
Write-Ahead Logs: How Databases Ensure Durability
Issue #25 of "System Design Roadmap" - Part II: Data Storage
Imagine you're in the middle of a critical database transaction when suddenly, your server crashes. Months of customer data hanging in the balance. What saves you from disaster? A humble, often overlooked mechanism called the Write-Ahead Log (WAL). This unsung hero of database reliability is what I wish someone had properly explained to me years ago, before I had to learn its importance through a painful production outage.
What Is a Write-Ahead Log?
At its heart, a WAL is like a meticulous journal that records your intentions before you act on them. Instead of directly modifying data pages in a database, changes are first recorded in the log. Only after these log entries are safely persisted to durable storage do we consider the transaction committed.
This simple sequencing—write the log first, then modify the data—creates a powerful safety net. If a system fails between logging and applying changes, the database can recover by replaying logged operations that weren't completed.
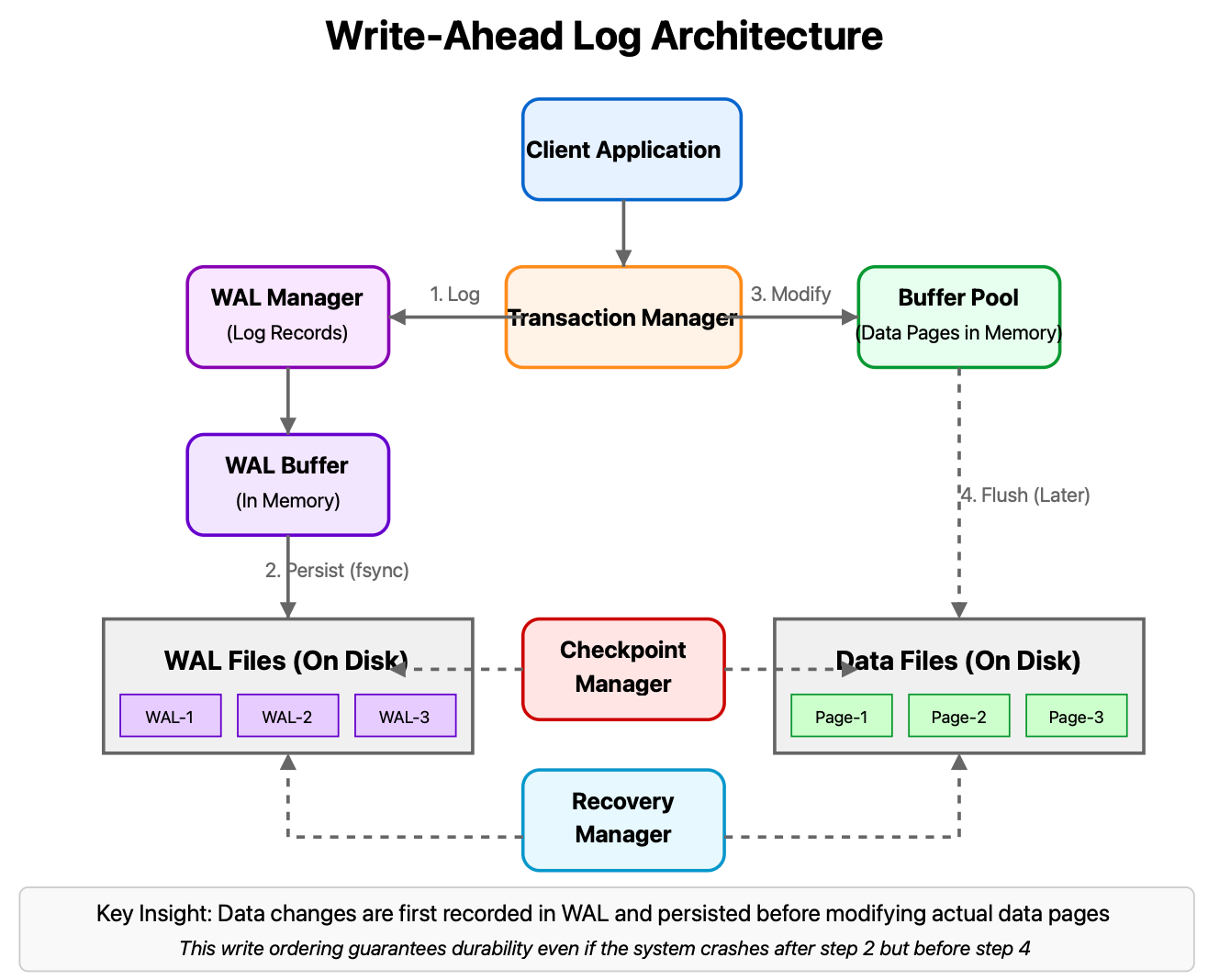
The Anatomy of Write-Ahead Logging
Let's break down how WALs actually work:
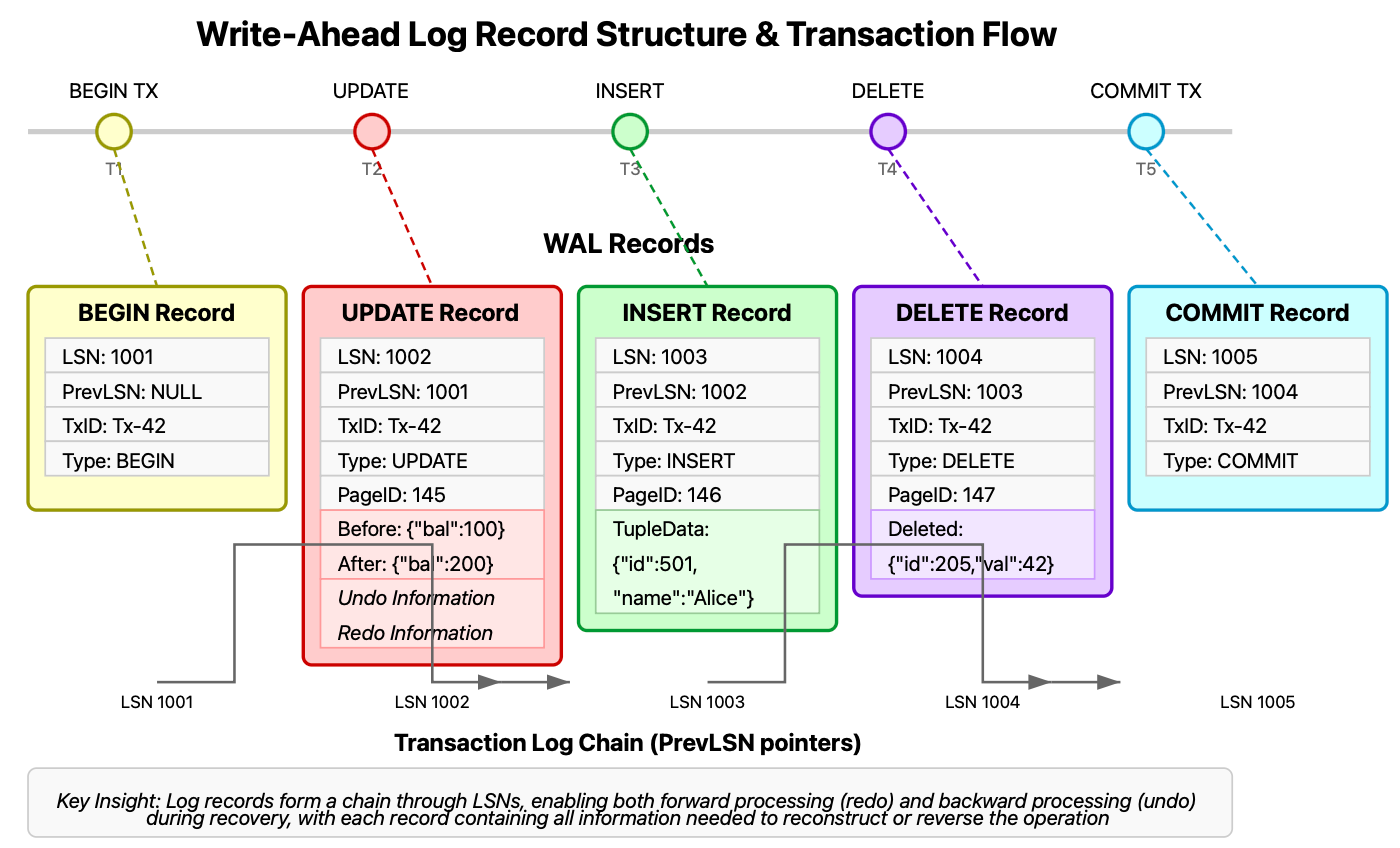
Log Record Creation: When a transaction requests a change (insert, update, delete), the database creates detailed log records containing:
Transaction ID
Page ID being modified
Type of operation
Before and after values (redo/undo information)
Log Sequence Number (LSN)
Force-Write to Disk: These records are appended to the log file and flushed to persistent storage before the transaction commits.
Data Modification: Only after the log is safely on disk can the actual data pages be modified (often happening later, asynchronously).
Recovery Process: If a crash occurs, the database uses the WAL to:
Redo completed transactions not yet reflected in data files
Undo incomplete transactions that were interrupted
What makes this approach so powerful is its sequential, append-only nature. Sequential disk writes are vastly more efficient than random access, giving WALs performance advantages alongside their durability guarantees.
Real-World WAL Implementations
PostgreSQL's WAL
PostgreSQL's implementation is particularly elegant. Rather than just ensuring durability, PostgreSQL leverages its WAL for multiple purposes:
Point-in-Time Recovery: By archiving WAL segments, PostgreSQL enables restoration to any moment in the database's history.
Replication: Standby servers receive and replay WAL records to stay synchronized with the primary.
Crash Recovery: After a failure, PostgreSQL uses its checkpoint mechanism alongside WAL replay to restore a consistent state.
What's fascinating is how PostgreSQL tunes its WAL for different workloads. For transaction-heavy systems, the wal_level parameter can be set to 'minimal' to reduce logging overhead. For systems requiring replication, 'replica' or 'logical' settings enable additional information to be written.
The real brilliance appears in parameters like commit_delay and commit_siblings, which allow PostgreSQL to batch WAL flushes when multiple transactions are committing simultaneously—dramatically improving throughput without sacrificing durability.
RocksDB's Manifest Files
Facebook's RocksDB (used by systems like Apache Flink and CockroachDB) takes a different approach. Its WAL is complemented by MANIFEST files that track the evolving state of the database's file structure.
What's notable is how RocksDB implements group commit—batching multiple transactions into a single disk write—achieving up to 10x throughput improvement while maintaining durability guarantees. This technique has allowed RocksDB to handle workloads exceeding 2 million writes per second on a single node.
The Hidden Complexity: Tuning WALs for Performance
What most resources won't tell you is that WAL configuration can make or break system performance. Consider these non-obvious insights:
Write Amplification: Each database write actually produces multiple physical writes (data, WAL, indexes). Properly sized WAL buffers can dramatically reduce this overhead.
Checkpointing Strategy: Aggressive checkpointing reduces recovery time but creates I/O spikes that can stall normal operations. The art lies in finding the right frequency.
Storage Alignment: WAL performance improves significantly when log records align with storage sector boundaries—a detail overlooked by many engineers.
The most common mistake I see teams make is treating WAL as a black box, when in reality, tuning it to your specific workload characteristics can yield 30-40% performance improvements with no application changes.
Practical Implementation
Here's a simplified example of implementing WAL-based recovery in Python:

The true power of this pattern comes from its simplicity—sequential writes providing atomicity and durability with minimal overhead.
What You Should Build
Create a WAL-based key-value store with these features:
Implement basic log record types (SET, DELETE)
Add periodic checkpointing to compact the log
Measure recovery time with different log sizes
Add a simple compaction strategy to prevent unbounded log growth
This exercise will give you hands-on experience with the fundamental mechanism that enables everything from distributed databases to blockchain technologies.
Understanding WALs doesn't just make you a better database developer—it reveals patterns applicable across distributed systems where durability, consistency, and performance must be carefully balanced.
In our next article, we'll explore how LSM trees complement WAL techniques to create highly efficient write-optimized storage engines. Until then, remember: in the realm of data, writing your intentions before acting on them isn't just good manners—it's essential engineering.