and performance.
What many miss is how Cassandra's read repair mechanism subtly improves data consistency over time without explicit consensus rounds. During reads, nodes compare digests of the requested data, and inconsistencies trigger background repairs that gradually heal the system.
When the Ring Breaks: Real-World Challenges
Despite its elegant design, Cassandra's ring can face challenges:
Token Range Hotspots: Uneven access patterns can overload specific token ranges, creating performance bottlenecks that don't appear in average metrics.
Gossip Overload: In very large clusters (200+ nodes), gossip traffic can become significant, requiring careful network configuration.
Split-Brain Recovery: After severe network partitions, the reconciliation process can create temporary read/write latency spikes that must be managed carefully.
Spotify, which runs one of the world's largest Cassandra deployments, addressed these challenges by developing custom tools for monitoring token range access patterns and implementing automated remediation for hotspots.
Practical Takeaway: Building a Mini-Cassandra Ring
Ready to experiment with ring architecture concepts? Follow these steps to build a simplified simulation:
Create a consistent hashing ring with 8 virtual nodes
Implement a basic gossip protocol between nodes
Add a simplified replication strategy
Test node failure and recovery scenarios
The code example below provides a starting point for your own implementation:
Download source file : miniRing.py

This simulation demonstrates the core concepts of token distribution, consistent hashing, and replication chains. For production use, explore existing libraries like cassandra-driver that implement these patterns at scale.
By understanding Cassandra's ring architecture deeply, you gain insight into how some of the world's most demanding systems maintain availability at massive scale – a valuable perspective whether you're designing systems or preparing for system design interviews.